









摘要
设计有效的数据操作方法一直是数据湖中的一个长期问题。传统方法依赖于规则或机器学习模型,这需要大量的人力投入用于训练数据的收集和模型的调整。最近的方法应用大语言模型(LLMs)来解决多个数据操作任务。它们在性能方面展现出显著的优势,但仍然需要定制化的设计以适应每个具体任务。这非常昂贵,无法跟上大数据湖平台的需求。本文受到LLMs在自然语言处理任务中跨任务通用性的启发,迈出了设计一种自动化和通用解决方案以应对数据操作任务的第一步。我们提出了UniDM,一个统一的框架,建立了利用LLMs处理数据操作任务的新范式。UniDM以统一的形式正式化多个数据操作任务,并抽象出三大通用步骤来解决每个任务。我们开发了一种自动上下文检索机制,使LLMs能够从数据湖中检索数据,这些数据可能包含证据和事实信息。对于每一步,我们设计了有效的提示来指导LLMs生成高质量的结果。通过在各种基准上的综合评估,我们的UniDM展现了极好的通用性和在多种数据操作任务上的最先进性能。
1 引言
数据湖是一个用于存储大量异构模式和结构数据的一般系统。它提供了一个高效的接口,允许用户使用各种工具管理和操作数据。用户可以根据其应用灵活定义不同的工作流程,以清洗、集成、解释和分析数据(Nargesian et al., 2019; Ouellette et al., 2021)。这一优势促进了用户对数据处理的定制需求,但也带来了显著的缺点。对于任何新应用,相应的数据处理工作流程需要从头开始由专家重新设计和调整。这是非常昂贵的,无法跟上可能每天在大数据湖平台上出现的新应用(Hai et al., 2021)。文献工作已经投入了相当多的研究精力,旨在设计可适用于数据湖中不同数据操作任务的自动化和通用方法。
传统的基于规则的方法(Dalvi et al., 2013; Singh et al., 2017; Chu et al., 2013; 2015; Dallachiesa et al., 2013; Mayfield et al., 2010; Jin et al., 2020)需要为每个数据任务构建专门的模型和调整规则,自动化程度不足。最近的工作应用机器学习(Bilenko & Mooney, 2003; Konda et al., 2016; Heidari et al., 2019; Biessmann et al., 2019; Li et al., 2021a;b; Wu et al., 2021; Alserafi et al., 2019),特别是深度学习技术(Mudgal et al., 2018; Ebraheem et al., 2018; Zhao & He, 2019; Deng et al., 2022),为每个任务学习自适应解决方案。然而,它们的性能在很大程度上依赖于训练模型的质量,这需要大量标记的训练数据和与每个任务相关的特定领域知识。最近,大语言模型(LLMs),如BERT(Devlin et al., 2018)、GPT-3(Brown et al., 2020)和LaMDA(Thoppilan et al., 2022),在广泛的下游任务上表现出惊人的性能(Zhou et al., 2023; Liang et al., 2022)。LLMs通常是具有变换器架构的深度神经网络(Vaswani et al., 2017)。它们在大量文本语料上进行预训练,以学习通用的世界知识。在自然语言处理任务中,LLMs展现了显著的跨任务通用性。这是因为自然语言处理领域积累了几十年的经验,以设计标准范式来统一和解决不同的自然语言处理任务(Radford et al., 2019; Brown et al., 2020)。
然而,对于数据操作任务,相关经验几乎为空,这使得这个问题变得极具挑战性。为了解决这个问题,我们需要回答以下两个关键问题:1)如何设计一个框架优雅地统一不同的数据操作任务?这个框架应该足够通用,涵盖在数据湖应用中常见和新的任务,并容易将LLMs纳入解决方案。2)如何在这个统一框架下设计一个通用解决方案?这个解决方案应该包含适应不同任务的抽象过程,同时最大限度地发挥LLMs的有效性。
我们的贡献:在本文中,我们迈出了朝着解决这一问题的第一步。我们提出了UniDM,一个被验证在多种数据湖数据操作任务中达到最先进性能的统一解决方案。具体而言,我们做出了以下贡献:1)我们提出了一个统一框架来描述数据操作任务。我们将数据操作任务
T
T
T 正式化为一个函数
F
T
(
)
F_T()
FT(),以处理数据湖中数据表
D
D
D 上的一些记录
R
R
R 和属性
S
S
