










强化学习太有魔力了!!
原文
中文下载链接md格式
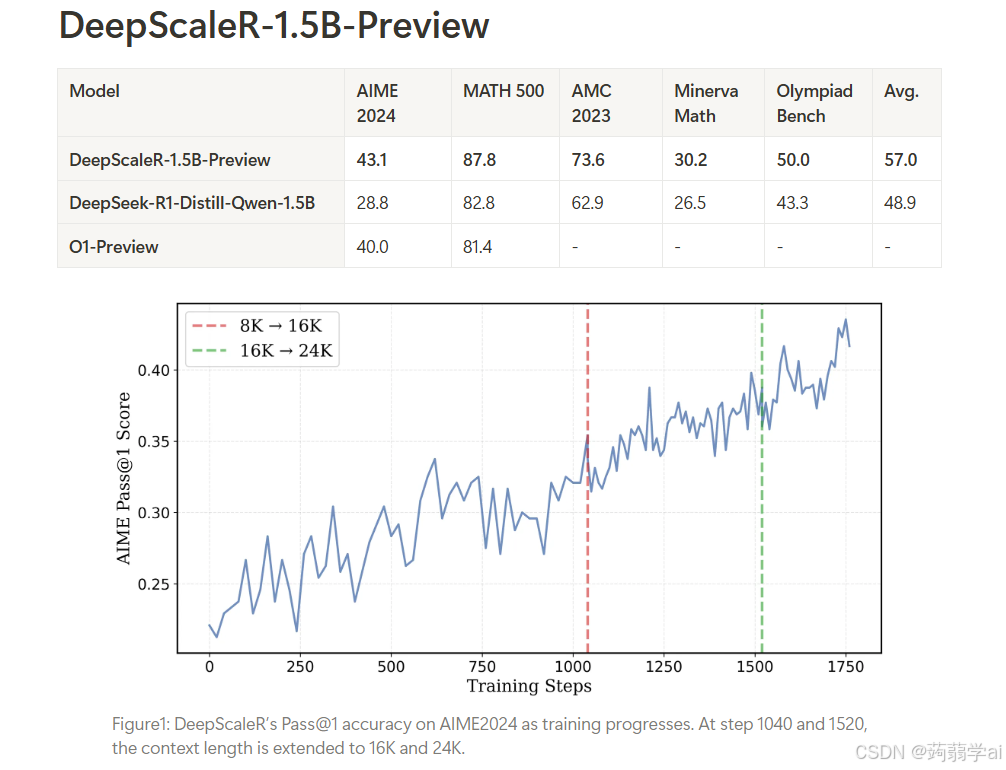
RL魔法在空气中弥漫!我们隆重推出DeepScaleR-1.5B-Preview,这是一款基于Deepseek-R1-Distilled-Qwen-1.5B并通过简单强化学习(RL)进行微调的语言模型。它在AIME2024上实现了令人瞩目的43.1% Pass@1准确率(相比基础模型提升了14.3%),以仅1.5B的参数规模超越了OpenAI的o1-preview表现。为了更好地推动RL在智能扩展领域的进步,我们开源了数据集、代码及训练日志,期待与全球开发者共同探索前进!
