






给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
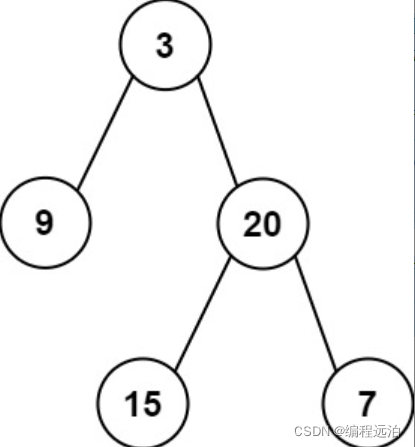
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]提示:
-
1 <= inorder.length <= 3000
-
postorder.length == inorder.length
-
-3000 <= inorder[i], postorder[i] <= 3000
-
inorder 和 postorder 都由 不同 的值组成
-
postorder 中每一个值都在 inorder 中
-
inorder 保证是树的中序遍历
-
postorder 保证是树的后序遍历
思路:
第一步,如果数组长度为0,则说明是空节点
第二步,如果数组不为空,那么就将后序数组最后一个元素作为节点元素
第三步,找到后序数组最后一个元素在中序数组中的位置并将其作为切割点
第四步,切割中序数组,切成中序左数组和中序右数组
第五步,切割后序数组,切成后序左数组和后序右数组
第六步,递归处理左区间和右区间便于理解的递归方法(费空间):
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
TreeNode* traversal(vector<int>& inorder,vector<int>& postorder){
//第一步,如果数组长度为0,则为空节点
if(postorder.size()==0) return NULL;
//第二步,如果后序数组不为空,那么数组最后一个节点将作为节点元素
int rootValue=postorder[postorder.size()-1];
TreeNode* root=new TreeNode(rootValue);
//叶子节点
if(postorder.size()==1)return root;
//第三步,找到后序数组中的最后的一个元素在中序数组中的位置并将其作为切割点
int delimiterIndex;
for(delimiterIndex=0;delimiterIndex<inorder.size();delimiterIndex++){
if(inorder[delimiterIndex]==rootValue)break;
}
//第四步,切割中序数组,分为左数组和右数组
//左闭右开区间,[0,delimiterIndex)
vector<int>leftInorder(inorder.begin(),inorder.begin()+delimiterIndex);
//[delimiterIndex+1,end)
vector<int>rightInorder(inorder.begin()+delimiterIndex+1,inorder.end());
//第五步,切割后序数组,分为左数组和右数组
//舍弃postorder末尾元素
postorder.resize(postorder.size()-1);
//依然是左闭右开,这里使用了左中序的长度作为切割点
//[0,leftInorder.size())
vector<int>leftPostorder(postorder.begin(),postorder.begin()+leftInorder.size());
//[leftInorder.size(),end)
vector<int>rightPostorder(postorder.begin()+leftInorder.size(),postorder.end());
//第六步,递归处理左右区间
root->left=traversal(leftInorder,leftPostorder);
root->right=traversal(rightInorder,rightPostorder);
return root;
}
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if(!inorder.size()||!inorder.size())return nullptr;
return traversal(inorder,postorder);
}
};利用下标分割数组的方法:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
TreeNode* traversal(vector<int>& inorder,int inorderBegin,int inorderEnd,vector<int>& postorder,int postorderBegin,int postorderEnd){
//第一步,判断后序数组是否为空
if(postorderEnd==postorderBegin)return NULL;
//第二步,在后续数组中找到末尾数,构造树
int rootValues=postorder[postorderEnd-1];
TreeNode* root=new TreeNode(rootValues);
//叶子节点
if(postorderEnd-postorderBegin==1)return root;
//第三步,在中序数组中找到切割点
int delimiterIndex;
for(delimiterIndex=inorderBegin;delimiterIndex<inorderEnd;delimiterIndex++){
if(inorder[delimiterIndex]==rootValues)break;
}
//第四步,在中序数组中分左右组
//左组(左闭右开)
int leftInorderBegin=inorderBegin;
int leftInorderEnd=delimiterIndex;
//右组
int rightInorderBegin=delimiterIndex+1;
int rightInorderEnd=inorderEnd;
//第五步,在后序数组中分左右组
//左组
int leftPostorderBegin=postorderBegin;
int leftPostorderEnd=postorderBegin+delimiterIndex-inorderBegin;
//右组
int rightPostorderBegin=postorderBegin+delimiterIndex-inorderBegin;
int rightPostorderEnd=postorderEnd-1;
//第六步,递归遍历
root->left=traversal(inorder,leftInorderBegin,leftInorderEnd,postorder,leftPostorderBegin,leftPostorderEnd);
root->right=traversal(inorder,rightInorderBegin,rightInorderEnd,postorder,rightPostorderBegin,rightPostorderEnd);
return root;
}
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if(inorder.size()==NULL||inorder.size()==NULL)return NULL;
return traversal(inorder,0,inorder.size(),postorder,0,postorder.size());
}
};













 2840
2840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