S。我们展示了这个框架涵盖了许多常见的结构化数据任务,并且可以轻松扩展到新的复杂任务,甚至是非结构化数据。 (在第3节)2)我们抽象出使用LLMs解决不同任务的通用程序。我们观察到,解决数据操作任务的关键是找到合适的提示,以激发LLMs产生准确的结果(Wang et al., 2022)。然而,由于任务的复杂性,直接通过单一提示请求LLMs的最终结果既困难又无效(Narayan et al., 2022)。因此,我们将一个可以通过我们统一框架描述的数据操作任务分解为几个一致的步骤,使得每个步骤对LLMs来说都是简单、直接且容易的工作。
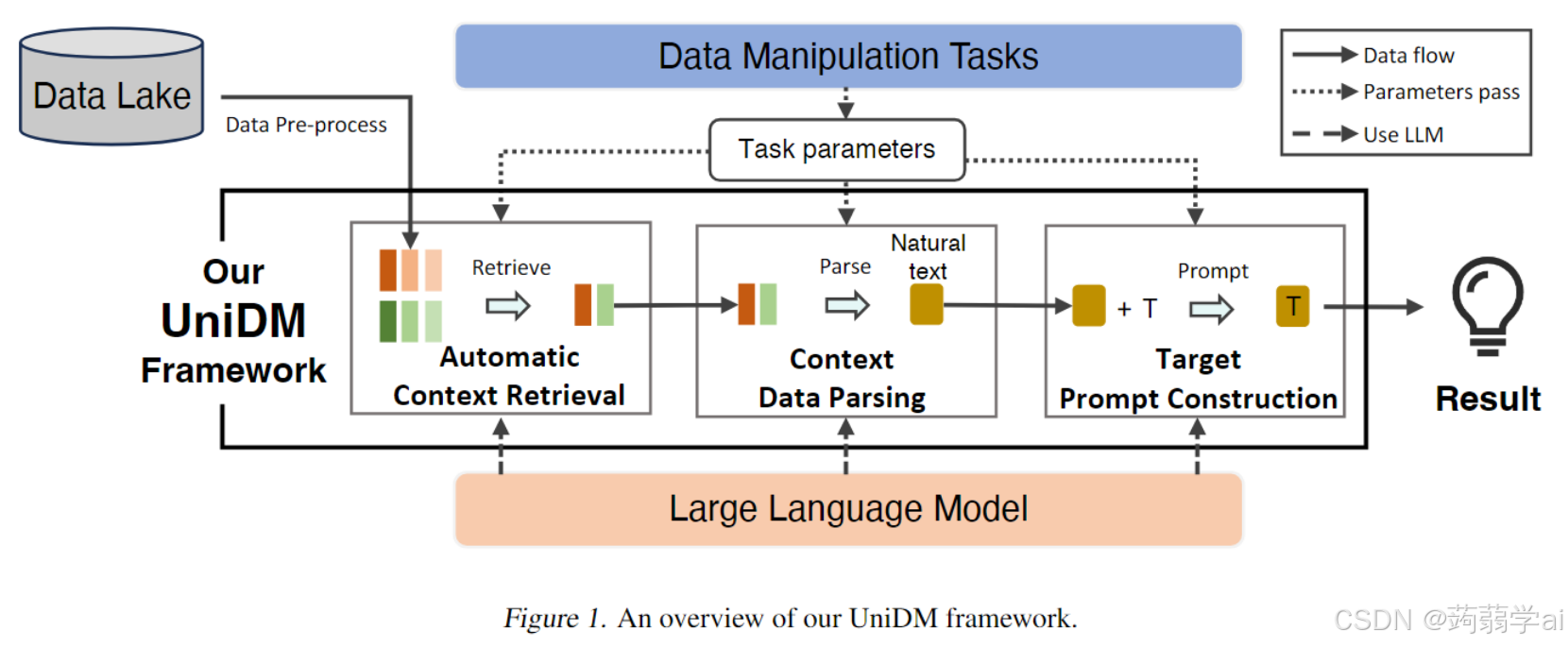
如图1所示,我们的解决方案包含三个主要步骤。第一步自动提取来自数据表的相关上下文信息,以作为解决任务的示范或背景知识。第二步将上下文信息从表格形式转换为逻辑文本,以便LLMs更容易捕捉其语义。最后,第三步应用提示工程来构建目标提示,以获得最终结果。通过这种方式,我们在不同任务之间实现了通用性,并提高了LLMs的有效性。(在第4节)3)我们为解决方案中的每个主要步骤设计了有效的(模板)提示。对于每个主要步骤,我们抽象出需要从LLMs中获取的知识,并设计一个通用的提示模板,以自动提取这种知识。这样,LLMs能够在每个步骤中表现良好,从而提高最终结果的质量。(在第4节)4)我们进行了广泛的实验,以评估我们的解决方案UniDM的性能。对许多基准的评估结果表明,UniDM在多种数据操作任务中达到了最先进的结果,包括数据插补、数据转换、错误检测和实体解析。同时,UniDM中每个主要步骤的有效性也通过消融研究得到了验证。(在第5节)
2 背景与动机
大语言模型和提示:大语言模型(LLMs)可以被视为适用于众多任务的基础模型,特别是需要解释数据语义的任务。与其对模型进行微调以适应每个任务,我们可以简单地应用提示来引导LLMs解决每个任务。具体而言,提示是用自然文本编写的直观接口,与LLMs进行交互。它可以采取多种形式(例如短语或复杂句子),以引导或要求LLMs提取其知识来执行许多不同的工作,如代码生成、问答、创意写作等。例如,一个简单的提示,如“将英语翻译成法语:hello =>”,可以直接进行语言翻译。LLMs的性能对提示非常敏感(Brown et al., 2020)。为了获得高质量的结果,我们通常设计带有上下文信息的提示,以向LLMs提供更多指令。上下文信息可以是一些输入/输出示例或与任务相关的其他信息。当与任务描述结合时,LLMs会有更多背景知识,从而提取更准确的知识来回答问题。例如,对于提示“填写值,如 Genre: Folk; Artist: Bob Dylan. Genre: Jazz; Artist: ?”,LLM会模仿示例找到一位爵士艺术家,例如“Bill Evans”,作为结果。
LLMs在数据任务中的应用:一些非常新的研究(Mohammad et al., 2023; Brunner & Stockinger, 2020; Li et al., 2020; Mei et al., 2021; Chen et al., 2023; Narayan et al., 2022; Wang et al., 2022; Trummer, 2022a;b)观察到将LLMs引入一些数据操作任务的潜在好处。例如,我们可以要求LLMs自动判断一个值对于某个属性是否有效,而不是为每个领域设计大量的错误检测规则。先前的研究(Herzig et al., 2020; Liu et al., 2021; Peeters & Christian, 2021; Trummer, 2022a)已经验证了将LLMs应用于数据表问题解答的有效性。后来,LLMs也被应用于数据预处理任务(Li et al., 2020)、表格上的二元分类(Stefan et al., 2022)、数据清洗和集成任务(Mohammad et al., 2023; Narayan et al., 2022)。这些研究提供了足够的证据,表明基于LLM的方法在这些任务上可以达到非常有前景的,有时甚至是最先进的性能。然而,即使避免了提供领域知识的人力投入,目前的基于LLM的方法在数据操作任务中并不普遍适用。这些方法的程序及其提示都是专门为每个任务设计的,要求用户手动提取定制的上下文信息来引导LLMs。LLMs的优势与现有方法的缺点激励我们提出以下问题:我们能否找到一个统一的解决方案,使其在数据湖中对不同的数据操作任务既通用又自动,且无需人工努力?
3 问题定义