译文如下:
介绍
近日,Deepseek-R1(一款与OpenAI的o1相媲美的模型)的开源发布,标志着在普及推理模型方面取得了重大进展。然而,其精确的训练方法、超参数以及底层系统仍未公开。在本研究中,我们朝着完全开放的训练方案迈出了一大步,旨在为推理模型扩展强化学习(RL)的应用。
扩展RL面临的最大挑战之一是高昂的计算成本。例如,我们发现直接复现DeepSeek-R1的实验(⩾32K上下文,约8000步)至少需要70,000个A100 GPU小时——即使对于1.5B参数的模型也是如此。为了解决这一问题,我们采用了蒸馏模型,并引入了一种新颖的迭代扩展方案,将计算需求大幅降低至仅3,800个A100 GPU小时——减少了18.42倍——同时仅用1.5B参数的模型就实现了超越OpenAI o1-preview的性能。
我们的研究证明,通过RL开发定制化推理模型不仅可以实现规模化,还可以显著降低成本。在接下来的内容中,我们将详细介绍数据集构建与训练方法,展示评估结果,并分享从研究中得出的关键见解。
DeepScaleR 的秘诀
数据集构建
对于我们的训练数据集,我们整合了1984-2023年的AIME题目以及2023年之前的AMC题目,同时还采用了来自Omni-MATH和Still数据集的问题,这些数据集涵盖了来自全球各地数学竞赛的题目。
我们的数据处理流程包括三个关键步骤:
- 答案提取:对于AMC和AIME等数据集,我们使用gemini-1.5-pro-002从官方AoPS解答中提取答案。
- 去除冗余问题:我们采用RAG(Retrieval-Augmented Generation)技术,结合sentence-transformers/all-MiniLM-L6-v2的嵌入向量,去除重复问题。为了防止数据污染,我们还检查了训练集与测试集之间的重叠部分。
- 过滤不可评分问题:某些数据集(如Omni-MATH)包含无法通过sympy自动评分的问题,需要借助LLM(大语言模型)进行评判。由于使用LLM评判可能会拖慢训练速度并引入噪声奖励信号,我们额外增加了一个过滤步骤,剔除这些不可评分的问题。
经过去重和过滤后,我们的最终训练数据集包含了约40,000个独特的问题-答案对。我们将在未来的扩展中进一步丰富数据集的内容。
奖励函数
正如Deepseek-R1所倡导的,我们采用**结果奖励模型(ORM)**而非过程奖励模型(PRM),以避免奖励作弊的风险。简而言之,我们的奖励函数规则如下:
