







1. 质数判定
解析:质数判定从2 — n - 1都不会被整除即可
优化:不需要判定到 n - 1这么远,而只需要判定到根号 n 的位置,原因很简单假如你大于根号n之后还可以判定其可以整除,那么它一定是由一个大于根号n 和小于根号n 的两个整数相乘得到结果,所以这个结果的判定一定可以在小于根号n的时候完成。
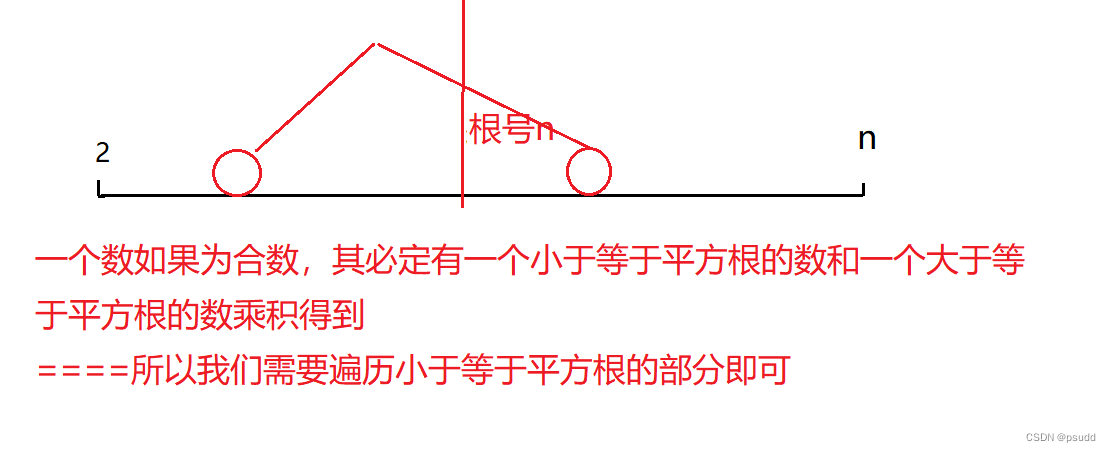
**判断是否为质数
bool is_prime(int x){
if(x == 1) return false;
for(int i = 2 ; i <= x / i ; i ++ ){
if(x % i == 0) return false;
}
return true;
}
2. 质数分解
解析:与前面相似从小到大筛选其质数,如果是其质数则不断除去即可
注意:最后可能会剩下一个质数,需要判定其是否存在
#include<iostream>
using namespace std;
int n, x;
void divide(int x){
for(int i = 2 ; i <= x / i ; i ++ ){
if(x % i == 0){
int s = 0;
while(x % i == 0){
x /= i;
s ++ ;
}
cout << i << ' ' << s << endl; // i 的 s 次方 组成
}
}
if(x > 1){ // 是否有质数剩余
cout << x << ' ' << 1 << endl;
}
}
int main(){
cin >> n;
while(n -- ){
cin >> x;
divide(x);
}
}
3. 质数筛选
普通筛法:和质数筛选方法相似,因为合数是由较小的质数乘积组成,所以当我们遇到质数就用去删去其后由这个质数组成的合数即可。
线性筛法:保证合数只会被其最小的质数乘积筛去
线性筛法原理:核心就是用其前面求出来的质数和 i 进行相乘进行筛选,因为筛选出来的数是由最小的质数和 i 乘积筛去的,知道 i % primes[ j ] == 0时跳出循环,因为如果再继续筛去,其值是用 i 筛去的,而 i 还有更小的质因子也就是之前的primes[ j ]. 当i能被当前的质数整除时(当前整数就是i的最小质数)
例如下图线性筛法解析:

// 普通筛法
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int n, s = 0;
bool st[N];
int main(){
cin >> n;
for(int i = 2 ; i <= n ; i ++ ){
if(st[i]) continue; // 合数跳过
s ++ ;
for(int j = i ; j <= n ;j += i) st[j] = true; // 删去之后由这个质数乘积得到的合数
}
cout << s << endl;
}
线性筛法核心
if(i % primes[ j ] != 0) primes[j] 就是 primes[ j ] * i 的最小质因子(因为是从前向后碰到的第一个质因子必定就是最小的了)
if(i % primes[ j ] == 0) primes[j] 就是 primes[ j ] * i 的最小质因子,并且也是 i 的最小质因子,之后如果继续用 i 筛去别的数字就是不正确的(因为它们本需要用primes[j]作为最小质因子去筛掉) 所以这时候需要跳出循环
**筛选质数(线性筛法)
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int n, s = 0, primes[N];
bool st[N];
int main(){
cin >> n;
for(int i = 2 ; i <= n ; i ++ ){
if(!st[i]) primes[s ++] = i; // 加入为质数
for(int j = 0 ; primes[j] <= n / i ; j ++ ){
st[primes[j] * i] = true; // 筛去
if(i % primes[j] == 0) break; // 跳出循环,不能继续筛,
//因为之后下一个假设为j + 1再筛去的部分是用primes[j + 1] * i 筛去的,
//而其实 primes[j + 1] * i的最小质数不是primes[j + 1] 或者 i 而是之前的primes[j]
}
}
cout << s << endl;
}
















 2041
2041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











