







 本文探讨了如何利用pyspark进行数据预处理、特征工程,通过逻辑回归和随机森林模型预测乳腺癌恶性(B)与良性(M)。从身份证号到10个细胞核特征,再到模型训练和评估,展示了信息技术在医学数据分析中的实践。
本文探讨了如何利用pyspark进行数据预处理、特征工程,通过逻辑回归和随机森林模型预测乳腺癌恶性(B)与良性(M)。从身份证号到10个细胞核特征,再到模型训练和评估,展示了信息技术在医学数据分析中的实践。
Data
属性信息:
1) 身份证号码
2) 诊断(M=恶性,B=良性)
计算每个细胞核的10个实值特征:
a) 半径(从中心到周界各点的平均距离)
b) 纹理(灰度值的标准偏差)
c) 周长
d) 面积
e) 平滑度(半径长度的局部变化)
f) 密实度(周长^2/面积-1.0)
g) 凹度(轮廓凹陷部分的严重程度)
h) 凹点(轮廓凹面部分的数量)
i) 对称性
j) 分形维数(“海岸线近似值”-1)
为每个图像计算这些特征平均值、标准差、最大值,产生了30个特征。
| diagnosis | M恶性 B良性 |
| radius_mean | 半径平均值 |
| texture_mean | 纹理平均值 |
| perimeter_mean | 周长平均值 |
| area_mean | 面积平均值 |
| smoothness_mean | 平滑程度平均值 |
| compactness_mean | 紧密度平均值 |
| concavity_mean | 凹度平均值 |
| concave points_mean | 凹缝平均值 |
| symmetry_mean | 对称性平均值 |
| fractal_dimension_mean | 分形维数平均值 |
| radius_se | 半径标准差 |
| texture_se | 纹理标准差 |
| perimeter_se | 周长标准差 |
| area_se | 面积标准差 |
| smoothness_se | 平滑程度标准差 |
| compactness_se | 紧密度标准差 |
| concavity_se | 凹度标准差 |
| concave points_se | 凹缝标准差 |
| symmetry_se | 对称性标准差 |
| fractal_dimension_se | 分形维数标准差 |
| radius_worst | 半径最大值 |
| texture_worst | 纹理最大值 |
| perimeter_worst | 周长最大值 |
| area_worst | 面积最大值 |
| smoothness_worst | 平滑程度最大值 |
| compactness_worst | 紧密度最大值 |
| concavity_worst | 凹度最大值 |
| concave points_worst | 凹缝最大值 |
| symmetry_worst | 对称性最大值 |
| fractal_dimension_worst | 分形维数最大值 |
1.运行pip install pyspark命令安装最新版的pyspark
!pip install pyspark2.导入
需要的包,主要是pyspark.ml等pyspark机器学习包
import os
import pandas as pd
import numpy as np
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession, SQLContext
from pyspark.sql.types import *
import pyspark.sql.functions as F
from pyspark.sql.functions import udf, col
from pyspark.ml.regression import LinearRegression
from pyspark.mllib.evaluation import RegressionMetrics
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, CrossValidatorModel
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.evaluation import RegressionEvaluator3. 创建SparkSession对象以便使用Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[2]").appName("breast-cancer-prediction").getOrCreate()
spark
4.读取数据集
df = spark.read.csv('../input/breast-cancer-wisconsin-data/data.csv',inferSchema=True,header=True)
df.show(3)5.对数据集标签分布情况进行分析
#查看数据集的形状结构,来确定数据集的大小
print((df.count(),len(df.columns)))
#查看数据集的数据类型
df.printSchema()
#describe函数查看数据集的统计指标
df.describe().show(5,False)
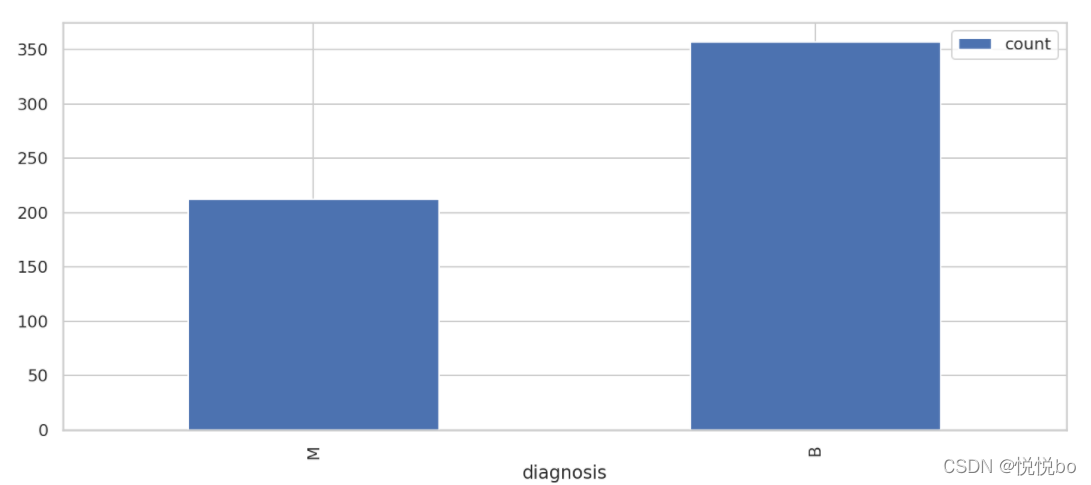
# 按诊断结果分组并查看结果分布
result_df = df.groupBy("diagnosis").count().sort("diagnosis", ascending=False)
