







知识框架
No.0 时空权衡
一、基本思想
其实时空权衡:是指在算法的设计中,对算法的时间和空间作出权衡。
本文主要是是用空间来换时间的。(应该是这样吧)
- 对问题的部分或全部输入做预处理,然后对获得的额外信息进行存储,以加速后面问题的求解——输入增强。
- 使用额外空间来实现更快和(或)更方便的数据存取——预构造。(感觉像是存放脑信息)
以常见的以空间换取时间的方法有:主要是两个方法:然后代表。
- 输入增强
- 计数排序
- 字符串匹配中的输入增强技术
- 预构造
- 散列法
- B树
那面是计数排序和散列法的详细介绍:
No.1 计数排序
一、比较计数
针对待排序列表中的每个元素,算出列表中小于该元素的元素个数,并把结果记录在一张表中。
- 这个“个数”指出了元素在有序列表中的位置(小于的个数也差不多就是前面有几个咯)
- 可以用这个信息对列表的元素排序,这个算法称为“比较计数”
步骤:思路:针对待排序列表中的每一个元素,算出列表中小于该元素的元素个数,把结果记录在一张表中。
拿数组中的62来说,比之小的有3个,那么其就在数组的3位置;。
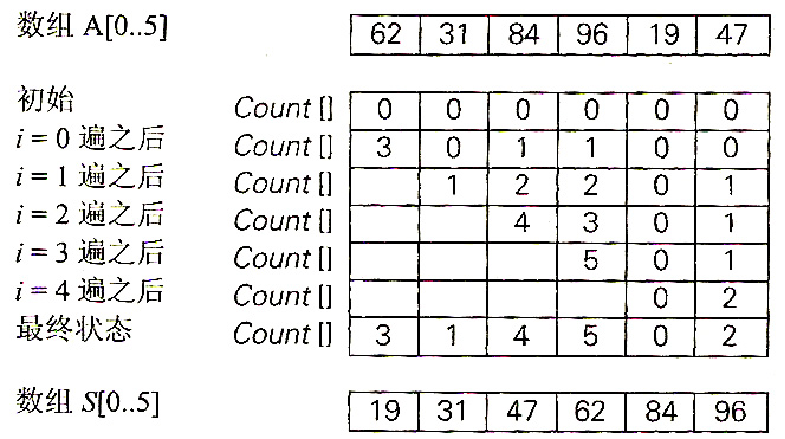
代码如下:
{ //用比较计数法对数组排序
for(i=0;i < n;i++) Count[i]=0;
for(i=0;i < n-1;i++)
for(j=i+1;j < n; j++)
if(A[i]<A[j]) Count[j]++;
else Count[i]++;
for(i=0;i < n;i++) S[Count[i]] = A[i];
return S;
}
复杂度效率问题:O(n^2)
- 该算法执行的键值比较次数和选择排序一样多,
- 并且还占用了线性数量的额外空间,所以几乎不能来做实际的应用
- 但在一种情况下还是卓有成效的——待排序的元素值来自一个已知的小集合
1.
