







UCM数据集
UC Merced Land-Use
UC Merced Land-Use遥感数据集是由UC Merced计算机视觉实验室公布的用于遥感图像场景分类的公开数据集,包含21类场景,具体每个类别为(1) agricultural(农田)、(2) airplane(飞机)、(3) baseball diamond(棒球内场)、(4) beach(海滩)、 (5) buildings(建筑)、(6) chaparral(灌木丛)、(7) dense residential(密集的住宅)、(8) forest(森林)、(9) freeway(高速公路,快车道)、(10) golf course(高尔夫球场)、 (11) harbor(海港)、(12) intersection(十字路口)、(13) medium residential(中等住宅)、(14) mobile home park(移动式家庭公园)、(15) overpass(立交桥)、 (16) parking lot(停车场)、 (17) river(河)、 (18) runway(跑道)、 (19) sparse residential(稀疏住宅)、 (20) storage tanks(储罐)、 (21) tennis court(网球场),其中每个类别各包含100张遥感图像,整个数据集一共2100张遥感图像,每张遥感图像的大小为256 × \times× 256。
数据集下载:UC Merced Land Use Dataset
准备好数据集后,我们开始学习吧~
1.model.py——定义LeNet网络模型。
2.train.py——加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数。
3.predict.py——利用训练好的网络参数后,用自己找的图像进行分类测试。
1.定义LeNet网络模型---------------model.py
#-*- coding : utf-8-*-
# coding:unicode_escape
import torch.nn as nn
import torch.nn.functional as F
#在pytorch中搭建模型
#首先建立一个类,把类寄存于nn.Moudel中
class LeNet(nn.Module):
#定义初始化函数
def __init__(self):
#在初始化函数中搭建需要使用的网络层结构
super(LeNet, self).__init__()#一般涉及到多继承,就会使用super函数
self.conv1 = nn.Conv2d(3, 16, 5)
# 定义卷积层conv1,第一个参数就是输入特征层的深度,3表示输入的是彩色图片,使用了16个卷积核,卷积核的大小是5*5
self.pool1 = nn.MaxPool2d(2, 2)
#定义下采样层pool1,池化核为2*2 步长是2的最大池化操作,池化层不改变深度,只影响高度和宽度,高度宽度缩小一般
self.conv2 = nn.Conv2d(16, 32, 5)
# 定义第二个卷积层conv2,输入特征层的深度为16,因为第一个卷积层输出的为16的特征矩阵,采用32个卷积核,尺寸为5*5
self.pool2 = nn.MaxPool2d(2, 2)
# 定义第二个下采样层pool2,池化核为2*2 步长是2的最大池化操作。高度和宽度在缩小一半
self.fc1 = nn.Linear(32*5*5, 120)
#定义全连接层,需要将上一层输出展平也就是32*5*5,第一层的节点个数为120,
self.fc2 = nn.Linear(120, 84)
#第二个全连接层的输入就是上一个全连接层的输出120,第二个参数是输出
self.fc3 = nn.Linear(84, 10)
# 第三个全连接层的输入就是上一个全连接层的输出84,第二个参数是输出,因为是具有10个类别分类任务,所以输出是10.
#在forward函数中定义正向传播的过程
def forward(self, x): #x表示输入的数据
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28) 16个卷积核,所以channel是16
#进行卷积操作,在进行激活函数后输出
x = self.pool1(x) # output(16, 14, 14)
#进行下采样后输出
x = F.relu(self.conv2(x)) # output(32, 10, 10)
#再进行卷积层核激活函数
x = self.pool2(x) # output(32, 5, 5)
#再进行下采样层操作后输出
x = x.view(-1, 32*5*5) # output(32*5*5)
#将特征矩阵展平使用.view函数,第一个维度进行自动推理batch设置为-1,第二个维度就是展平后的节点个数
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
#全连接层3后进行输出
return x
2.加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数-------------------------train.py
注意:训练路径和测试路径需要改为你自己的路径。
#-*- coding : utf-8-*-
# coding:unicode_escape
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
#简单看一下导入的图片
#首先导入两个包
import matplotlib.pyplot as plt #绘制图像的包
import numpy as np
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='/home/data1/ffeng_data/3.ycx/RS-SC/Image-classification/UCMerced_LandUse/train', train=True,
download=True, transform=transform)
#下载完成后设置为False
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# shuffle=True是否将数据打乱
#导入测试数据集
# 验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='/home/data1/ffeng_data/3.ycx/RS-SC/Image-classification/UCMerced_LandUse/val', train=False,
download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=10000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
#iter函数是将刚刚生成的val_loader转换为可迭代的迭代器
val_image, val_label = val_data_iter.next()
#转换完之后通过next()就可以得到一批数据,包含测试的图像 val_image,图像对相应的标签值val_label