result_df.show()
result_df.toPandas().plot.bar(x='diagnosis',figsize=(14, 6))
6.数据清洗
对数据特征分布进行分析,并清洗数据中的缺失值、错误值和异常值
#查看各列空值数量
df_agg = df.agg(*[F.count(F.when(F.isnull(c), c)).alias(c) for c in df.columns])
df_agg.show()
#删除c_32列
df=df.drop('_c32')
#再次查看输入列的数据类型,只有diagnosis为string类型,其他列全为数值型
df.printSchema()
#直接删除含有缺失值的行
#处理重复值
df = df.dropna()
df = df.dropDuplicates()
print((df.count(),len(df.columns)))7.特征工程
from pyspark.ml.linalg import Vector
from pyspark.ml.feature import VectorAssembler
#查看列名
df.columns
#将特征表示为向量形式
vec_assembler = VectorAssembler(inputCols=['radius_mean','texture_mean','perimeter_mean', 'area_mean','smoothness_mean', 'compactness_mean','concavity_mean','concave points_mean','symmetry_mean','fractal_dimension_mean','radius_se','texture_se','perimeter_se','area_se', 'smoothness_se', 'compactness_se', 'concavity_se','concave points_se','symmetry_se', 'fractal_dimension_se', 'radius_worst', 'texture_worst','perimeter_worst', 'area_worst', 'smoothness_worst', 'compactness_worst', 'concavity_worst', 'concave points_worst', 'symmetry_worst','fractal_dimension_worst'],outputCol='features')
features_df = vec_assembler.transform(df)
features_df.printSchema()
features_df.select('features').show(3,truncate=False)
#使用StandardScaler将特征进行初始化,并输出到features_scaled列中
from pyspark.ml.feature import StandardScaler
standardScaler = StandardScaler(inputCol="features", outputCol="features_scaled")
scaled_df = standardScaler.fit(features_df).transform(features_df)
scaled_df.select("features", "features_scaled").show(1, truncate=False)
#将字符型的diagnosis转换为数值型diagnosis_index 值为0,1
from pyspark.ml.feature import StringIndexer
diagnosis_index = StringIndexer(inputCol="diagnosis",outputCol="diagnosis_index").fit(scaled_df)
#查看转换结果,M恶性值为1,B良性值为0
scaled_df = diagnosis_index.transform(scaled_df)
model = scaled_df.select('diagnosis','diagnosis_index')
model.show(20)
8.划分数据集
train_df,test_df = scaled_df.randomSplit([0.8,0.2],seed=rnd_seed)
print((train_df.count(),len(train_df.columns)))
print((test_df.count(),len(test_df.columns)))9.逻辑回归
构造和训练逻辑回归模型
from pyspark.ml.classification import LogisticRegression
from pyspark.ml import Pipeline
log_reg = LogisticRegression().setLabelCol("diagnosis_index").fit(train_df)
train_results = log_reg.evaluate(train_df).predictions
#第0个索引处的概率是diagnosis_index = 0预测的,第1个索引处的概率是diagnosis_index = 1预测的