二、分布计数
分布计数是一种特殊方法,用来对元素取值来自于一个小集合的列表排序。
待排序的数组元素有一些其他信息和键值相关(不能改写列表的元素)
因为这种频率的累积和在统计中称为分布,这个方法也称为“分布计数”。
这是一个线性的算法,它的时间效率类型比合并排序、快速排序、堆排序等基于比较的排序算法都要好。
由于分布计数排序要使用一个额外的数组D,而数组D的长度取决于待排序数组中数据的范围,
因此分布计数排序对于数据范围很大的数组,需要大量的内存。
- 将A数组元素复制到一个新数组S[0…n-1]中
- A中元素的值如果等于最小的值L,就被复制到S的前D[0]个元素中,即位置0到D[0]-1中
- 值等于L+1的元素被复制到位置D[0]至(D[0]+D[1])-1,以此类推。
步骤:
-
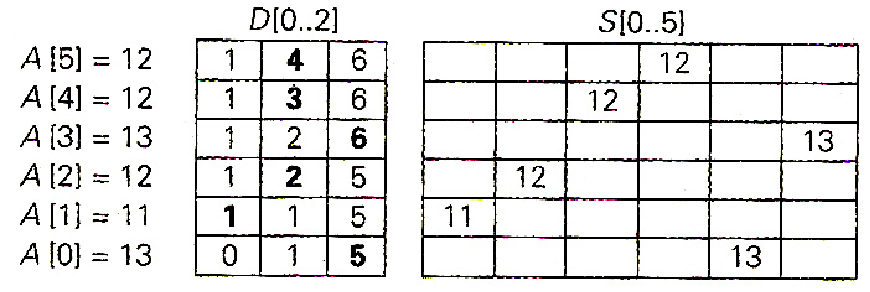
比如数据是: 13 11 12 13 12 12 它们的值从11到13,因此需要一个额外的数组D[0…2],用来存放分布值。
-
首先需要整理表格内容:首先计算出频率值,就是每个元素重复的次数。
-
然后计算出分布值,分布值指出了在最后的有序数组中,它们的元素最后一次出现时的正确位置。
-
如果从0到n-1建立数组下标,为了得到相应的元素位置,分布值必须减1。当然表格里面的分布值还是没有-1的。
-
分布值表示的是最后一次出现的正确位置,11的个数是一个,因为11是第一个元素,那么11的分布值就等于频率。12的个数有三个,那么它最后出现的位置就是它前面一个数的分布值加上自己出现的频率,也就是3+1=4。而13的分布值就等于12的分布值加上自己出现的频率,就是4+2=6。
-
数组值 11 12 13 频率 1 3 2 分布值 1 4 6
-
-
得到分布值后,就可以对下面的数组进行排序了,为方便处理,我们从数组的最后一个元素开始。
-
最后的值是12,而它的分布值是4,我们就把这个12放在数组S的第4个位置上,也就是S[3],(数组从0开始编号)。然后把12的分布值减1,代表下次再遇到12,就只能放在第三个位置上面了。依次类推。得到下面的内容。
-
然后处理数组的下一个元素(从右边数),再碰到12,此时12的分布值是3,于是把12放到S的第3个位置上,再将分布值减1。
-
接着遇到的13,它的分布值是6,于是将13放在数组S的最后一个位置,再将分布值减1.
-
直到循环n次后,算法结束,排序完成
-
得到这样的内容
代码:
{ //分布计数法对有限范围整数的数组排序
for(j=0;j <= u-L ;++i) D[j]=0;//初始化频率数组
for(i=0;i < n; ++i) D[A[i]-L]++;//计算频率值
for(j=1;j <= u-L ; ++j) D[j]+=D[j-1];//重用分布
for(i=n-1;i>=0;--i){
j = A[i] – L ;
S[D[j]-1] = A[i];
D[j]--;
}
return S;
}
效率分析
- 假设数组值的范围是固定的,那么这是一个线性效率的算法
- 但重点是:除了空间换时间之外,分布技术排序的这种高效是因为利用了输入列表独特的自然属性!
No.2 散列法
散列是一种非常高效的实现字典的方法,分为开散列和闭散列,其中必须采用碰撞解决机制。
-
一种非常高效的实现字典的方法
- 字典是一种抽象数据类型,即一个在其元素上定义了查找、插入和删除操作的元素集合
- 集合的元素可以是容易类型的,一般为记录
-
散列法的基本思想是:把键分布在一个称为散列表的一维数组H[0…m-1]中。
- 可以通过对每个键计算某些被称为“散列函数”的预定义函数h的值,来完成这种发布
- 该函数为每个键指定一个称为“散列地址”的位于0到m-1之间的整数
-
散列函数:散列函数需要满足两个要求:
-
散列函数需要把键在散列表的单元格中尽可能均匀地分布(所以m常被选定为质数,甚至必须考虑键的所有比特位)
-
散列函数必须容易计算
-
散列的主要版本:
- 开散列(分离链)
- 闭散列(开式寻址)
一、开散列(分离链)
