









ElasticSearch原理,应用以及仿京东搜索功能
1.ElasticSearch简介
ElasticSearch:智能搜索,分布式的搜索引擎
是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
E:ElasticSearch搜索和分析的功能
L:Logstach收集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
K:Kibana数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台

分析日志的用处:假如一个分布式系统又1000台机器,系统出现故障时,我要看一下日志,还得一台一台登录上去查看,很麻烦。
但是如果日志接入了ELK系统就不一样了。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入ELK系统中,我们直接在Kibana就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。
这都依赖与ES强大的反向索引功能,这样我们根据关键字就能查询到关键的错误日志了。
1.1 什么是全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
1.2 什么是倒排索引
以前是根据ID查内容,倒排索引之后是根据内容查ID,然后再拿着ID去查询出来真正需要的东西。

1.3 什么是Lucene
Luncene就是一个jar包,里面包含了各种建立倒排索引的方法,Java开发的时候只需要导入这个jar包就可以开发了。
ES和Lucene的区别
Lucene不是分布式的。
ES的底层就是Lucene,ES是分布式的
为什么不用数据库去实现搜索功能?
用数据库实现搜索功能时:1、需要全表扫描。2、字段里面的所有内容都需要去匹配。3、全文检索。性能上会很差。
已搜索牙膏商品为例

1.4 ES的优点
- 分布式的功能
- 数据高可用,集群高可用。
- API更简单
- API更高级
- 支持的语言特别多。
- 支持PB级别的数据。
- 完成搜索的功能和分析功能。
基于Lucene,隐藏了Lucene的复杂性,提供简单的API
ES的性能比HBase高,咱们的竞价引擎最后还是要存到ES中的。
1.5 搜索引擎原理
- 反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
- 搜索引擎原理就是建立反向索引。
- Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。
- Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。
- Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。
- Elasticsearch 一个典型应用就是 ELK 日志分析系统。
1.6 ES的核心概念
1. NRT(Near Realtime)近实时

2. cluster集群,ES是一个分布式的系统
ES直接解压不需要的配置就可以使用,在hadoop1上解压一个ES,在hadoop2上解压了一个ES,接下来把这两个ES启动起来。他们就构成了一个集群。
在ES里面默认有一个配置,clustername默认值就是ElasticSearch,如果这个值是一样的就属于同一个集群,不一样的值就是不一样的集群。
3. Node节点,就是集群中的一台服务器
4. index索引(索引库)
我们为什么使用ES?因为想把数据存进去,然后查询出来。
我们在使用MySQL 或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。
其实ES功能就像一个关系型数据库,在这个数据库我们可以往里面添加数据,查询数据。
ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇
index类似于我们MySQL里面的一个数据库create database user;好比就是一个索引库
5. type类型
类型是用来定义数据结构的
在每一个index下面,可以有一个或者多个type,好比数据库里面的一张表。
相当于表结构的描述,描述每个字段的类型。
6. document:文档
文档就是最终的数据了,可以认为一个文档 就是一条记录。
在ES里面最小的数据单元,就好比表里面的一条数据。
7. Field字段
好比关系型数据库中列的概念,一个document有一个或者多个field组成。
例如:
朝阳区:一个Mysql数据库
房子:create database chaoyanginfo
房间:create table people
8. shard:分片
一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
kafka:为什么支持分布式的功能,因为里面是由topic,支持分区的的概念。所以topic A可以存在不同的节点上面。就可以支持海量数据和高并发,提升性能和吞吐量。
9. replica:副本
一个分布式的集群,难免会有一台或者多台服务器宕机,如果我们没有副本这个概念。就会造成我们的shard发生故障,无法提供正常服务。
我们为了保证数据的安全,我们引入replica的概念,跟hdfs里面的概念是一个意思。
可以保证我们数据的安全。
在ES集群中,我们一摸一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,他会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
总结:
在默认情况下,我们创建一个库的时候,默认会帮我们创建5个主分片(primary shrad)和5个副分片(replica shard),所以说正常情况下是有10个分片的。
同一个节点上面,副本和主分片是一定不会再一台机器上的。就是拥有相同数据的分片,是不会在同一个节点上面的。
所以当你有一个节点的时候,这个分片是不会把副本存在这仅有的一个节点上的,当你新加入了一台节点,ES会自动的给你在新机器上创建一个之前分片的副本。

