







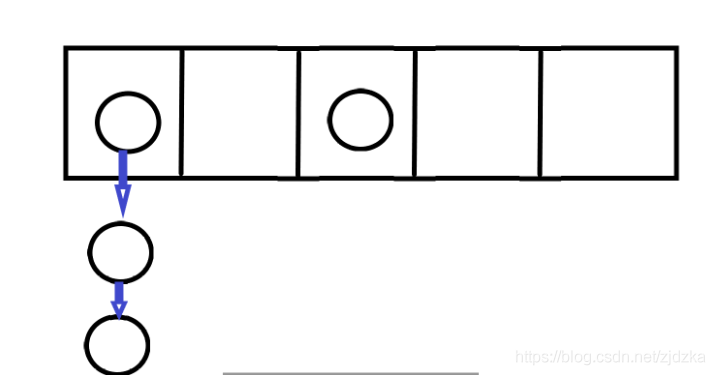
一、散列表结构
散列表结构就是数组+链表的结构
二、什么是哈希?
Hash也称散列、哈希,对应的英文单词Hash,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出
这个映射的规则就是对应的哈希算法,而原始数据映射后的二进制就是哈希值
Java并发编程学习笔记,关注公众号:程序员追风,回复 013 领取422页PDF文档
不同的数据它对应的哈希码值是不一样的
哈希算法的效率非常高
三、HashMap原理讲解
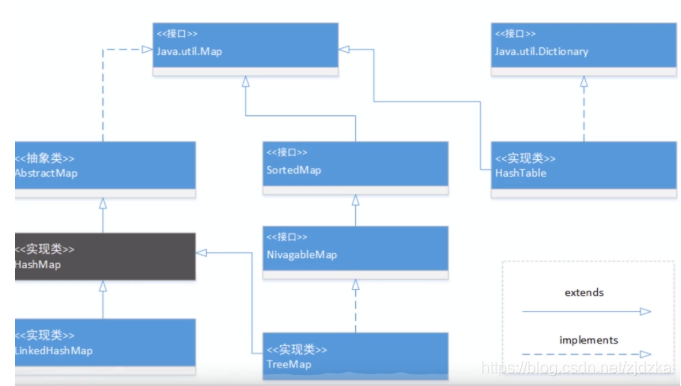
3.1、继承体系图
3.2、Node数据结构分析
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;计算得到哈希值
final K key;
V value;
Node<K,V> next;
}
interface Entry<K, V> {
K getKey();
V getValue();
V setValue(V value);
3.3、底层存储结构
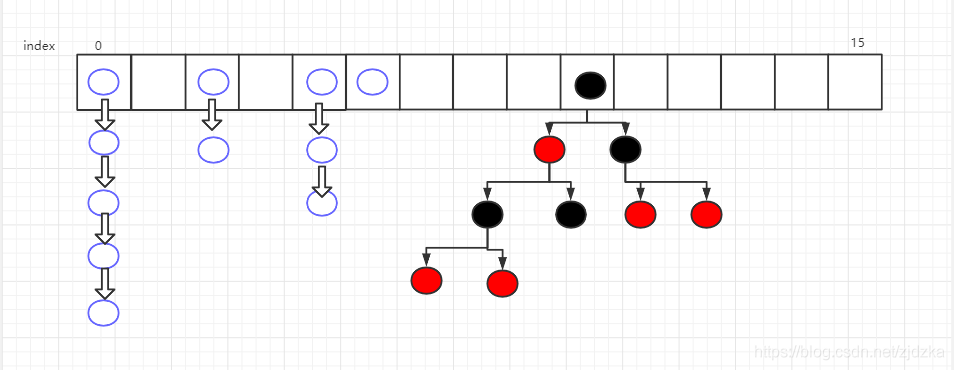
当链表长度到达8时,升级成红黑树结构
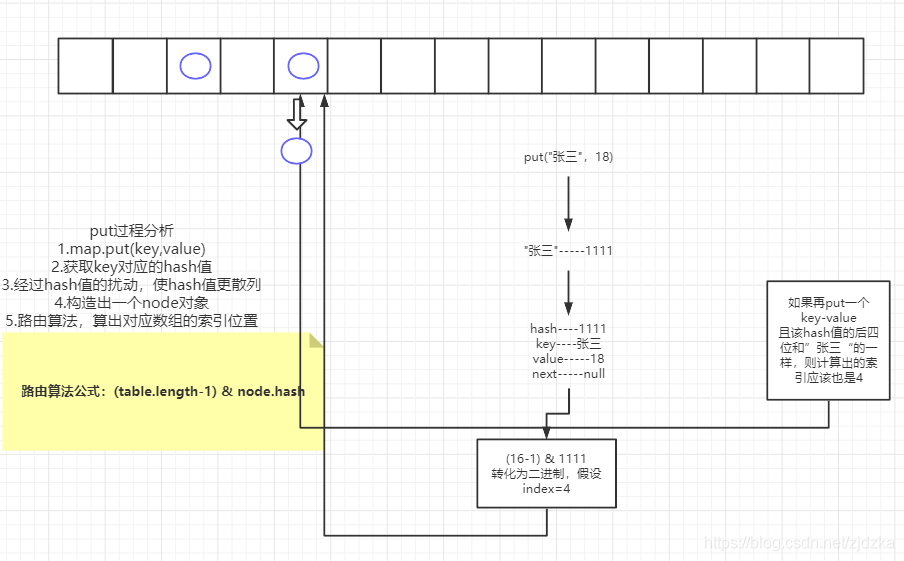
3.4、put数据原理分析
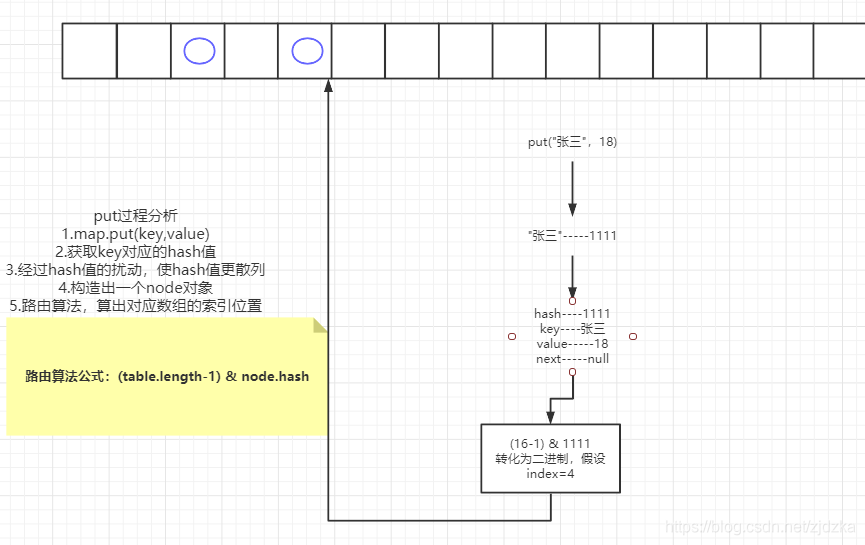
首先put进去一个key----value
根据key值会计算出一个hash值
经过扰动使数据更散列
构造出一个node对象
最后在通过路由算法得出一个对应的index
3.5、什么是哈希碰撞?
当传入的数据key对应计算出的hash值的后四位和上一个一样时,这时候计算出的index就会一致,就会发生碰撞,导致数据变成链表
例如:
(16-1)------->0000 0000 0000 1111
“张三”------->0100 1101 0001 1011
“李四”-------->1011 1010 0010 1011
此时,就会发现,张三和李四计算出的hash值转化为二进制的后四位一致,导致计算出index一致
3.6、JDK8为什么引入红黑树?
哈希碰撞,会带来链化,效率会变低
引入红黑树会提高查找效率
3.7、扩容机制
每次扩容为初始容量的2倍
eg:16------->32
为了防止数据过多,导致线性查询,效率变低,扩容使得桶数变多,每条链上数据变少,查询更快
四、手撕源码
##4.1、HashMap核心属性分析
树化阈值-----8和64
负载因子0.75
threshold扩容阈值,当哈希表中的元素超过阈值时,触发扩容
loadFactory负载因子0.75,去计算阈值 eg:16*0.75
size-------当前哈希表中元素个数
modCount--------当前哈希表结构修改次数
##4.2、构造方法分析
public HashMap(int initialCapacity, float loadFactor) {
//校验 小于0报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//capacity大于最大值取最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子不能小于等于0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//tableSizeFor方法
this.threshold = tableSizeFor(initialCapacity);
}
---------------------------------------------------------
//传入一个初始容量,默认负载因子0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
---------------------------------------------------------
//无参数,负载因子默认0.75
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