- 键被存储在附着于散列表单元格上的链表中,散列地址相同的记录存放于同一单链表中。
- 查找时:首先根据键值求出散列地址,然后在该地址所在的单链表中搜索;
查找效率分析:
- 查找效率取决于链表的长度,
- 而这个长度又取决于字典和散列表的长度以及散列函数的质量(双方的长度和散列函数的选取)
- 若散列函数大致均匀地将n个键分布在散列表的m个单元格中,每个链表的长度大约相当于n/m个
- 比率α=n/m称为散列表的负载因子
- 一般我们希望负载因子不要和1差太远。
- 如果太小就意味着有很多空链表;如果太大就使链表太长;
- 如果和1相差无几的话就能到达惊人的效率:平均只要一两次比较就能完成查找
- 成功查找和不成功查找中平均需检查的个数S和U:S≈1+α/2;U=α;
- 之所以能得到这样卓越的效率,不仅是因为这个方法本身就非常精巧,而且也是以额外的空间为代价的
- 插入和删除在平均情况下都是属于Θ(1)
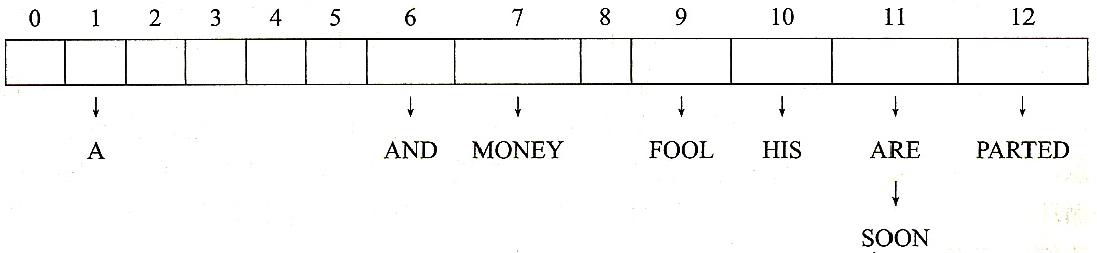
形式展示:在开散列中,键被存放于散列表单元的链表中。
比如:如下的键值A,FOOL,AND,HIS,MONEY,ARE,SOON,PARTED
| 键 | A | FOOL | AND | HIS | MONEY | ARE | SOON | PARTED |
|---|---|---|---|---|---|---|---|---|
| 散列地址 | 1 | 9 | 6 | 10 | 7 | 11 | 11 | 12 |
二、闭散列(开式寻址)
如下:
- 所有的键值都存储在散列表本身中,而没有使用链表(这表示表的长度m至少必须和键的数量一样大)
- 解决碰撞:有多种方法,例如线性探测
- 插入和查找:简单而直接
- 删除操作:“延迟删除”,用一个特殊的符号来标记曾被占用过的位置,以把它们和那些从未被只用过的位置区别开来
- 成功查找和不成功查找中平均需检查的个数S和U:S≈(1+1/(1-α))/2;U=(1+1/();
- 解决冲突:
形式展示:在闭散列中,所有键都存储在散列表本身,
采用线性探查解决冲突,即碰撞发生时,如果下一个单元格空,则放下一个单元格,如果不空,则继续找到下一个空的单元格,如果到了表尾,则返回到表首继续。
比如:如下的键值A,FOOL,AND,HIS,MONEY,ARE,SOON,PARTED
| 键 | A | FOOL | AND | HIS | MONEY | ARE | SOON | PARTED |
|---|---|---|---|---|---|---|---|---|
| 散列地址 | 1 | 9 | 6 | 10 | 7 | 11 | 11 | 12 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | FOOL | |||||||||||
| A | FOOL | |||||||||||
| A | AND | FOOL | HIS | |||||||||
| A | AND | FOOL | HIS | |||||||||
| A | AND | MONEY | FOOL | HIS | ||||||||
| A | AND | MONEY | FOOL | HIS | ARE | |||||||
| A | AND | MONEY | FOOL | HIS | ARE | SOON | ||||||
| PAETED | A | AND | MONEY | FOOL | HIS | ARE | SOON |
闭散列的查找和插入操作是简单而直接的,但是删除操作则会带来不利的后果。
比起分离链,线性探查的数学分析是复杂得多的问题。
对于复杂因子为α的散列表,成功查找和不成功查找必须要访问的次数分别为:
S≈ (1+1/(1- α))/2 U ≈(1+1/(1- α)2)/2
散列表的规模越大,该近似值越精确
















 2260
2260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