10. 举例
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫Poems的索引,然后创建一个名叫Poem的类型,类型是通过Mapping来定义每个字段的类型。
比如诗题、作者、朝代都是Keyword类型,诗内容是Text类型,而数字是Integer类型,最后就是把数据组织成Json格式存放进去了。

Keyword类型是不会分词的,直接根据字符串内容建立反向索引,Text类型在存入Elasticsearch的时候,会先分词,然后根据分词后的内容建立反向索引。

2.ES的分布式原理
Elasticsearch也是会对数据进行切分,同时每一个分片会保存多个副本,其原因和HDFS是一样的,都是为了保证分布式环境下的高可用。
绿色部分的表示数据块,其实elasticsearch中数据块也是备份存储至多个节点中的。
在Elasticsearch中,是master-slave架构。节点是对等的,节点间会通过自己的一些规则选取集群的Master,Master会负责集群状态信息的改变,并同步给其它节点。
创建索引的请求先发到master,master建立完索引后,将集群状态同步到slave。
这样写入性能会不会很低???注意,只有建立索引和类型需要经过Master,数据的写入有一个简单的Routing规则,可以Route到集群中的任意节点,所以数据写入压力是分散在整个集群的。
3. ES相关命令
3.1 ES的增删改查
PUT 类似于SQL中的增
DELETE 类似于SQL中的删
POST 类似于SQL中的改
GET 类似于SQL中的查
3.2 index操作
PUT /aura_index 增加一个aura_index的index库

GET _cat/indices 查询ES中所有的index索引库

5:代表primary shard(分片)的个数
1:代表的是replica shard(副片)的个数是5,因为副本数为1代表有5个副分片,注意这个地方说的1不是包括自己本身的,我们的HDFS block3代表的是包括本身的
DELETE /aura_index 删除一个aura_index的index库

3.3 ES的隐藏性
ES是一个分布式的系统,里面我们在使用的时候隐藏了复杂的分布式的机制。
(1)分片机制
插入数据的时候不是根据负载均衡来插入的,是根据一定的路由规则。
我们在创建一个index库的时候,我们可以指定primary shard(分片)的数量,也可以指定replica(副片)的数量,如果不指定,那么默认primary shard=5(分片),replica=1(副片),所以replica shard=5,过了一段时间发现数据量很大,我们primary shard不够用了,那么这个时候想修改shard 的个数,能不能改成20个? 答案 不能!!!原来本应该插入到8的位置,结果插入到了9的位置,这样计算查询规则就错了。所以主分片个数是不能修改的,但是副分片的个数是可以进行修改的。具体怎么完成的那是ES内部的事情,我们先不用考虑。我们写了段java的代码插入数据到主分片里面去了。具体怎么插入的,插入到哪个主分片里面是不需要我们来管的。所以就是把这些功能给隐藏起来了。
如果真的遇见了这样的事,再建一个库,那个库的分片是20,用代码查询出来再导入到这个库中,只能用这个方法
总结:我们操作的时候很轻松的就把数据存入到我们的ES里面了。存入的时候我们并不关心,数据存到哪个分片里面去。
(2)集群的发现机制
我们做过一个实验,一开始我们只启动了一个ES的节点,这个时候这个ES的状态是yellow,后来我们又启动了一个ES节点,发现颜色变成了green,这说明,我们后面启动的这个节点,也自动加入了这个集群。那么这个机制就是集群的发现机制。对于我们也是隐藏起来了。我们没必要知道
(3)shard 会进行负载均衡
Hbase中如果你新加入了一个Hbase节点,不会自动的进行负载均衡,需要执行一个命令但是ES不一样。只要你加入了一个节点,会自动帮你进行负载均衡
3.4 ES集群的库容问题
扩容分为:垂直和水平扩容
我们之前的大数据技术都是分布式的部署在集群上面的。如果我们的资源不够用了,这个时候就涉及到了扩容,我们是垂直扩容还是水平扩容呢?
假设我们每个节点能存储1T的数据,现在我们要存储5T的数据,
垂直扩容就是把其中的一台换了,换成性能更强的节点。有可能一台节点就能存5T。
水平扩容就是新加服务器直到能存下来5T的数据,我们一般都是用水平扩容,比如1T是1万。5台5万,但是单台5T的价钱可能是50万。所以我们几乎不太可能用这种方式。
但是可能那么namenode节点可能是采用垂直扩容
3.4 ES的primary shard和replica shard
1)index可以包含多个type,同样一个index下面也可以有多个shard
2)在ES里面每个shard就是最小的一个工作单元,承载了部分数据
3)如果在ES集群里面增加或减少节点,shard会自动的实现负载均衡
4)primary shard乐意进行读和写,replica shard负责读
5)primary shard在创建index的时候就固定了,不能修改了。
6)默认创建一个index的时候,primary shard的数量是5,replica的数量是1,也就是说默认情况下有10个shard,其中有5个primary shard,5个是replica shard
7)primary shard和自己的replica shard是不能在同一台服务器上的。
3.5 ES的容错机制
1)master的选举
2)replica的容错
3)数据恢复

