









数据集:
数据集下载链接:https://download.csdn.net/download/qq_43705330/85426684

wechat:微信公众号的投放金额、weibo:微博的投放广告的金额、others:其他项目投放的金额、sales:商品的销售额
数据的热力图代码:
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
# 读入数据并显示前面几行的内容,这是为了确保我们的文件读入的正确性
# 示例代码是在Kaggle中数据集中读入文件,如果在本机中需要指定具体本地路径
df_ads = pd.read_csv('advertising.csv')
df_ads.head()#显示前五行
print(df_ads)
# 导入数据可视化所需要的库
import matplotlib.pyplot as plt # Matplotlib – Python画图工具库
import seaborn as sns # Seaborn – 统计学数据可视化工具库
# 对所有的标签和特征两两显示其相关性热力图(heatmap),得到两两之间的相关系数
sns.heatmap(df_ads.corr(), cmap="YlGnBu", annot=True)
plt.show() # plt代表英文plot,就是画图的意思
注:
1、corr():返回改数据类型的相关系数矩阵
2、heatmap()函数:
cmap:颜色
annot:如果为True,则在每个单元格中写入数据值。
如果一个与数据形状相同的数组,那么使用它来注释热图而不是数据。注意DataFrames将匹配位置,而不是索引。
对于热力图函数heatmap的详细使用方法可看这个:http://seaborn.pydata.org/generated/seaborn.heatmap.html
运行结果:

运行代码后,可得三个自变量与因变量之间的线性关系,相关性越高颜色越深。由此图可得,在微信公众号投放广告收益最高。
数据的散点图:
# 显示销量和各种广告投放量的散点图
sns.pairplot(df_ads,x_vars=['wechat', 'weibo', 'others'],#x轴
y_vars='sales',#y轴,
height=4, aspect=1, kind='scatter')
plt.show()
注:
pairplot函数:
kind:‘scatter’, ‘kde’, ‘hist’, ‘reg’
diag_kind:‘auto’, ‘hist’, ‘kde’,
对角线子图的类型。如果是’auto’,根据是否hue使用来选择。
pairplot的用法:http://seaborn.pydata.org/generated/seaborn.pairplot.html?highlight=pairplot#seaborn.pairplot
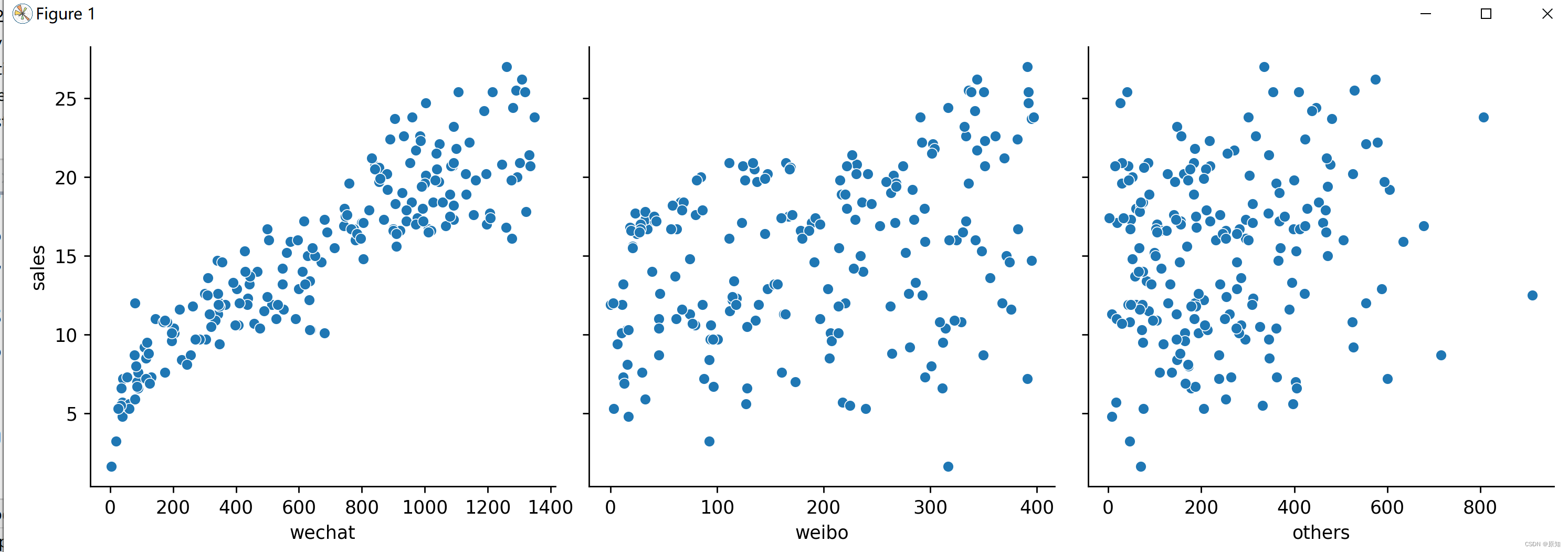
散点图可以很直观的显示自变量与因变量之间的关系。
面是手动画微信与销售额的散点图并且进行机器学习,上面是用函数来画
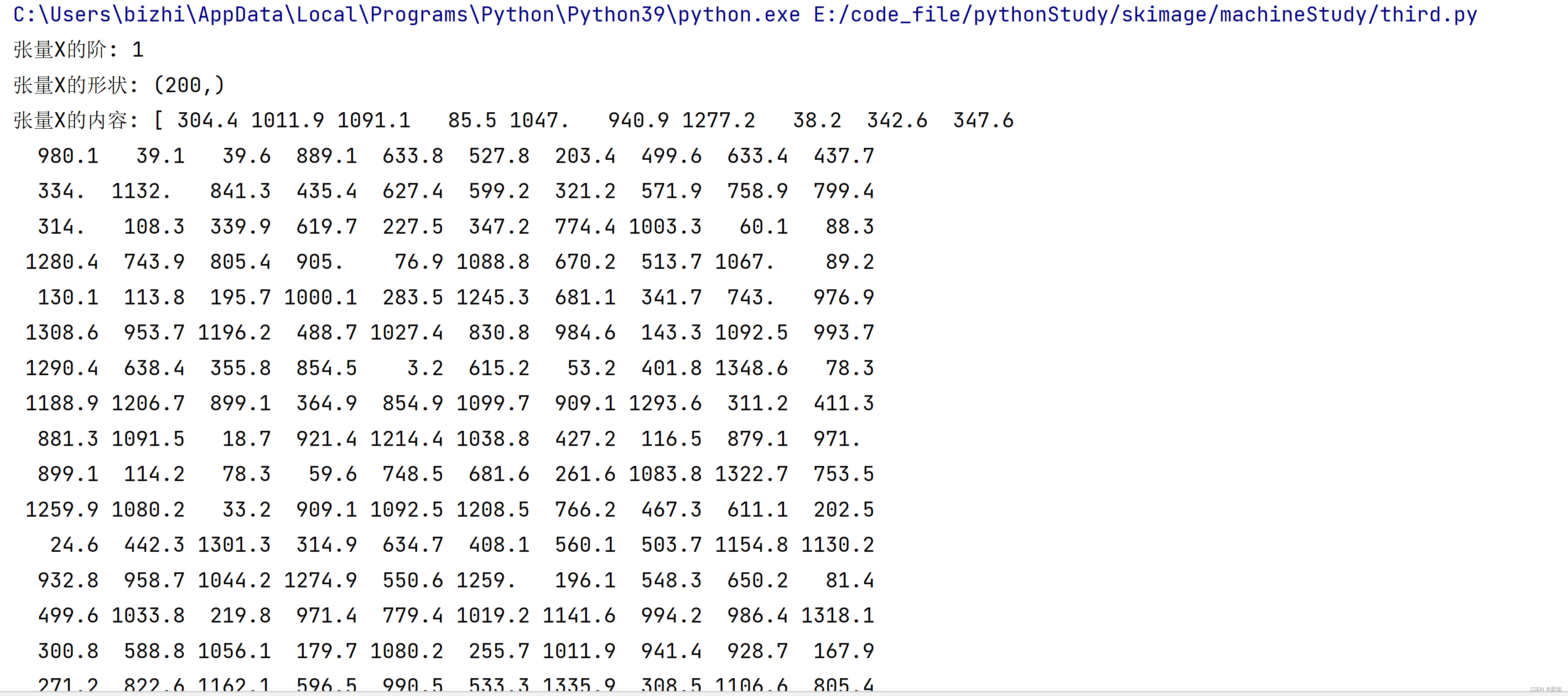
X = np.array(df_ads.wechat) # 构建特征集,只有微信广告一个特征
y = np.array(df_ads.sales) # 构建标签集,销售金额
print("张量X的阶:", X.ndim)
print("张量X的形状:", X.shape)
print("张量X的内容:", X)
