








😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主。公粽号:洲与AI。
🤓 欢迎大家关注我的专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。
🌼 同时洲洲已经建立了程序员技术交流群,如果您感兴趣,可以私信我加入我的社群~社群中将不定时分享各类福利
🖥 随时欢迎您跟我沟通,一起交流,一起成长、进步!点此即可获得联系方式~
前言:Kmeas聚类介绍
数据科学领域中,聚类是一种无监督学习方法,它旨在将数据集中的样本划分成若干个组,使得同一组内的样本相似度高,而不同组之间的样本相似度低。K-means聚类是其中最流行的一种算法,因其简单、高效而广受青睐。然而,选择合适的K值(即聚类数)对于聚类结果至关重要。本文将探讨如何选取最优的K值,以确保K-means聚类算法能够揭示数据中的潜在模式。
K-means聚类算法通过迭代过程将数据集划分为K个簇。每个簇由一个质心(即簇内所有点的均值点)表示。算法的目标是最小化簇内误差平方和(Within-Cluster Sum of Squares, WCSS),即簇内所有点到质心的距离平方和。
K-means聚类的一个主要挑战在于确定最优的K值。如果K值太小,可能会导致过拟合,即簇内样本过于紧密,无法捕捉数据的多样性;如果K值太大,可能会导致欠拟合,即簇内样本过于分散,失去了聚类的意义。
接下来我们介绍一些确定最优K值的方法。
一、肘部法则(Elbow Method)
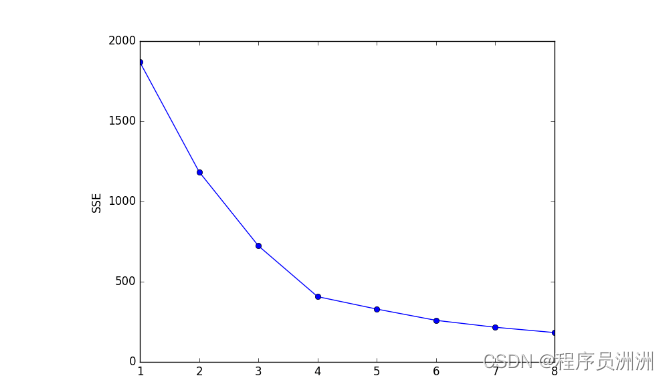
肘部法则是一种直观的方法,通过绘制WCSS与K值的关系图来确定最优K值。随着K值的增加,WCSS通常会下降,然后在某个点之后下降速度会显著减慢,形成一个“肘部”。这个点通常被认为是最优K值。
手肘法的核心指标是SSE(sum of the squared errors,误差平方和),

手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。
对预处理后数据.csv 中的数据利用手肘法选取最佳聚类数k。
具体做法是让k从1开始取值直到取到你认为合适的上限(一般来说这个上限不会太大,这里我们选取上限为8),对每一个k值进行聚类并且记下对于的SSE,然后画出k和SSE的关系图(毫无疑问是手肘
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
df_features = pd.read_csv(r'C:\预处理后数据.csv',encoding='gbk') # 读入数据
'利用SSE选择k'
SSE = [] # 存放每次结果的误差平方和
for k in range(1,9):
estimator = KMeans(n_clusters=k) # 构造聚类器
estimator.fit(df_features[['R','F','M']])
SSE.append(estimator.inertia_)
X = range(1,9)
plt.xlabel('k')
plt.ylabel('SSE')
plt.plot(X,SSE,'o-')
plt.show()
二、轮廓系数法
轮廓系数是一种评估样本聚类质量的指标,它综合考虑了样本与其簇内其他样本的距离以及与最近簇样本的距离。轮廓系数的值范围在-1到1之间,值越大表示样本聚类效果越好。
轮廓系数由以下两部分组成:
- 簇内凝聚度(a):对于每个样本点,它计算了该样本与其簇内所有其他样本的平均距离。
- 簇间分离度(b):对于每个样本点,它计算了该样本与最近簇中所有样本的平均距离。

接下来我们可以用Python实现轮廓系数法:
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成模拟数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 计算不同K值的轮廓系数
silhouette_scores = []
K_max = 15
for k in range(2, K_max):
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(X)
score = silhouette_score(X, kmeans.labels_)
silhouette_scores.append(score)
# 绘制轮廓系数与K值的关系图
plt.plot(range(2, K_max), silhouette_scores, marker='o')
plt.title('Silhouette Coefficients')
plt.xlabel('Number of clusters')
plt.ylabel('Average silhouette score')
plt.show()
三、Gap统计量
Gap统计量基于以下假设:如果聚类是有意义的,那么数据集中的样本点应该比随机数据更紧密地聚集在一起。因此,Gap统计量计算了实际数据集的WCSS与随机数据集WCSS的期望值之间的差异。

from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from scipy.spatial.distance import cdist
import numpy as np
# 生成模拟数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 定义函数来计算WCSS
def compute_wcss(X, kmeans):
kmeans.fit(X)
return kmeans.inertia_
# 定义函数来计算Gap统计量
def calculate_gap(X, K_range, B=10):
gaps = []
for k in K_range:
kmeans = KMeans(n_clusters=k, init='k-means++', random_state=0)
wcss_actual = compute_wcss(X, kmeans)
wcss_reference = []
for _ in range(B):
X_reference = np.random.rand(X.shape[0], X.shape[1])
kmeans_reference = KMeans(n_clusters=k, init='k-means++', random_state=0)
wcss_reference.append(compute_wcss(X_reference, kmeans_reference))
wcss_reference_mean = np.mean(wcss_reference)
gap = np.log(wcss_actual) - np.log(wcss_reference_mean)
gaps.append(gap)
return gaps
# 计算Gap统计量
K_range = range(2, 15)
gaps = calculate_gap(X, K_range)
# 选择最优K值
optimal_K = np.argmax(gaps) + 2 # 加2是因为K_range从2开始
print(f"Optimal number of clusters (K): {optimal_K}")
四、交叉验证方法
交叉验证聚类的基本思想是将数据集分成多个部分,然后在一个部分上进行聚类,同时在其他部分上评估聚类的质量。这可以通过轮廓系数或其他聚类质量指标来实现。
交叉验证聚类没有特定的公式,但通常包括以下步骤:
1、将数据集分成K个子集。
2、对于每个子集,执行以下操作:
在剩余的K-1个子集上训练K-means聚类模型。
在当前子集上计算聚类质量指标(如轮廓系数)。
3、计算所有子集的平均聚类质量指标。
4、选择使平均聚类质量指标最高的K值。
from sklearn.cluster import KMeans
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import silhouette_score
from sklearn.datasets import make_blobs
import numpy as np
# 生成模拟数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 定义交叉验证函数
def cross_validate_clustering(X, K_range, n_splits=5):
silhouette_scores = []
skf = StratifiedKFold(n_splits=n_splits)
for k in K_range:
score = 0
for train_index, test_index in skf.split(X, X):
X_train, X_test = X[train_index], X[test_index]
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(X_train)
score += silhouette_score(X_test, kmeans.labels_)
silhouette_scores.append(score / n_splits)
return silhouette_scores
# 计算交叉验证轮廓系数
K_range = range(2, 15)
scores = cross_validate_clustering(X, K_range)
# 选择最优K值
optimal_K = np.argmax(scores) + 2 # 加2是因为K_range从2开始
print(f"Optimal number of clusters (K): {optimal_K}")



















 6552
6552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