3.6 自动生成id号
指定ID号的方式


自动生成ID号


3.7 version之悲观锁和乐观锁

悲观锁:很悲观,自己操作的时候别的线程就不能进行操作。所以在电商的情况下体验性很不好,但是不容易出错。
乐观锁:很乐观,因为现在剩3件了,假设version号是5,A,B线程同时进行访问操作,AB线程拿到的都是3件,version都是5,A线程先购买了一件就是3-1=2 ,然后A线程拿着2和version号5去更新数据,发现version是5就把3件更新为2件,同时version变成了6;然后B线程买了一件就是3-1=2 然后拿着2和version号5去更新,发现version号不匹配,此时重新获取一下version号和仅剩的件数2,然后2-1=1,然后拿着1和version号6去更新数据,发现version对上了。此时更新成功。
2.ElasticSearch的应用
注意搭建springboot集成es项目时的版本号。需要找到相互适配的。
pom.xml
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.10.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
<scope>provided</scope>
</dependency>
2.1 测试连接
package com.pan;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
/**
* @PackageName: com.pan
* @ClassName: TestDemo
* @author: zhangpan
* @data: 2022/3/9 23:36
*/
@SpringBootTest
public class TestDemo {
/**
* ES连接方法
* @return
*/
public static RestHighLevelClient getClient() {
//创建HttpHost对象
HttpHost host = new HttpHost("192.168.45.128", 9200);
//创建RestClientBuilder
RestClientBuilder builder = RestClient.builder(host);
//创建RestHighLevelClient
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);
//返回
return restHighLevelClient;
}
/**
* 创建测试类,连接ES
*/
@Test
public void test() {
getClient();
System.out.println("ok");
}
}
2.2 Java操作索引
package com.pan;
import com.pan.util.ESClient;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.admin.indices.get.GetIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.json.JsonXContent;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* @PackageName: com.pan
* @ClassName: IndicesDemo 索引
* @author: zhangpan
*/
@SpringBootTest
public class IndicesDemo {
RestHighLevelClient client = ESClient.getClient();
String index = "person";
String type = "man";
/**
* 判断索引是否存在
* @throws IOException
*/
@Test
public void exists() throws IOException {
//1.准备request对象
GetIndexRequest request = new GetIndexRequest();
request.indices(index);
// request.indices("zhzh");
//2.通过client去操作
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
//3.输出
System.out.println(exists);
}
/**
* 创建索引
* @throws IOException
*/
@Test
public void createIndex() throws IOException {
//1.准备关于索引的settings
Settings.Builder settings = Settings.builder()
.put("number_of_shards",3) //分片数
.put("number_of_replicas",1); //备份数
//2.准备关于索引的结构mappings
XContentBuilder mappings = JsonXContent.contentBuilder()
.startObject()
.startObject("properties")
.startObject("name")
.field("type","text")
.endObject()
.startObject("age")
.field("type","integer")
.endObject()
.startObject("birthday")
.field("type","date")
.field("format","yyyy-MM-dd")
.endObject()
.endObject()
.endObject();
//3.将settings和mappings封装到一个Request对象
CreateIndexRequest request = new CreateIndexRequest(index)
.settings(settings)
.mapping(type,mappings);
//4.通过client对象去连接ES并执行创建索引
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
//5.输出
System.out.println("response:"+response.toString());
}
/**
* 删除索引
* @throws IOException
*/
@Test
public void delete() throws IOException {
//1.准备request对象
DeleteIndexRequest request = new DeleteIndexRequest();
request.indices(index);
//2.通过client去操作
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
//3.输出
System.out.println(delete.isAcknowledged());
}
}
2.3 操作文档
先创建一个person实体类,我这边使用lombok插件