- 1 - 如果LLM的答案通过基本的LaTeX/Sympy检查。
- 0 - 如果LLM的答案错误或格式不正确(例如缺少、分隔符)。
在扩展RL用于推理任务时,一个关键的挑战是选择最佳的训练上下文窗口大小。推理任务的计算强度极高,因为它们生成的输出比标准任务长得多,这会拖慢轨迹采样和策略梯度更新的速度。将上下文窗口大小翻倍至少会使训练计算量增加2倍。
这引出了一个基本的权衡:更长的上下文窗口为模型提供了更多思考空间,但同时会显著减缓训练速度;而较短的上下文窗口虽能加速训练,却可能限制模型解决需要较长上下文的复杂问题的能力。因此,在效率与准确性之间找到合适的平衡至关重要。
总结来说,我们的训练方案采用Deepseek的GRPO算法,并遵循以下两步:
第一步:我们在8K最大上下文窗口下进行RL训练,以实现更高效的推理和训练。
第二步:我们将训练扩展到16K和24K上下文窗口,使模型能够解决更具挑战性、以往无法解决的问题。
用8K上下文引导有效的思维链(CoT)
在启动完整训练之前,我们首先对Deepseek-R1-Distilled-Qwen-1.5B在AIME2024上的表现进行了评估,并分析了轨迹统计数据。我们发现,错误回答的token数量平均是正确回答的三倍(20,346 vs. 6,395)。这表明,过长的回答往往会导致错误结果。因此,直接使用长上下文窗口进行训练可能效率低下,因为大多数字符实际上被浪费了。此外,我们在评估日志中发现,冗长的回答表现出重复的模式,说明它们并未对有效的思维链(CoT)推理做出实质性贡献。
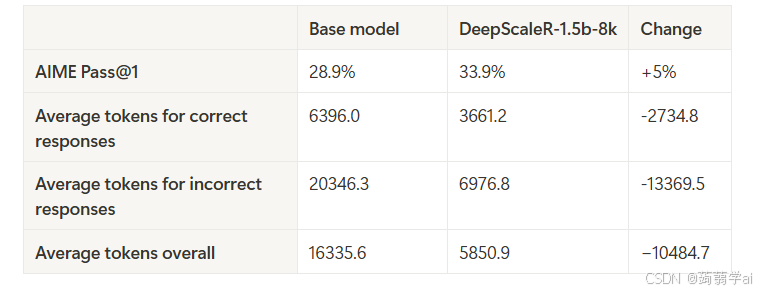
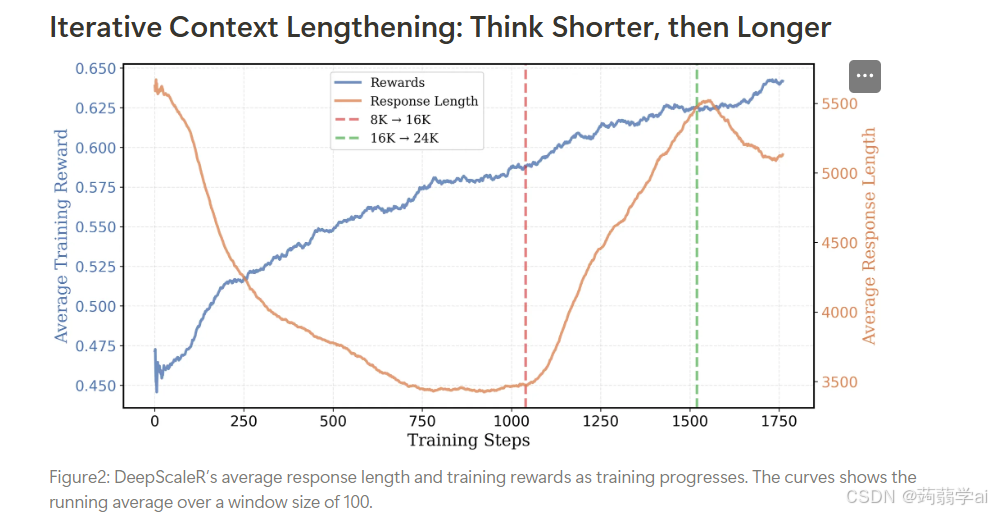
基于这一发现,我们以8K上下文窗口启动训练,初始在AIME2024上的准确率达到22.9%——仅比原始模型低6%。这一策略被证明是有效的:在训练过程中,平均训练奖励从46%提升至58%,而平均回答长度从5,500 token下降至3,500 token(见图2)。更重要的是,将输出限制在8K token内,使模型能够更有效地利用上下文。如图所示,我们的模型无论对于正确还是错误回答,都生成了显著更短的输出,同时在AIME准确率上超越了基础模型5%——且仅使用了三分之一的token。
在转折点扩展至16K上下文窗口
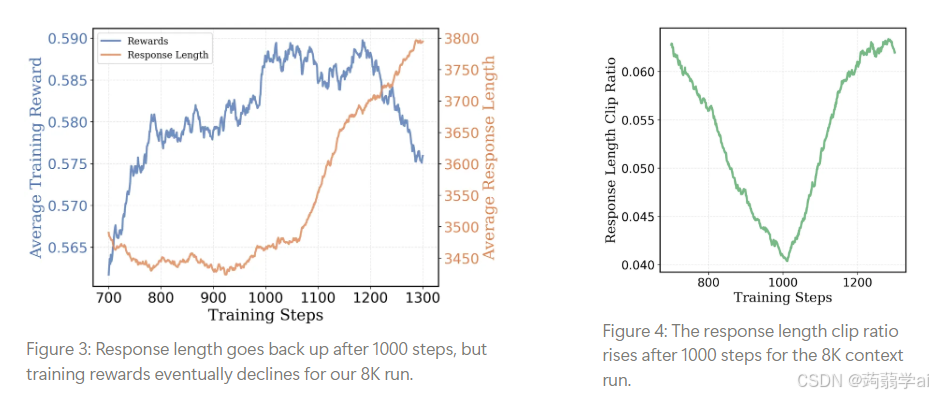