train_results.filter(train_results['diagnosis_index']==1).filter(train_results['prediction']==1).select(['diagnosis_index','prediction','probability']).show(20,False)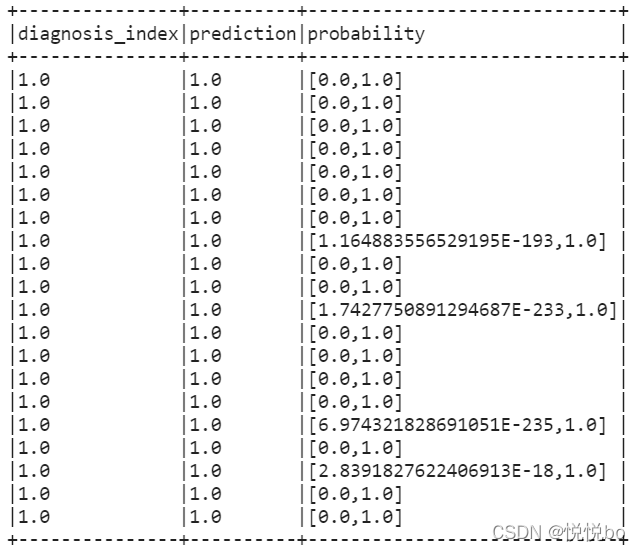
在测试数据上评估逻辑回归模型
results = log_reg.evaluate(test_df).predictions
results.printSchema()
results.select(['diagnosis_index','prediction']).show(20,False)
分类模型评估
1.混淆矩阵(with codes)
混淆矩阵用来表示误差,衡量模型分类效果的一种形式。该矩阵是一个方阵,矩阵的数值用来表示分类器预测的结果,包括正确的正面预测TP 、正面的负面预测TN 、错误的正面预测FP 、错误的负面预测FN
2.评估指标(with codes)
- 正确率(accuracy)
- 精度(precision)
- 召回率(recall)
- F1(调和平均值)
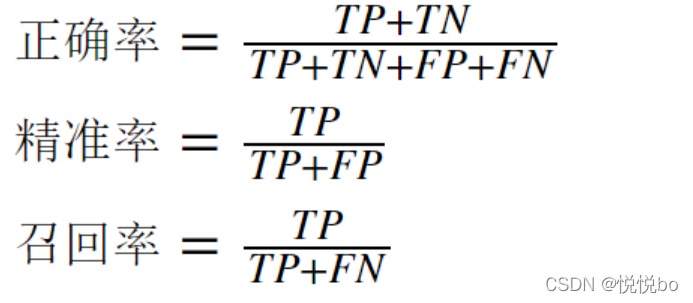
true_postives = results[(results.diagnosis_index == 1) & (results.prediction == 1)].count()
true_negatives = results[(results.diagnosis_index == 0) & (results.prediction == 0)].count()
false_positives = results[(results.diagnosis_index == 0) & (results.prediction == 1)].count()
false_negatives = results[(results.diagnosis_index == 1) & (results.prediction == 0)].count()
#准确率
accuracy=float((true_postives+true_negatives) /(results.count()))
print("accuracy:",accuracy)
#召回率
recall = float(true_postives)/(true_postives + false_negatives)
print("recall:",recall)
#精度
precision = float(true_postives) / (true_postives + false_positives)
print("precision:",precision) 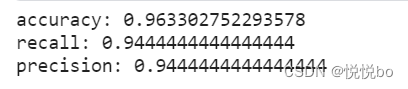
10.随机森林
#构建和训练随机森林
from pyspark.ml.classification import RandomForestClassifier
rf_classifier = RandomForestClassifier(labelCol='diagnosis_index',numTrees=50).fit(train_df)
#基于测试数据进行评估
rf_predictions = rf_classifier.transform(test_df)
model = rf_predictions.select('diagnosis_index','prediction','probability')
model.show(10) 
评估
#评估
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.evaluation import BinaryClassificationEvaluator
#计算准确率
rf_accuracy = MulticlassClassificationEvaluator(predictionCol="prediction",labelCol='diagnosis_index',metricName='accuracy').evaluate(rf_predictions)
print('The accuracy of RF on test data is {0:.0%}'.format(rf_accuracy))
#计算精度
rf_precision = MulticlassClassificationEvaluator(labelCol='diagnosis_index',metricName='weightedPrecision').evaluate(rf_predictions)
print('The precision rate of RF on test data is {0:.0%}'.format(rf_precision)) 
AUC: AUC(Area Under the Curve)是指ROC曲线下的面积,使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
#AUC ROC曲线下的面积
from pyspark.ml.evaluation import BinaryClassificationEvaluator
rf_auc = BinaryClassificationEvaluator(labelCol='diagnosis_index').evaluate(rf_predictions)
print(rf_auc)![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