id不用序列化,birthday字段是yyyy-MM-dd格式,不能序列化为Date
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
@JsonIgnore //这个是doc_id,不用序列化
private Integer id;
private String name;
private Integer age;
@JsonFormat(pattern="yyyy-MM-dd")
private Date birthday;
}
下一步写代码操作文档
package com.pan.test;
import com.pan.bean.Person;
import com.pan.utils.ESClient;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import java.io.IOException;
import java.util.Date;
public class DocDemo {
String index = "person";
RestHighLevelClient client = ESClient.getClient();
ObjectMapper mapper = new ObjectMapper();
//创建文档
@Test
public void createDoc() throws IOException {
// 1、准备json数据
Person person = new Person(1, "chb", 23, new Date());
String json = mapper.writeValueAsString(person);
// 准备request对象用于添加数据
IndexRequest request = new IndexRequest(index);
request.source(json, XContentType.JSON); // 添加数据
// 3、通过client对象执行, 注意此处与操作Index的区别 client.indices().create
IndexResponse resp = client.index(request, RequestOptions.DEFAULT);
// 4、打印结果
System.out.println(resp);
}
//修改文档
@Test
public void updateDoc() throws IOException {
// 1、创建一个Map, 指定需要修改的内容
Map<String, Object> doc = new HashMap<String, Object>();
doc.put("name", "张三");
String docId = "N67mgXgB_tiW03WV73UZ";
// 2、创建request对象,封装数据
UpdateRequest updateRequest = new UpdateRequest(index, docId);
updateRequest.doc(doc);
// 3、执行
UpdateResponse resp = client.update(updateRequest, RequestOptions.DEFAULT);
// 结果
System.out.println(resp.getResult().toString());
}
//删除文档
@Test
public void deleteDoc() throws IOException {
DeleteRequest request = new DeleteRequest(index, "N67mgXgB_tiW03WV73UZ");
client.delete(request, RequestOptions.DEFAULT);
}
//批量操作 增加
@Test
public void bulkCreateDoc() throws IOException {
// 1、准备json数据
Person person1 = new Person(3, "张三", 33, new Date());
Person person2 = new Person(4, "李四", 44, new Date());
Person person3 = new Person(5, "王五", 55, new Date());
String json1 = mapper.writeValueAsString(person1);
String json2 = mapper.writeValueAsString(person2);
String json3 = mapper.writeValueAsString(person3);
// 准备request对象用于添加数据
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.add(new IndexRequest(index).id(person1.getId().toString()).source(json1, XContentType.JSON));
bulkRequest.add(new IndexRequest(index).id(person2.getId().toString()).source(json2, XContentType.JSON));
bulkRequest.add(new IndexRequest(index).id(person3.getId().toString()).source(json3, XContentType.JSON));
// 3、通过client对象执行, 注意此处与操作Index的区别 client.indices().create
BulkResponse resp = client.bulk(bulkRequest, RequestOptions.DEFAULT);
// 4、打印结果
System.out.println(resp);
}
//批量删除
@Test
public void bulkDeleteDoc() throws IOException {
// DeleteRequest request = new DeleteRequest(index, "N67mgXgB_tiW03WV73UZ");
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.add(new DeleteRequest(index, "3"));
bulkRequest.add(new DeleteRequest(index, "4"));
bulkRequest.add(new DeleteRequest(index, "5"));
client.bulk(bulkRequest, RequestOptions.DEFAULT);
}
}
3.仿京东页面搜索功能
这个项目是根据B站狂神教学的项目,静态资源随便一查就可以找到。
我这边用的es版本是7.13.2
首先第一件事还是创建一个springboot工程。注意一点就是springboot项目版本不能太高。我这边用的是2.4.5版本的。
pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.pan</groupId>