经过约1,000步训练后,我们观察到8K上下文窗口实验中出现了有趣的转折:响应长度开始再次增加。然而,这种增长并未带来预期收益——准确率曲线逐步趋平并最终下降。与此同时,响应截断率从4.2%攀升至6.5%,表明更多响应被上下文长度限制所截断。这些结果显示,模型试图通过"延长思考"来提升训练奖励。但随着生成的响应逐渐变长,它越来越频繁碰触到8K上下文窗口的上限,从而限制了进一步提升的空间。
我们视此为自然转折点,决定"打开笼门,任鸟高飞"。选择在第1,040步时的检查点(响应长度开始趋势性上升的节点),重新启动训练时扩展使用16K上下文窗口。这种两阶段训练法相比从零开始直接训练16K上下文模型显著提升效率:通过8K阶段的引导,平均响应长度保持在3,000 token而非9,000,使当前阶段训练速度至少提升2倍。
切换上下文窗口后,我们观察到训练奖励、响应长度及AIME准确率均保持持续提升。经过额外500步训练,平均响应长度从3,500 token增至5,500 token,AIME2024 Pass@1准确率达到38%。
施展24K进阶魔法,超越O1预研版
在16K上下文窗口下继续训练500步后,我们注意到性能提升趋于停滞——平均训练奖励收敛于62.5%,AIME Pass@1准确率在38%附近徘徊,响应长度也再度呈下降趋势。此时,最高响应截断率已逐步攀升至2%。
为实现对O1版本性能的最终突破,我们决定启用"24K进阶魔法"——将上下文窗口扩展至24K。我们选取16K训练阶段第480步的检查点,重新启动24K上下文窗口训练。
借助扩展的上下文窗口限制解除,模型终获全面突破。经过约50步训练,模型AIME准确率成功突破40%大关,并在第200步时达到43%。"24K进阶魔法"效果显著!
整个训练过程累计约1,750步。初始8K阶段采用8张A100 GPU进行训练,16K和24K阶段扩大至32张A100 GPU。总计耗资约3,800 A100小时,按32卡配置折合约5天训练时长,对应计算成本约4,500美元。
评估
我们在竞赛级数学基准测试中对模型进行了评估,测试集包括AIME 2024、AMC 2023、MATH-500、Minerva数学及奥赛基准库。下表中报告的是Pass@1准确率,每个题目通过16次采样取平均。带下划线的基线分数为自行验证结果。
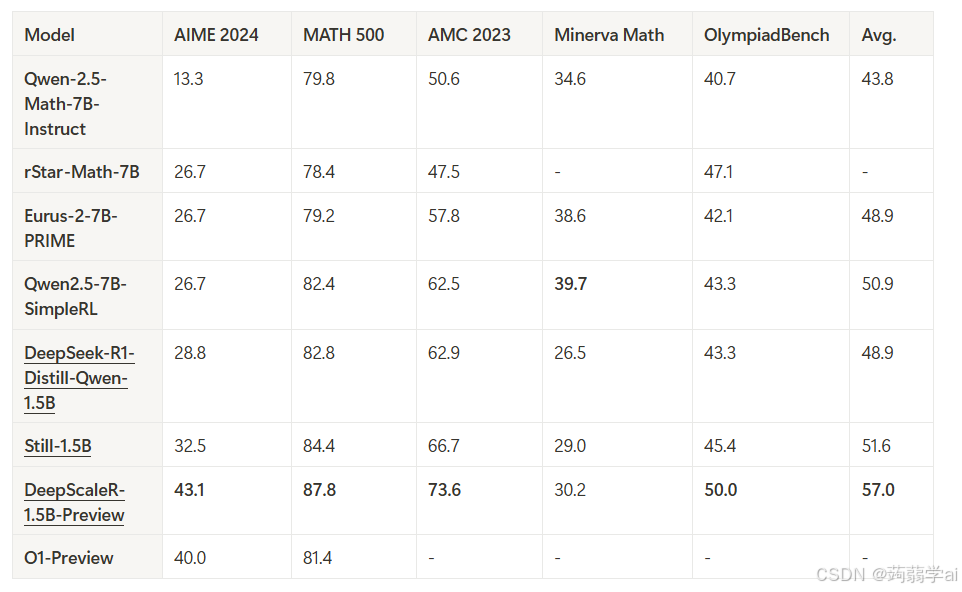