在本节中,我们提出一个统一框架,以正式化我们在数据湖中要解决的数据操作任务。设 D = { D 1 , D 2 , … , D l } D = \{D_1, D_2, \ldots, D_l\} D={D1,D2,…,Dl} 为一个数据湖。在本文中,我们假设每个元素 D i ∈ D D_i \in D Di∈D 是一个包含多个记录(元组)的关系数据表。我们将表 D i D_i Di 的模式及其属性集表示为 S i S_i Si。与关系数据库不同,数据湖 D D D 中的表未指定连接关系。对于任何记录 r r r 和属性 s s s,我们用 r [ s ] r[s] r[s] 表示 r r r 在 s s s 上的值。设 T T T 代表在 D D D 上的数据操作(例如数据清洗或集成)任务。我们假设任务描述和任务的参数(例如表上的问题)都编码在 T T T 中。我们可以将若干不同的任务以统一的方式正式化如下:
输入:一个数据湖 D D D,从表 D i ∈ D D_i \in D Di∈D 中提取的记录子集 R ⊆ D i R \subseteq D_i R⊆Di,模式 S i S_i Si 下的属性子集 S ⊆ S i S \subseteq S_i S⊆Si,以及目标任务 T T T;
输出:我们定义一个与任务 T T T 相关的函数 F T F_T FT,它生成一个值 Y = F T ( R , S , D ) Y = F_T(R, S, D) Y=FT(R,S,D)。对于每个不同的数据操作任务 T T T,函数 F T F_T FT 根据应用的不同而以不同的方式定义。我们列出一些在实际应用中常用并可被我们框架涵盖的示例任务如下:
-
数据插补:该任务旨在修复脏数据并填补记录中的缺失值。 S S S 包含 S i S_i Si 中的一个属性, R R R 包含在 D i D_i Di 中在属性 S S S 上具有缺失值的单条记录, F T ( R , S , D ) F_T(R, S, D) FT(R,S,D) 输出记录 R [ S ] R[S] R[S] 的期望缺失值。
-
数据转换:该任务是将记录中的数据从一种格式转换为另一种所需格式的过程。 S S S 包含 S i S_i Si 中的一个属性, R R R 包含在 D i D_i Di 中的单条记录, F T ( R , S , D ) F_T(R, S, D) FT(R,S,D) 根据用户指定的规则将原始值 R [ S ] R[S] R[S] 转换为另一个新值 R ′ [ S ] R'[S] R′[S]。
-
错误检测:该任务是在数据清洗系统中检测记录中的属性错误。 S S S 包含 S i S_i Si 中的一个属性, R R R 包含在 D i D_i Di 中的单条记录, F T ( R , S , D ) F_T(R, S, D) FT(R,S,D) 预测值 R [ S ] R[S] R[S] 是否正常。
-
实体解析:该任务是预测两个记录是否引用同一现实世界事物的过程。 S S S 包含描述 D i D_i Di 中每条记录属性的多个属性,且 R = { r 1 , r 2 } R = \{r_1, r_2\} R={r1,r2} 包含 D i D_i Di 中的两个不同记录, F T ( R , S , D ) F_T(R, S, D) FT(R,S,D) 输出这两条记录 r 1 r_1 r1 和 r 2 r_2 r2 是否指代同一现实世界实体。
值得注意的是,在我们提出的框架中,我们仅考虑数据湖中数据操作任务的基本形式。在接下来的内容中,我们将应用上述被框架涵盖的数据操作任务,以展示如何使用LLMs设计通用解决方案。同时,我们的框架可以轻松扩展以支持对非结构化或半结构化数据的新任务的丰富定义。
4 统一的数据操作框架
为了通用地支持常见的数据操作任务,我们提出了UniDM,一个基于LLMs的统一框架。我们首先在4.1节中分析这个问题并概述我们的解决方案。接着,4.2节到4.4节详细阐述我们方法中每个关键技术的细节。最后,在4.5节中讨论我们方法的通用性。
4.1 概述问题分析
回顾一下,我们可以通过提示来咨询LLMs,以获取所需的知识。数据操作任务也可以通过适当的提示来解决。如以下示例所示,我们应用两个简单的提示来解决数据插补和转换任务。这里每个提示都是一个自然语言的文本模板,包含:1)任务描述(用红色标记),以便LLMs理解需要完成的内容,例如填补缺失值或转换数据;2)上下文信息(用蓝色标记),作为演示或示例,引导LLMs执行任务,例如其他相关属性的信息或转换示例;3)占位符(用橙色标记),以提供任务的输入。