<artifactId>springboot-elasticsearch</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot-elasticsearch</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<!--自定义es版本-->
<elasticsearch.version>7.13.2</elasticsearch.version>
</properties>
<dependencies>
<!--elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.2</version>
</dependency>
<!-- 解析网页 不能爬电影音乐-->
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
<!--json-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<!--thymeleaf模板-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.project.lombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
引入静态资源
前端页面
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8"/>
<title>狂神说Java-ES仿京东实战</title>
<link rel="stylesheet" th:href="@{/css/style.css}"/>
<!--前端使用Vue,实现前后端分离-->
<script th:src="@{/js/axios.min.js}"></script>
<script th:src="@{js/vue.min.js}"></script>
</head>
<body class="pg">
<div class="page" id="app">
<div id="mallPage" class=" mallist tmall- page-not-market ">
<!-- 头部搜索 -->
<div id="header" class=" header-list-app">
<div class="headerLayout">
<div class="headerCon ">
<!-- Logo-->
<h1 id="mallLogo">
<img th:src="@{/images/jdlogo.png}" alt="">
</h1>
<div class="header-extra">
<!--搜索-->
<div id="mallSearch" class="mall-search">
<form name="searchTop" class="mallSearch-form clearfix">
<fieldset>
<legend>天猫搜索</legend>
<div class="mallSearch-input clearfix">
<div class="s-combobox" id="s-combobox-685">
<div class="s-combobox-input-wrap">
<input v-model="keyword" type="text" autocomplete="off" value="dd" id="mq"
class="s-combobox-input" aria-haspopup="true">
</div>
</div>
<button type="submit" @click.prevent="searchKey" id="searchbtn">搜索</button>
</div>
</fieldset>
</form>
<ul class="relKeyTop">
<li><a>狂神说Java</a></li>
<li><a>狂神说前端</a></li>
<li><a>狂神说Linux</a></li>
<li><a>狂神说大数据</a></li>
<li><a>狂神聊理财</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<!-- 商品详情页面 -->
<div id="content">
<div class="main">
<!-- 品牌分类 -->
<form class="navAttrsForm">
<div class="attrs j_NavAttrs" style="display:block">
<div class="brandAttr j_nav_brand">
<div class="j_Brand attr">
<div class="attrKey">
品牌
</div>
<div class="attrValues">
<ul class="av-collapse row-2">
<li><a href="#"> 狂神说 </a></li>
<li><a href="#"> Java </a></li>
</ul>
</div>
</div>
</div>
</div>
</form>
<!-- 排序规则 -->
<div class="filter clearfix">
<a class="fSort fSort-cur">综合<i class="f-ico-arrow-d"></i></a>
<a class="fSort">人气<i class="f-ico-arrow-d"></i></a>
<a class="fSort">新品<i class="f-ico-arrow-d"></i></a>
<a class="fSort">销量<i class="f-ico-arrow-d"></i></a>
<a class="fSort">价格<i class="f-ico-triangle-mt"></i><i class="f-ico-triangle-mb"></i></a>
</div>
<!-- 商品详情 -->
<div class="view grid-nosku">
<div class="product" v-for="result in results">
<div class="product-iWrap">
<!--商品封面-->
<div class="productImg-wrap">
<a class="productImg">
<img :src="result.img">
</a>
</div>
<!--价格-->
<p class="productPrice">
<em>{{result.price}}</em>
</p>
<!--标题-->
<p class="productTitle">
<a v-html="result.title"></a>
</p>
<!-- 店铺名 -->
<div class="productShop">
<span>店铺: 狂神说Java </span>
</div>
<!-- 成交信息 -->
<p class="productStatus">
<span>月成交<em>999笔</em></span>
<span>评价 <a>3</a></span>
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<!--前端使用Vue,实现前后端分离-->
<script>
new Vue({
el: '#app',