X = X.reshape((len(X),1)) #通过reshape函数把向量转换为矩阵,len函数返回样本个数
y = y.reshape((len(y),1)) #通过reshape函数把向量转换为矩阵,len函数返回样本个数
#X(微信)变为200行1列,y(销售额)变为200行1列
print("张量X的阶:", X.ndim)
print("张量X的形状:", X.shape)
print("X:",X)
#将数据集进行80%(训练集)和20%(验证集)的分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)#random_state:用于数据集拆分过程的随机化设定。
#如果指定了一个整数,那么这个数叫做随机化种子,每次设定的固定的种子能够保证得到同样的训练集和测试集,否则进行随机分割。
#数据归一化使得预处理的数据被限定在一定的范围内,从而消除奇异样本数据导致的不良影响。数据归一化处理后,可以加快梯度下降求最优解的速度,且有可能提高精度(如KNN)
# def scaler(train, test): # 定义归一化函数 ,进行数据压缩
# min = train.min(axis=0) # 训练集最小值
# max = train.max(axis=0) # 训练集最大值
# gap = max - min # 最大值和最小值的差
# train -= min # 所有数据减最小值
# train /= gap # 所有数据除以大小值差
# test -= min # 把训练集最小值应用于测试集
# test /= gap # 把训练集大小值差应用于测试集
# return train, test # 返回压缩后的数据
# X_train, X_test = scaler(X_train, X_test) # 对特征归一化
# y_train, y_test = scaler(y_train, y_test) # 对标签也归一化
from sklearn.linear_model import LinearRegression #导入线性回归算法模型
model = LinearRegression() #使用线性回归算法
model.fit(X_train, y_train) #用训练集数据,训练机器,拟合函数,确定参数
y_pred = model.predict(X_test) #预测测试集的Y值
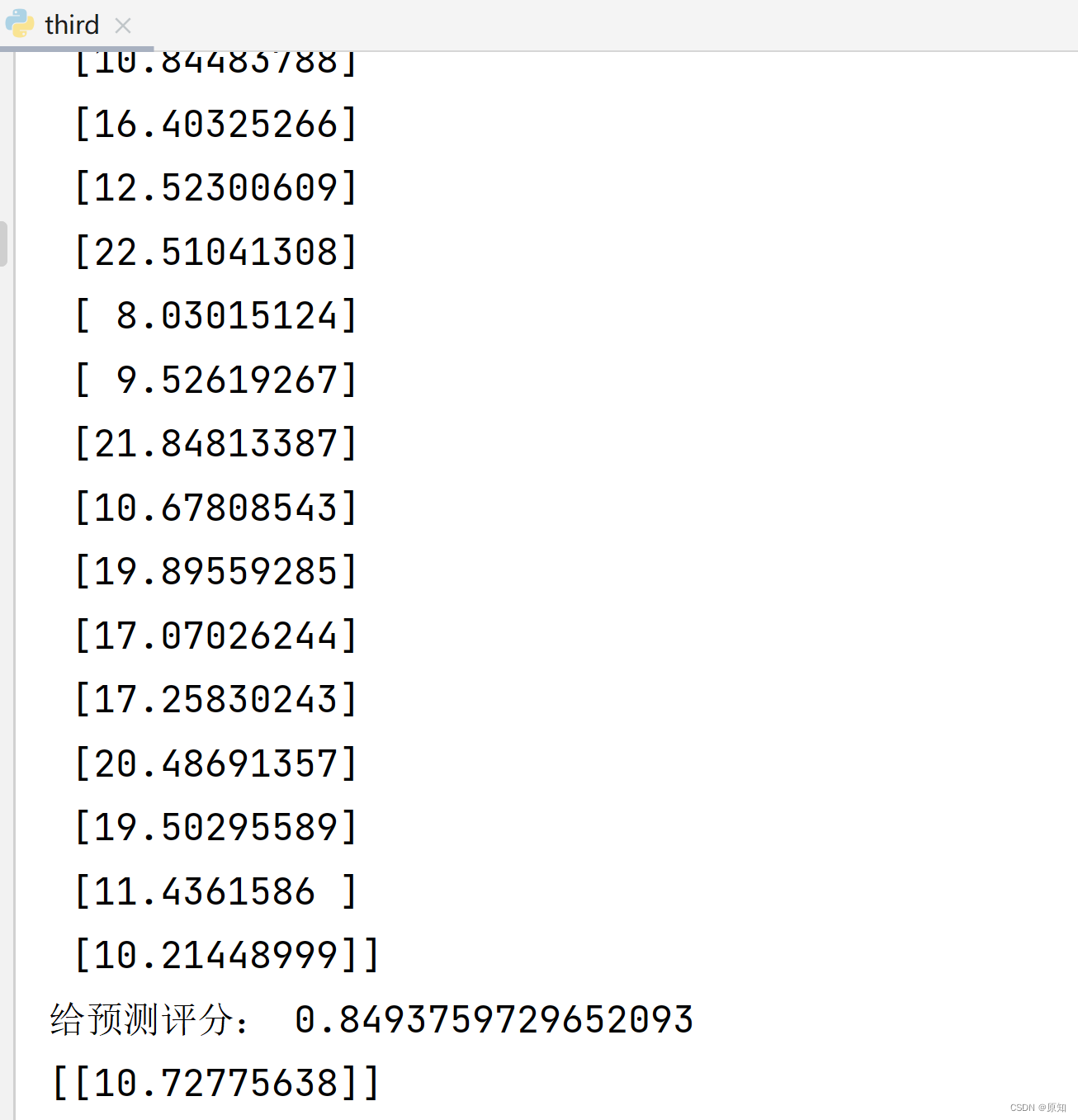
print ('销售额的真值(测试集)',y_test)
print ('销售额的预测(测试集)',y_pred)
print("给预测评分:", model.score(X_test, y_test)) #评估预测结果,返回该次预测的系数R2
y_1=model.predict([[305]])
print(y_1)
# lineX = np.linspace(X_norm.min(), X_norm.max(),100)
# 用之前已经导入的matplotlib.pyplot中的plot方法显示散点图
plt.plot(X_train, y_train, 'r.', label='Training data')
plt.xlabel('Wechat Ads') # x轴Label
plt.ylabel('Sales') # y轴Label
plt.legend() # 显示图例
plt.show() # 显示绘图结果
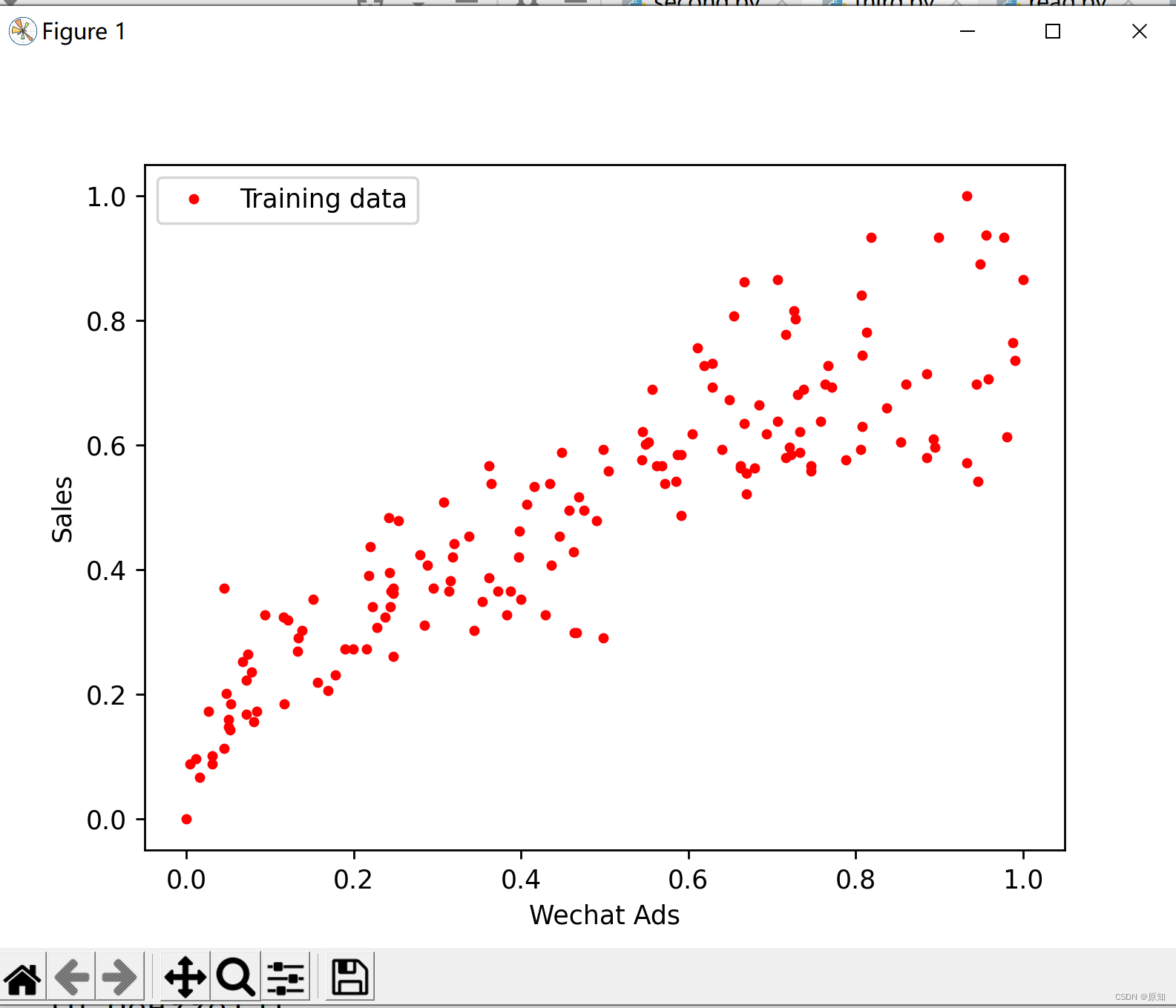
下面进行确定线性回归模型并且给定具体的参数。