通过这样的结构化提示,LLMs能够更好地理解任务要求,并根据提供的上下文信息生成准确的输出。这种方法不仅提高了数据操作的效率,还增强了LLMs在处理不同任务时的灵活性和适应性。接下来的部分将深入探讨如何将这些技术应用于具体的任务解决方案。
Prompt A:Data Imputation: city:Copenhagen,country:Denmark, timezone:?
Prompt B: Data Transformation: 20210315 to Mar 15 2021, 20201103 to ?
已显示LLM结果的质量对提示格式非常敏感(Brown et al., 2020)。简单直接的提示(如上述两个示例)在数据操作任务中往往表现平平。这是因为LLMs通常是在训练语料上推理直接和简单事件,例如“x包含于y”或“y与z相同”,但可能在缺乏明确证据的复杂多跳推理问题上失败(Creswell et al., 2022),例如“x是否包含于z?”解决数据操作任务的过程对LLMs来说过于复杂,需要它们同时解释任务描述、提取(并可能转换)上下文信息,以及在占位符中填入适当的值。一些文献工作(Chen et al., 2023; Wang et al., 2022)致力于为某些特定的数据操作任务设计和调整提示。然而,这样的工作非常昂贵且不易扩展到每天出现的众多自定义任务。我们实际上需要的是一个通用解决方案,能够为每个不同的数据操作任务生成有效的提示。
我们的主要思想和解决方案:为了实现这个目标,我们将数据操作任务(在第3节中描述)分解为几个一致的步骤。UniDM的流程和架构如图2所示。每个步骤都是LLMs使用其证据和逻辑进行推理的简单直接的任务。在此基础上,对于每个步骤,我们抽象出需要从LLMs中获取的知识,并设计出一个通用的提示模板以提取这些知识。UniDM以数据湖中的数据为输入,以迭代和交互的方式执行数据操作任务。一般而言,UniDM在执行数据操作任务时分为三个主要步骤:
-
上下文检索:给定任务 T T T、记录 R ⊆ D i R \subseteq D_i R⊆Di 和属性 S ⊆ S i S \subseteq S_i S⊆Si 在数据湖 D D D 上,首先需要从 D D D 中提取相关的上下文信息 C C C 来解决 T T T。 C C C 可能包含来自其他记录和属性的额外信息,以引导LLMs捕捉任务 T T T 的语义。我们设计了两个提示模板来使用LLMs自动检索上下文信息。第一个提示 p r m prm prm 旨在检索元级信息,例如可能为任务 T T T 在属性 S S S 上提供有用知识的多个属性。基于其结果,第二个提示 p r i pri pri 确定与 R R R 相关的最有帮助的记录,以更细致的方式解决任务。之后,我们获得表格形式的上下文信息 C C C。
-
上下文解析:在表格形式中的原始上下文信息 C C C 通常不易被LLMs理解(因为LLMs主要训练用于解释自然语言文本)。因此,下一步是将原始上下文 C C C 转换为LLMs更易于理解的另一种形式。类似于之前的研究(Narayan et al., 2022),我们首先应用序列化函数将 C C C 转换为具有属性和值对的常规文本 V V V,例如“city:Florence, country:Italy”。然后,我们设计了一个提示模板 p d p pdp pdp 进一步将文本 V V V 转换为反映不同属性之间逻辑关系的自然文本 C ′ C' C′,例如“Florence是意大利的一个城市”。 C ′ C' C′ 更流畅,更接近自然语言,因此LLMs可以在其语料中找到更相关的信息,以便进行后续处理。
-
目标提示构建:最后,我们将序列化文本 C ′ C' C′、任务描述 T T T 和任务输入 R R R 与 S S S 结合起来,咨询LLMs以获得最终结果 Y Y Y。我们利用提示工程自动引出任何数据操作任务的提示。具体而言,所有由我们在第3节中统一框架描述的数据操作任务都可以等效地转化为填空题。填空题对LLMs友好,因为它用自然语言书写并包含占位符。为了自动生成合适的填空题,我们设计了一个提示模板 p c q pcq pcq,为LLMs提供一小组示范,其中每一对都是数据操作任务及其对应的填空题。这些示范包括任务特定和任务无关的示例,使得LLMs能够学习识别最适合任何任务的模板,以输出填空题 p a s p_{as} pas。目标提示 p a s p_{as} pas 被输入到LLMs中以获得最终结果 Y Y Y。
4.2 自动上下文检索