data: {
keyword: '',//搜索的关键字
results: [] //搜索的结果
},
methods: {
searchKey(){
var keyword = this.keyword;
console.log('keyword'+keyword);
//对接后端的接口
axios.get('search/'+keyword+"/1/20").then(response=>{
console.log(response);
this.results = response.data; //将获取到的数据赋值给results
})
}
}
})
</script>
</body>
</html>
编写测试的controller
@Controller
public class IndexController {
@GetMapping({"/","index"})
public String index(){
return "index";
}
}
properties配置文件
server.port=9999
spring.thymeleaf.cache=false
访问测试 localhost:9999 这时只会出现京东页面不会出现商品的信息。
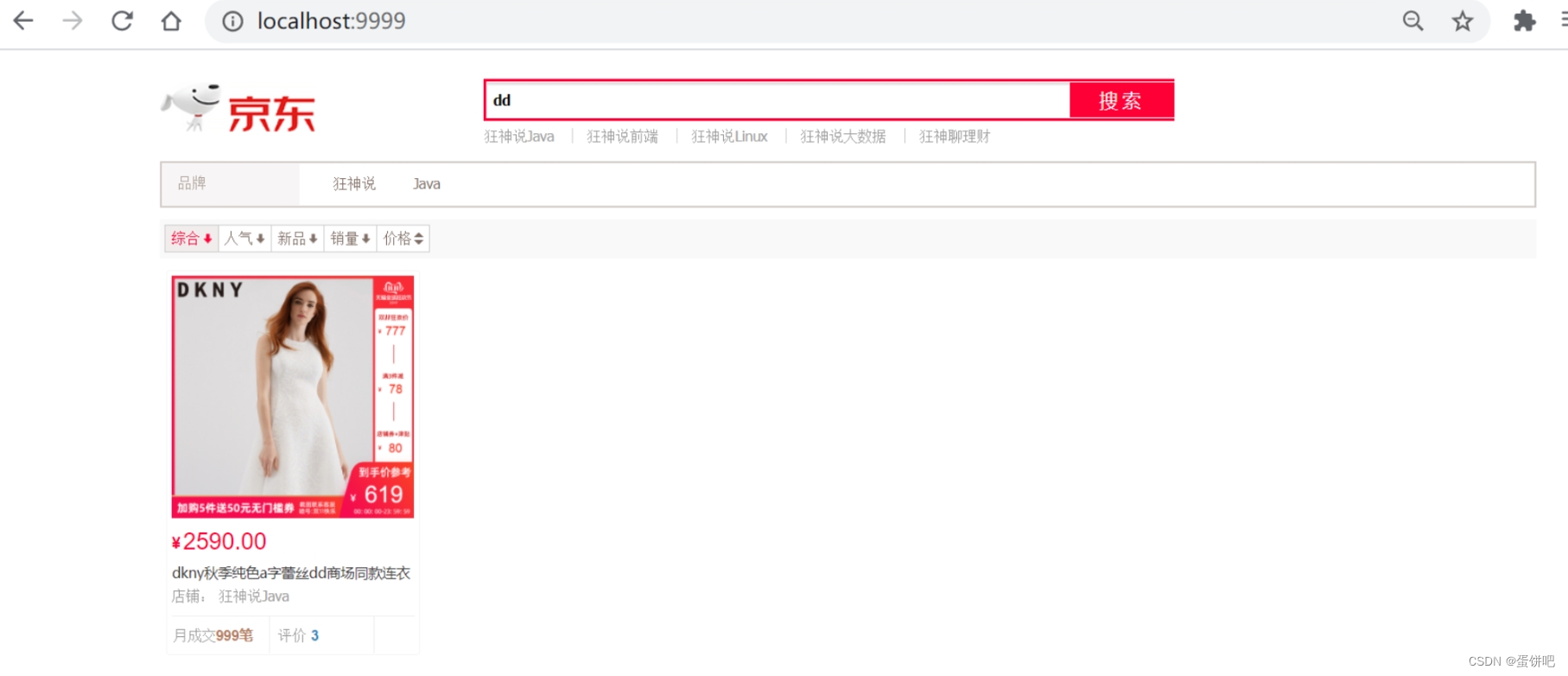
编写爬虫相关类,用于获取数据。
先访问京东页面,搜索商品 java
页面如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9B2sU6bS-1678778931732)(C:\Users\24329\Desktop\jd1.png)]
审查页面元素
页面列表id:J_goodsList
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2rzrdest-1678778931733)(C:\Users\24329\Desktop\jd2.png)]
目标元素:img、price、name
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g2dPtmrB-1678778931734)(C:\Users\24329\Desktop\jd3.png)]
Content页面对象
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content implements Serializable {
private static final long serialVersionUID = -8049497962627482693L;
private String name;
private String img;
private String price;
}
HtmlParseUtil 爬取页面的工具类。在测试时需要联网。 在浏览器打开京东搜索关键字java,打开网页。方便代码去获取数据。
package com.pan.utils;
import com.pan.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
@Component
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
new HtmlParseUtil().parseJD("java").forEach(System.out::println);
}
public List<Content> parseJD(String keywords) throws IOException {
// 获取请求 https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword="+keywords;
// 解析网页
Document document = Jsoup.parse(new URL(url), 30000);
// 所有在js中使用的方法,在这里都可以用
Element element = document.getElementById("J_goodsList");
// 获取所有的li元素
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodList = new ArrayList<>();
//获取元素中的内容
for (Element el : elements) {
// 关于这种图片特别多的网站,图片都是延时加载的 source-data-lazy-img
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setTitle(title);
content.setPrice(price);
content.setImg(img);
goodList.add(content);
}
return goodList;
}
}
获取页面数据成功后,编写ES配置类
package com.pan.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.45.100",9200,"http"))
);
return client;
}
}
编写service层
因为是爬取的数据,那么就不走dao层了,在实际业务中,根据业务需求获取数据库中的数据即可。
ContentService业务层
package com.pan.service;
import com.alibaba.fastjson.JSON;
import com.pan.pojo.Content;
import com.pan.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Service
public class ContentService { //业务编写
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 1.解析数据放入es中
* @param keywords
* @return
* @throws IOException
*/
public Boolean parseContent(String keywords) throws IOException {
List<Content> contents = new HtmlParseUtil().parseJD(keywords);
//把查到的数据放入es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i=0; i<contents.size(); i++){
// bulkRequest.add(new IndexRequest("jd_goods").source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
IndexRequest request = new IndexRequest("jd_goods");
String jsonString = JSON.toJSONString(contents.get(i));
request.source(jsonString, XContentType.JSON);
bulkRequest.add(request);
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