对y=ax+b寻找最优解,确定损失函数L(w,b),其中,h(x)为假设函数。
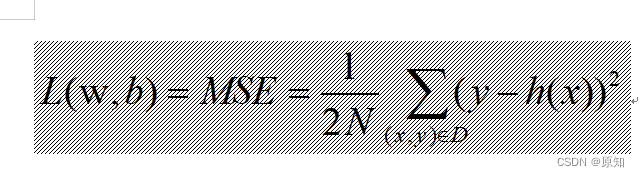
注:
1、(x, y)为样本,×是特征(微信公众号广告投放金额),y是标签(销售额)。
2、h(x)是假设函数wx+b,也就是y’。
3、D指的是包含多个样本的数据集。
4、N指的是样本数量(此例为200)。N前面还有常量2,是为了在求梯度的时候,抵消二次方后产生的系数,方便后续进行计算,同时增加的这个常量并不影响梯度下降的最效结果。
5、而L呢,对于一个给定的训练样本集而言,它是权重w和偏置b的函数,它的大小随着w和b的变化而变。
用Python定义一个MSE函数,并将其封装起来。
def cost_function(X, y, w, b): # 手工定义一个MSE均方误差函数
y_hat = w * X + b # 这是假设函数,其中已经应用了Python的广播功能
loss = y_hat - y # 求出每一个y’和训练集中真实的y之间的差异
cost = np.sum(loss ** 2) / len(X) # 这是均方误差函数的代码实现
return cost # 返回当前模型的均方误差值
print("当权重4,偏置0.05时,损失为:", cost_function(X_train, y_train, w=4, b=0.05))
print("当权重50,偏置1时,损失为:", cost_function(X_train, y_train, w=50, b=1))

即:y=4x+0.05比y=50x+1效果更好














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