为了以更可解释和模块化的方式从数据湖中捕捉数据知识,我们为LLMs增强了一个自动上下文检索组件。我们要求上下文检索组件能够识别有用的信息,同时过滤无关数据,以便于LLMs的处理。以往的研究(Biessmann et al., 2019; Narayan et al., 2022)要求用户指定与任务相关的实例(记录)和属性,或基于属性值的相似性学习识别有用记录(Mei et al., 2021; Mohammad et al., 2023)。与之不同,我们设计了一种完全自动化的策略,通过LLMs的辅助提取有用的属性和记录。我们首先应用元级检索从整体视角寻找相关属性。然后,我们应用实例级检索以更详细的方式提取有用记录。
元级检索:在第一步中,我们提供了一些候选属性 S ′ S' S′,并要求LLMs为我们的任务 T T T 和目标属性 S S S 选择有价值的属性。LLMs可以利用其固有知识来衡量 S ′ S' S′ 和 S S S 之间的关系,并保留仅有前景的属性。这一步可以以粗粒度的方式过滤数据湖 D D D 中的无关信息。结果将包含有用的元级信息,描述这些属性的高层次领域知识。具体而言,我们使用以下模板构建提示 p r m prm prm:
Prompt prm:The task is [T ]. The target query is [Q]. The candidate attributes are [ s 1 , s 2 , . . . , s n s_1, s_2, ..., s_n s1,s2,...,sn]. Which attributes are helpful for the task and the query?
这里 T T T 是任务描述,例如“数据插补”。查询 Q Q Q 结合了我们在目标记录 R R R 和属性 S S S 上的输入,以用于任务 T T T。在数据插补中,我们将其表示为“记录 R R R 的主键,属性 S S S”,例如“Copenhagen, timezone”,以指示我们想要填补记录 R R R 的属性 S S S 的值。候选属性集 S ′ = S i − S = { s 1 , s 2 , … , s n } S' = S_i - S = \{s_1, s_2, \ldots, s_n\} S′=Si−S={s1,s2,…,sn} 包含表 D i D_i Di 中 S i S_i Si 的所有剩余属性。对于其他任务,查询 Q Q Q 的形式和集合 S ′ S' S′ 是不同的。我们将在第4.5节中保留详细信息。在本文中,我们不应用表 D j ≠ i D_{j \neq i} Dj=i 中的跨表属性,因为在 D i D_i Di 上的实验结果(见第5节)已经足够具有竞争力。我们用 S t S_t St 表示由LLMs返回的与任务相关的属性。在图2(左侧)的示例中,当给定任务描述“数据插补”和目标查询(属性)“timezone”时,LLMs选择了属性“country”来推断缺失值。
实例级检索:接下来,我们对记录进行细粒度过滤,以识别与目标记录 R R R 相关的记录。我们首先将 D i − R = { r 1 , r 2 , … , r m } D_i - R = \{r_1, r_2, \ldots, r_m\} Di−R={r1,r2,…,rm} 的数据缩小,以提供一组候选记录 R ′ R' R′,通过随机抽样来实现。之后,我们使用LLMs来检查 R ′ R' R′ 和 R R R 之间的相关性。相关性可以根据不同任务以不同方式进行解释。例如,对于数据插补,我们希望找到与目标记录 R R R 和属性 S S S 相似的记录,以找到缺失值。在错误检测任务中,我们可能想要获得反映领域值分布的记录,以确定目标值 R [ S ] R[S] R[S] 是否异常。我们仍然驱动LLMs根据提示 p r i pri pri 使用以下模板咨询语义知识,以衡量记录与目标任务的相关性得分:
Prompt pri:The task is [T ]. The target query is [Q]. To score the relevance (range from 0 to 3) of given instances based on the task and the query: { r 1 [ S t ] , r 2 [ S t ] , . . . , r m [ S t ] r_1[S^t], r_2[S^t], ..., r_m[S^t] r1[St],r2[St],...,rm[St]}
对于每个 r j ∈ R ′ r_j \in R' rj∈R′,我们仅保留 S t S_t St 中与任务相关的属性,因为其他属性被确定为对我们的任务无帮助。在检查完 R ′ R' R′ 中的所有记录(或达到时间限制)后,我们根据相关性得分对所有实例进行排序,并选择前 k k k 个实例 R t R_t Rt 作为下游程序的任务相关上下文 C C C。
