






1.字符串编码
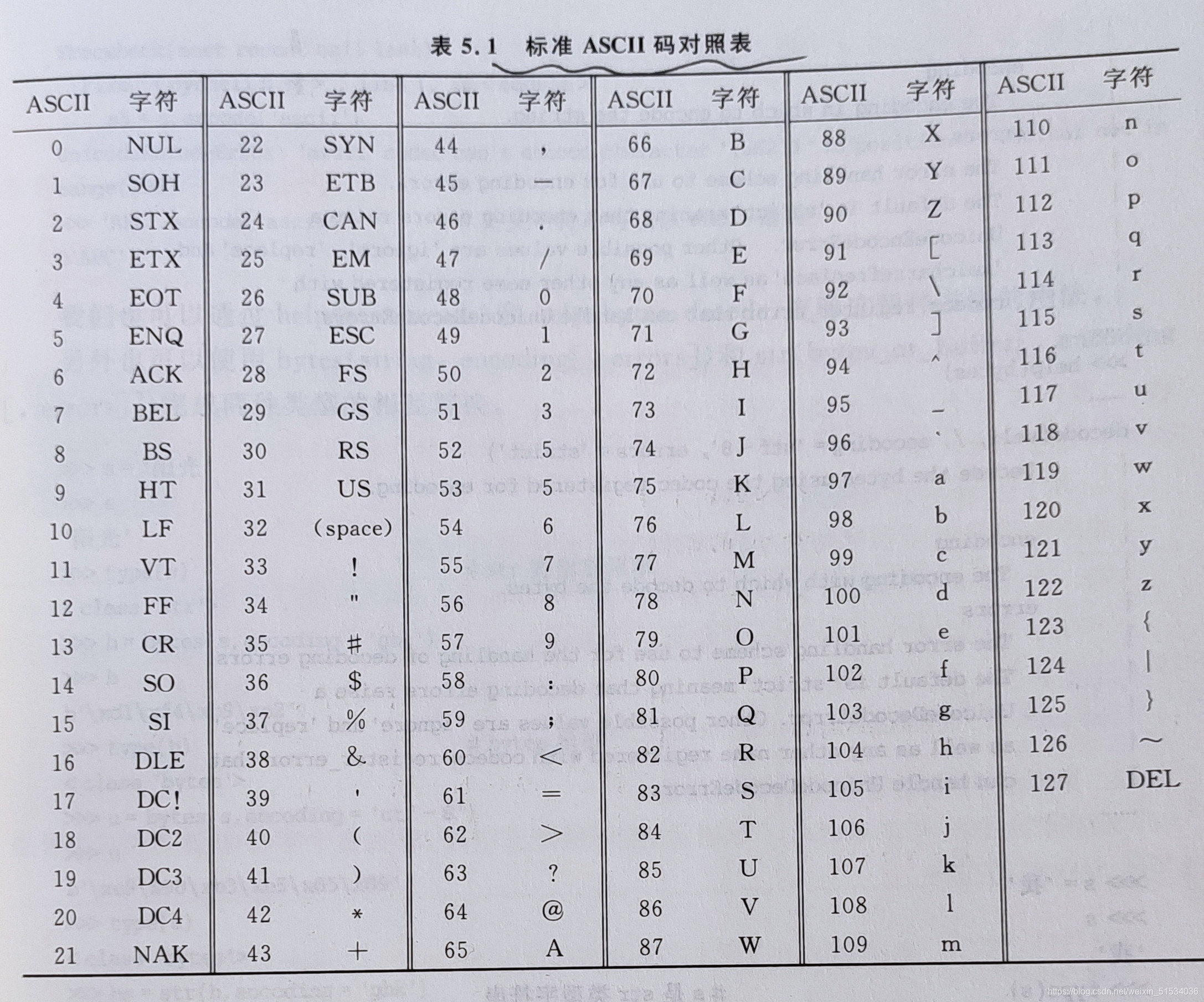
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套计算机编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC646。
ASCII码使用指定的7位或8位二进制数组合来表示128或256种可能的字符。标准ASCII码也叫基础ASCII码,使用7位二进制数(剩下的最高位为二进制0)来表示所有的大写和小写字母、数字0到9、标点符号,以及在美式英语中使用的特殊控制字符。128到255为扩展ASCII。
标准ASCII与字符的对照表如下表所示。
但是不同国家有不同的语言,也就有不同的编码。中国制定了GB2312编码,日本制定了Shift_JIS编码,韩国制定了Euc-kr编码,而不同的编码格式之间差别很大,如果一篇文章既有英文,又有中文,还有日文,则无论采用哪个国家的编码,都会出现乱码。
Unicode编码把所有语言都统一到一套编码里,这样就不会再有乱码问题了。最常用的Unicode编码是用2字节表示一个字符(如果要用到非常偏僻的字符,就需要4字节)。采用Unicode编码,乱码问题是没有了,但新的问题又出来了,如果有一篇文章全是英文的话,用Unicode 编码比ASCII编码需要多一倍的存储空间,这样既浪费存储空间又影响传输速度。后来又出现了UTF-8编码。
UTF-8编码是“可变长编码”,它可以使用1~4字节表示一个符号,根据不同的符号而变化字节长度。UTF-8编码以一字节表示英语字符(兼容ASCII),以3字节表示中文,还有一些语言使用2字节或4字节。注意:Unicode编码中一个中文字符占2字节,而UTF-8编码中一个中文字符占3字节。从Unicode到UTF-8并不是直接对应,而是要经过一些算法和规则来转换的。GB2312是我国制定的中文编码,GBK是对GB2312的扩充,CP936是微软公司在GBK基础上开发的Windows下的中文编码方式。这些编码均使用2字节表示中文。Python3支持两种类型字符串:str类型(支持U
第五章 字符串与正则表达式
最新推荐文章于 2023-01-06 13:49:22 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