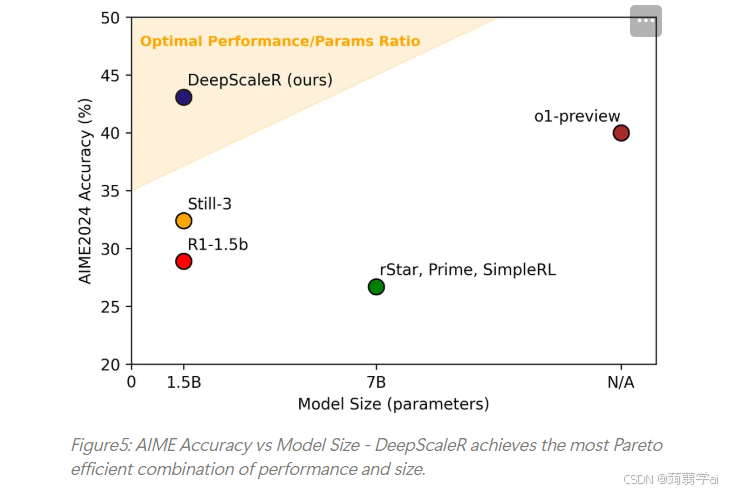
我们将DeepScaleR模型与基础DeepSeek模型,以及近期探索强化学习在推理任务中应用的学术成果进行对比。结果显示,DeepScaleR在所有基准测试中均显著超越基模型,其中AIME2024提升14.4个百分点,总体平均提升8.1%。与基于70亿参数模型的近期研究(如rSTAR、Prime、SimpleRL)相比,DeepScaleR同样展现出优势。如图5所示,DeepScaleR以仅15亿参数的体量达到了O1预研版本的性能水平,展现出卓越的效能提升。
核心洞见
小模型亦可受益于RL扩展效果。 Deepseek-R1研究发现直接对小模型进行强化学习训练效果弱于知识蒸馏应用——经消融实验显示,在Qwen-32B模型上使用强化学习在AIME测试集仅获得47%准确率,而单纯蒸馏即达72.6%。这折射出普遍认知误区,认为强化学习的规模效应仅适用于大模型。但实验显示,通过从更大模型蒸馏获得优质监督微调数据后,小模型同样能有效借助强化学习提升推理能力。本研究结果印证了该结论:强化学习训练将AIME准确率从28.9%提升至43.1%。这些发现表明,单靠监督微调或强化学习均非最优解,只有将高质量SFT蒸馏与RL扩展有效结合,才能真正释放大语言模型的推理潜力。
迭代延伸策略催生更高效的长度扩展。 已有研究[1、2]指出,直接进行16K上下文窗口的强化学习训练相比8K窗口无明显提升,可能源于算力不足使模型无法充分利用扩展语境。近期的研究[3]则表明过长的回答可能包含冗余的自我思考,最终导致错误结论。本文实验结果与这些观点一致。通过先在短上下文窗口(8K)优化模型推理能力,使后续16K、24K窗口训练更高效。这种迭代渐进的策略让模型在扩展上下文前建立了有效思维模式,从而使基于强化学习的长度扩展更具效率。
结语
本研究旨在揭示强化学习对大语言模型的规模效应,并向开源社区分享相关实践。DeepScaleR-1.5B-Preview是我们首款成果模型,以**43.1%**的Pass@1准确率超越o1-preview版本。我们坚信推广强化学习扩展应用需社区共同努力,热忱欢迎开源贡献与资源支持!让我们携手拓展大模型推理的强化学习前沿!
思考
RL+大模型+特定场景是不是也能做一些工作呢



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