4.3 上下文数据解析
上下文信息
C
C
C 以表格形式表示,这对LLMs解释其潜在语义并不友好,因为LLMs通常是在大量文本语料上进行训练的。为了解决这个问题,我们考虑如何将
C
C
C 转换为更有效的格式供LLMs使用。由于上下文中的所有记录
R
t
R_t
Rt 都在模式
S
t
S_t
St 下以规则结构组织,我们可以轻松地将
C
C
C 序列化为文本字符串。具体而言,设 ({(s, r[s]) | r \in R_t, s \in S_t}) 表示每个属性
s
s
s 及其在记录
r
r
r 中的值的所有对的集合。上下文信息
C
C
C 被无损编码。我们的 serialize() 函数直接连接所有对以生成文本
V
V
V。
以往的研究(Narayan et al., 2022)直接将文本 V V V 输入到LLMs中,作为我们任务的上下文信息。然而,我们进一步尝试将 V V V 中的对整合为反映不同属性之间关系的逻辑文本 C ′ C' C′。例如,在图2(中间),文本“country:Italy, timezone: Central European Time”被转换为“国家意大利位于中央欧洲时间时区”。显然,前者在任何文章中几乎不会出现,除了一些表格,而后者可能在训练语料中的某些科学文章中频繁出现。因此,提供 C ′ C' C′ 而不是 V V V 给LLMs,可以提高其推理时命中相关文本的概率,并产生更准确的结果。值得注意的是,将文本 V V V 转换为 C ′ C' C′ 对LLMs来说是一项简单的工作。不同属性之间的逻辑关系通常是常见且固定的,例如“一个城市位于一个国家的时区”,因此LLMs可以直接捕捉这样的知识。在我们的解决方案中,我们应用以下数据解析模板提示 p d p pdp pdp 来执行此任务。生成的上下文表示 C ′ C' C′ 将应用于后续程序。
Prompt p d p p_{dp} pdp: Given the data, convert the items into a textual format that encompasses all relevant information in a logical order: [ V \mathcal{V} V]
4.4 有效的目标提示构建
为了将LLMs应用于我们的任务,最终(也是最重要的)步骤是找到一个有效的提示,将任务描述 T T T、逻辑文本中的上下文信息 C ′ C' C′ 和编码输入记录 R R R 及属性 S S S 的查询 Q Q Q 结合在一起(在第4.2节中定义)。此外,我们希望找到提示的方法能够普遍适用于不同任务,以避免耗时的调优工作。我们观察到,所有由声明描述的任务(包含 T T T、 C ′ C' C′、 R R R 和 S S S)可以等效地总结为一个填空题(cloze question)。具体而言,填空题要求模型填入剩余文本(“澳大利亚和瑞士总共赢得了金牌。”)。填空题对LLMs友好,因为它用自然语言书写并包含占位符。例如,数据插补任务是填补 R [ S ] R[S] R[S] 的缺失值,而错误检测任务则是为值 R [ S ] R[S] R[S] 填入正常或异常的答案。因此,我们的问题是如何将不同任务的声明自动组织成一个合适的填空题。
当然,这需要UniDM捕捉我们声明中每个元素的语义,例如,哪个元素应该放在其他元素之前,并将它们组织成流畅的自然文本。与上下文数据解析类似,这项工作适合由LLMs本身来完成。我们应用以下提示 p c q p_{cq} pcq 来进行这种转换:
Prompt p c q p_{cq} pcq :
Write the claim as a cloze question.
Claim: The task is data imputation. The context is…
Cloze question: … China’s population is __.
Claim: The task is data transformation. The context is…
Cloze question: … The roman numeral III can be transformed to normal number __.
…
Claim: The task is [T ]. The context is [C′]. The target query is [Q].