/**
* 2.获取这些数据实现搜索功能
* @param keywords
* @param pageNo
* @param pageSize
* @return
* @throws IOException
*/
public List<Map<String,Object>> searchPage(String keywords,int pageNo,int pageSize) throws IOException {
if(pageNo<1){
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keywords);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
list.add( documentFields.getSourceAsMap());
}
return list;
}
/**
* 3.获取这些数据实现搜索高亮功能
* @param keywords
* @param pageNo
* @param pageSize
* @return
* @throws IOException
*/
public List<Map<String,Object>> searchPageHighLight(String keywords,int pageNo,int pageSize) throws IOException {
if(pageNo<1){
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keywords);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);//多个高亮显示
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
//解析高亮的字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的结果
//解析高亮的字段 :将原来的字段置换为高亮的字段
if(title!=null){
Text[] fragments = title.fragments();
String new_title ="";
for (Text text : fragments) {
new_title += text;
}
sourceAsMap.put("title",new_title);
}
list.add(sourceAsMap);
}
return list;
}
}
Controller
package com.pan.controller;
import com.pan.service.ContentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@RestController
public class ContentController { //请求编写
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keywords}")
public Boolean parse(@PathVariable("keywords") String keywords) throws IOException {
return contentService.parseContent(keywords);
}
@GetMapping("/search/{keywords}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keywords") String keywords,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize")int pageSize) throws IOException {
return contentService.searchPageHighLight(keywords,pageNo,pageSize);
}
@GetMapping("/searchHighLight/{keywords}/{pageNo}/{pageSize}")
public List<Map<String,Object>> searchHighLight(@PathVariable("keywords") String keywords,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize")int pageSize) throws IOException {
return contentService.searchPageHighLight(keywords,pageNo,pageSize);
}
}
启动控制类也加一下
package com.pan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @PackageName: com.pan
* @ClassName: ESApplication
* @author: zhangpan
* @data: 2022/3/11 0:40
*
*
* 服务器地址:192.168.45.100
* 启动es
* su es
* cd /usr/local/es/elasticsearch/bin
* ./elasticsearch
*
* 启动kibana
* su es
* cd /usr/local/es/kibana/bin
* ./kibana
*
* 启动head
* cmd管理员启动
* d:
* D:\zhangpan\SpringBootPlug-in\elasticsearch-head-master 192.168.45.100
* npm run start
*/
@SpringBootApplication
public class ESApplication {
public static void main(String[] args) {
SpringApplication.run(ESApplication.class,args);
}
}
需要VUE环境,下载node.js等。
使用term(精确查询)时遇到的问题
字段值必须是一个词(索引中存在的词),才能匹配
- 问题:中文字符串,term查询时无法查询到数据(比如,“编程”两字在文档中存在,但是搜索不到)
- 原因:索引为配置中文分词器(默认使用standard,即所有中文字符串都会被切分为单个中文汉字作为单词),所以没有超过1个汉字的词,也就无法匹配,进而查不到数据
- 解决:创建索引时配置中文分词器,如
PUT example
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word" // ik分词器
}
}
}
}
- 查询的英文字符只能是小写,大写都无效
- 查询时英文单词必须是完整的
本文的基础概念借鉴于:ElasticSearch从入门到精通,史上最全(持续更新,未完待续,每天一点点)_Jenrey的博客-CSDN博客
历时一周的时间写完了,在自己学习ES中遇到很多问题,磨磨蹭蹭终于一点一点解决了。仅以此文章记录自己的学习历程,分享自己的学习成果。

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