#把标签导入
# UCMerced_LandUse
CLASS = ('agricultural', 'airplane', 'baseballdiamond', 'beach', 'buildings',
'chaparral', 'denseresidential', 'forest', 'freeway', 'golfcourse', 'harbor',
'intersection', 'mediumresidential', 'mobilehomepark', 'overpass', 'parkinglot',
'river', 'runway', 'sparseresidential', 'storagetanks', 'tenniscourt')
# # 使用官方的imshow(img)函数,简单看一下导入的图片
# def imshow(img):
# img = img / 2 + 0.5 #对图像进行反标准化处理
# npimg = img.numpy() #将图片转化为numpy格式
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show() #展示出来
# # print labels
# print(' '.join('%5s' % classes[val_label[j]] for j in range(4)))
# # show images
# imshow(torchvision.utils.make_grid(val_image))
#导入模型
net = LeNet()
loss_function = nn.CrossEntropyLoss()
#使用Adam的优化器,第一个参数就是所需要训练的参数,学习率
optimizer = optim.Adam(net.parameters(), lr=0.001)
#进入训练过程
for epoch in range(5): # loop over the dataset multiple times
#将训练集迭代5次
running_loss = 0.0 #定义变量,用来累加训练过程中的损失
for step, data in enumerate(train_loader, start=0):
#通过循环遍历训练集样本
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data #输入的图像核标签
# zero the parameter gradients
optimizer.zero_grad() #每计算一个batch就需要调用一次
# forward + backward + optimize
outputs = net(inputs)#将得到的输入的图片上传到网络得到输出
loss = loss_function(outputs, labels)#通过定义的损失函数进行计算损失,第一个参数就是网络预测的值,第二个就是对应网络真实的标签
loss.backward() #将loss进行反向传播
optimizer.step()# 通过优化器进行更新
# 接下来就是一个打印的过程
running_loss += loss.item()
if step % 500 == 499: # 每隔500步打印一次数据的信息
with torch.no_grad(): #这个函数就是再计算过程中不需要计算每个节点的损失梯度,节省空间核算力
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]#网络预测最可能是哪个类别的,再维度1上寻找最大值,最后的1只需要知道index值
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
#最后将真实的标签按类别和预测的标签类别进行比较,再相同的地方返回1,不同就返回0,最后用一个求和操作知道本次预测对多少函数,再除以测试样本的数量就得到了准确率
#打印结果
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
#将模型进行保存
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
训练结束:
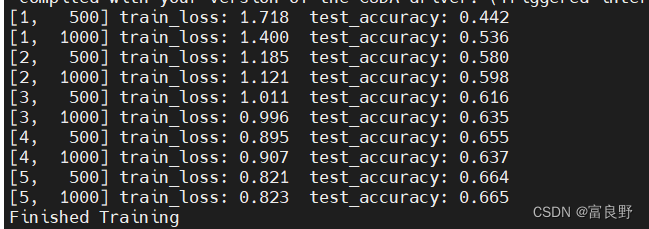
3.利用训练好的网络参数后,用自己找的图像进行分类-------------------------------------------predict.py
#-*- coding : utf-8-*-
# coding:unicode_escape
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)), #图片尺寸标准化
transforms.ToTensor(),#将图片转化为tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#进行标准化处理
CLASS = ('agricultural', 'airplane', 'baseballdiamond', 'beach', 'buildings',
'chaparral', 'denseresidential', 'forest', 'freeway', 'golfcourse', 'harbor',
'intersection', 'mediumresidential', 'mobilehomepark', 'overpass', 'parkinglot',
'river', 'runway', 'sparseresidential', 'storagetanks', 'tenniscourt')
net = LeNet() #实例化
net.load_state_dict(torch.load('Lenet.pth')) #调用训练得到的结果
im = Image.open('1.jpg') #判断这个图片
im = transform(im) # [C, H, W]图片标准化之后得到
im = torch.unsqueeze(im, dim=0) # [N, C, H, W] 再最前面增加一个维度
with torch.no_grad(): #表示不需要计算梯度损失
outputs = net(im) #输入网络图片得到输出
predict = torch.max(outputs, dim=1)[1].numpy()
print(CLASS[int(predict)])
#用softmax函数处理可以得到预测该图类别
#predict = torch.softmax(outputs, dim=1)
#print(predict)
if __name__ == '__main__':
main()
运行时出现报错
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 81: invalid continuation byte
我的解决办法是:在代码首行加入下面两行代码,希望能帮到你。
#-*- coding : utf-8-*-
# coding:unicode_escape
















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