Cloze question:
受到离散提示搜索方法(Gao et al., 2021; Arora et al., 2022)的启发,我们在提示 p c q pcq pcq 中提供了一些声明及其对应的填空题作为示范例子。声明和填空题的对包括:1)与我们常用任务(如数据插补和错误检测)相关的示例,这些示例已验证能产生准确结果;2)一些与任务无关的转换策略,这些策略已验证在不同任务中普遍适用。LLMs可以从这些示例中学习,以识别最合适的模板,将我们在特定任务上的声明转换为填空题 p a s p_{as} pas。通过这种方式,我们在生成提示时实现了高效性(在常见任务上)和跨任务通用性(在新任务和未见任务上)。我们只需根据应用定期维护示范示例,避免为每个即将到来的任务进行专门的提示设计。最后,我们将提示 p a s p_{as} pas 输入到LLMs中,以产生我们任务的最终答案。第5节中的实验结果表明,我们方法生成的提示在多种数据操作任务上非常有效。
4.5 对更多任务的泛化
我们的UniDM框架可以通过对查询 Q Q Q 的形式进行小幅调整,轻松推广到第3节中列出的其他任务,该查询编码目标记录 R R R 和属性 S S S,以及提示 p r m prm prm 中候选相关属性的集合 S ′ S' S′(在第4.2节中定义)。另一方面,我们的方法可以灵活地组合各种模块以应对不同任务。具体细节如下:对于数据转换任务,我们直接设置 Q = R [ S ] Q = R[S] Q=R[S] 以给出要转换的属性值。对于错误检测,我们将其表示为“S: R[S]?”以指示 R [ S ] R[S] R[S] 是否是属性 S S S 的有效值。对于实体解析,其中 R = { r 1 , r 2 } R = \{r_1, r_2\} R={r1,r2},我们将 Q Q Q 设置为“实体 A 是 r 1 r_1 r1,实体 B 是 r 2 r_2 r2”,以识别 r 1 r_1 r1 和 r 2 r_2 r2 是否指代同一实体。对于其他可以被我们在第3节中定义的框架涵盖的任务,我们也可以根据任务的语义调整参数和模块组合。
5 实验
在本节中,我们对不同的数据操作任务进行广泛的实验,以评估我们UniDM的泛化能力和质量。我们还对UniDM在更多数据类型和任务形式上的表现进行了深入分析。随后,我们提供了几个模型变体,以展示所提方法的有效性。
5.1 实验设置
实现细节:我们使用GPT-3-175B参数模型(Brown et al., 2020)(textdavinci-003)在OpenAI API(OpenAI, 2021)中实现我们的UniDM,作为未进行微调的LLM。此外,我们提供了开源LLMs GPT-J-6B(Ben & Aran, 2021)和LLaMA2-7B(LLaMA2, 2023)的微调结果。在我们的方法中,在默认设置下,我们应用第4.2节中提出的自动上下文检索方法。具体而言,我们在元级检索中从候选集合中提取一个属性(见第4.2节中的提示 ( prm )),并在实例级检索中从数据集中随机抽样的50条记录中提取前3条记录(见第4.2节中的提示 ( pri ))。
评估任务和数据集:我们在多个不同的数据操作任务上评估UniDM,包括数据插补、数据转换、错误检测和实体解析。我们在不同的基准数据集上评估我们方法的性能。对于数据插补,我们选择了两个具有挑战性的基准数据集,即Restaurants和Buy(Mei et al., 2021)。在Restaurants数据集中,目标插补属性为“city”;在Buy数据集中,目标插补属性为“manufacturer”。我们手动掩盖目标属性中的值,缺失值的真实信息是可用的。