







实操项目 1——糖尿病情预测
实验要求
1.读取给定文件中数据。(数据集路径:data/data72160/1_film.csv)
2.绘制影厅观影人数(filmnum)与影厅面积(filmsize)的散点图。
3.绘制影厅人数数据集的散点图矩阵。
4.选取特征变量与相应变量,并进行数据划分。
5.进行线性回归模型训练。
6.根据求出的参数对测试集进行预测。
7.绘制测试集相应变量实际值与预测值的比较。
8.对预测结果进行评价。
实验过程
1.对该题目的理解
影厅观影人数预测主要是是实现多变量数据的可视化,并且利用多变量线性回归算法来进行数据拟合与预测,然后利用实际值与预测值绘制一个折线图,对其进行比较,然后得出预测的得分对预测结果评价。
2.实现过程
(1)导入包
代码如下:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
(2)读取给定文件中数据。(数据集路径:data/data72160/1_film.csv)。
代码如下:
film=pd.read_csv("data/data72160/1_film.csv")#读取文件
#读取0~5行,并输出
X=film.iloc[0:5,:]
print(X)
#切分成DataFrame数据
filmpd=pd.DataFrame(film)
print(film.shape)
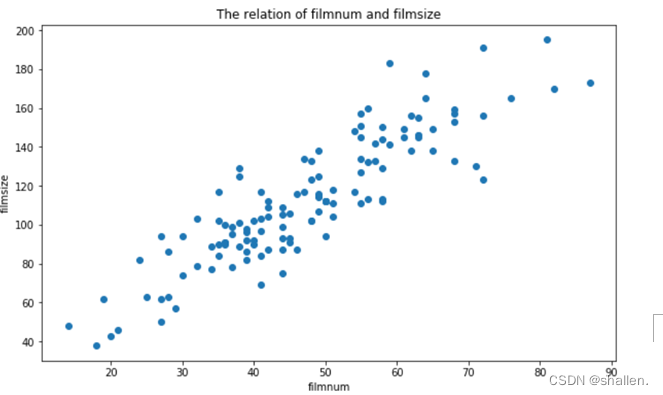
(3)绘制影厅观影人数与影厅面积的散点图
代码如下:
X=film.iloc[:,0]#X轴为观影人数(filmnum)
y=film.iloc[:,1]#y轴是影厅面积(filmsize)
plt.figure(figsize=(10,6))
plt.scatter(X,y)#绘制散点图
plt.xlabel(u'filmnum')
plt.ylabel(u'filmsize')
plt.title(u'The relation of filmnum and filmsize')#标题
plt.show()
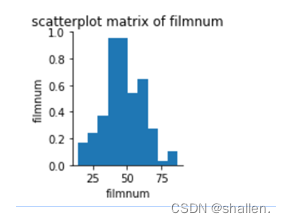
(4)绘制影厅人数数据集的散点图矩阵
代码如下:
import seaborn as sns
cols=['filmnum']
#pairplot主要展现的是变量两两之间的关系
#kind:用于控制非对角线上的图的类型,可选"scatter"与"reg"
#diag_kind:控制对角线上的图的类型,可选"hist"与"kde"
#将 kind 参数设置为 "reg" 会为非对角线上的散点图拟合出一条回归直线,更直观地显示变量之间的关系
#plot_kws:用于控制非对角线上的图的样式
#diag_kws:用于控制对角线上图的样式
sns.pairplot(film[cols],kind='reg',size=2.5)
#tight_layout会自动调整子图参数,使之填充整个图像区域
plt.tight_layout()
plt.title(u'scatterplot matrix of filmnum')
plt.show()
(5)选取特征变量与相应变量,并进行数据划分
代码如下:
X=film.iloc[:,1:4]
y=film.filmnum
X=np.array(X.values)
y=np.array(y.values)
train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.25)
print(train_X.shape)
(6)进行线性回归模型训练
代码如下:
model=LinearRegression()
model.fit(train_X,train_y)
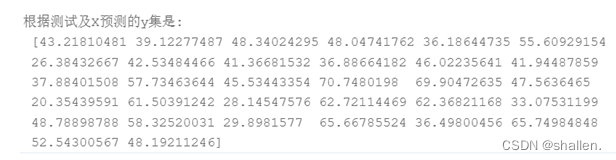
(7)根据求出的参数对测试集进行预测
代码如下:
pre_y=model.predict(test_X)
print("根据测试及X预测的y集是:\n",pre_y)
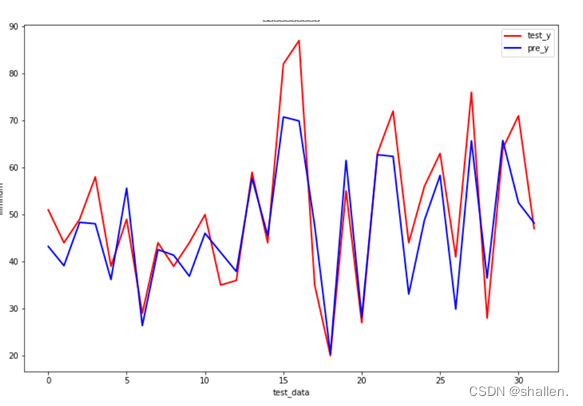
(8)绘制测试集相应变量实际值与预测值的比较
代码如下:
plt.figure(figsize=(12,8))
t=np.arange(len(test_X))#arange返回的是一个数据,创建t变量
plt.plot(t,test_y,linewidth=2,label="test_y",color="red")#真实
plt.plot(t,pre_y,linewidth=2,label="pre_y",color="blue")#预测
plt.legend()#设置图例
plt.title("实际值与预测值折线图")
plt.xlabel("test_data")
plt.ylabel("filmnum")
plt.show()
(9)绘制测试集相应变量实际值与预测值的比较
代码如下:
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score#R square
#调用
mean_squared_error(test_y,pre_y)
mean_absolute_error(test_y,pre_y)
print('score={}'.format(r2_score(test_y,pre_y)))
3.实验结果
绘制影厅观影人数与影厅面积的散点图
绘制影厅人数数据集的散点图矩阵
根据求出的参数对测试集进行预测
绘制测试集相应变量实际值与预测值的比较。
实验总结
1.通过此实验了解了回归评价的指标,我学会了拟合优度R,但是它有缺点,缺点是数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差。
2.通过此实验我也了解了如何创建散点图矩阵,了解了其中的pairplot主要展现的是变量两两之间的关系。
3.更加熟练了如何画散点图,如何训练模型,如何划分数据集测试集等等。

















 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