对于数据转换,我们遵循TDE基准(Yeye et al., 2018),选择两个数据集,即StackOverflow和Bing-QueryLogs。该基准涵盖了多种类型的转换任务(例如,IP、地址、电话等)。对于错误检测任务,我们选择在数据清洗论文中广泛使用的Hospital和Adult数据集(Rekatsinas et al., 2017; Heidari et al., 2019)。错误占总数据的5%。所有单元格的真实信息均可用。对于实体解析,我们遵循标准的Magellan基准(Konda et al., 2016),选择四个跨不同领域的数据集。每个数据集由来自相同模式的两个结构化表中的候选对组成。实体对的真实标签(正面或负面)是可用的。
基线方法:我们将UniDM与多种最先进(SOTA)方法进行比较,评估数据操作任务的性能。FM方法(Narayan et al., 2022)在多个数据操作任务中表现出SOTA性能,采用简易的提示学习方式。我们遵循原始论文及其开源代码重现FM。在其默认设置中,上下文信息和目标提示由引导规则手动选择,并且仅在上下文数据解析中应用序列化。我们在数据插补、数据转换、错误检测和实体解析任务上评估FM。我们还重现了FM的随机抽样版本,其中记录的上下文信息是从表中随机选择的。对于数据插补任务,我们选择了几种遵循不同技术流程的方法,包括基于统计的方法HoloClean(Rekatsinas et al., 2017; Wu et al., 2020)、基于聚类的方法CMI(Shichao et al., 2008)和基于深度学习的方法IMP(Mei et al., 2021)。对于数据转换任务,我们选择了基于搜索的方法TDE(Yeye et al., 2018)。对于错误检测任务,我们选择了两种基于机器学习的方法HoloClean(Rekatsinas et al., 2017)和HoloDetect(Heidari et al., 2019)。对于实体解析任务,我们使用基于深度学习的方法Ditto(Li et al., 2020)。
评估指标:遵循以往的研究,我们采用广泛使用的指标,包括准确率、精确率、召回率和F1-score来评估这些方法的有效性。对于数据插补和数据转换,我们使用准确率表示在标记数据中进行的修复总数中正确修复的比例。对于错误检测和实体解析,我们使用基于精确率和召回率的F1-score。
评估目标:实验结果主要回答以下问题:
- 我们的UniDM解决方案在不同数据操作任务上的表现如何?(在第5.2节中)
- UniDM解决方案中每个组件的贡献是什么?(在第5.3节中)
5.2 性能评估
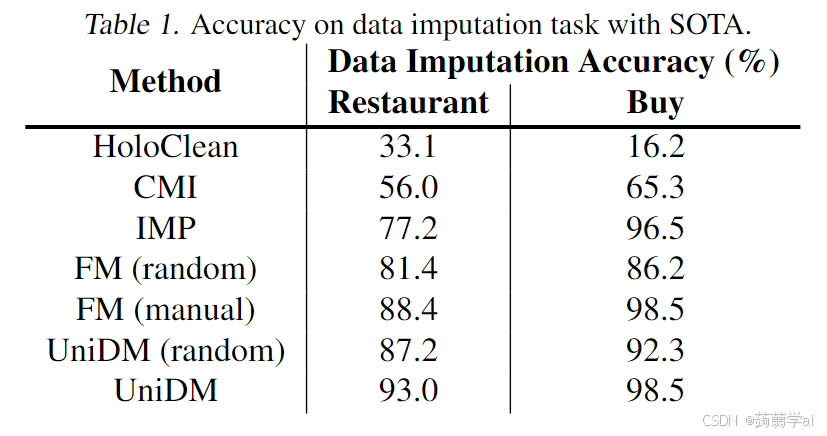
数据插补:如表1所示,我们进行实验以比较UniDM与其他方法的性能。在这里,我们还比较了UniDM和FM在另一种设置下的表现,其中记录的上下文信息是从表中随机选择的。我们发现:1)总体而言,UniDM的准确率显著高于SOTA结果。尽管FM采用了成本高昂的手动上下文信息选择,UniDM在Restaurants数据集上的准确率仍比FM高4.6%,在Buy数据集上表现相当。这验证了我们UniDM解决方案的有效性,特别是在上下文信息的自动检索方面。2)对于随机设置,从表中随机选择相同的上下文信息,UniDM在Restaurants数据集上仍比FM高出5.8%,在Buy数据集上高出6.1%。这是因为UniDM对上下文信息进行了逻辑转换,而不仅仅是简单的序列化,这在FM中使用。同时,UniDM通过利用LLM中的知识搜索最有效的目标提示,而不是由用户简单构造。这验证了我们在上下文数据解析和目标提示构建的设计选择的成功。
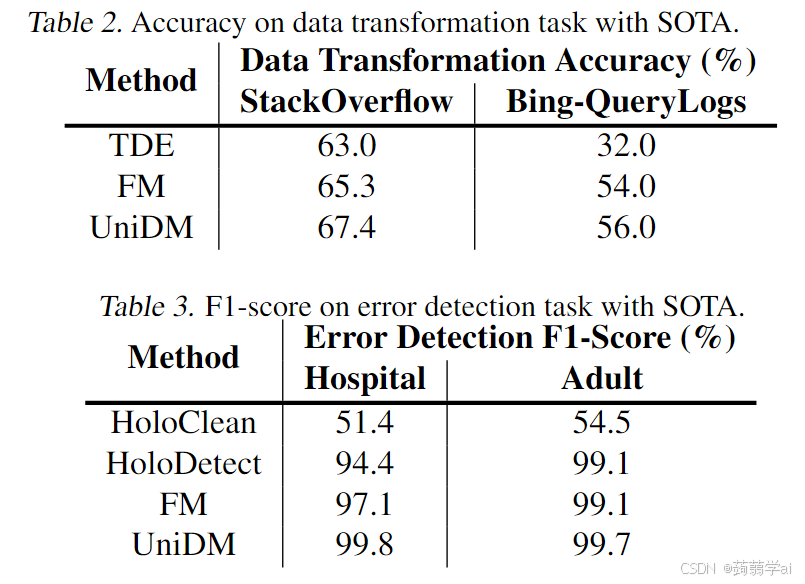
数据转换:UniDM在数据转换任务上也取得了最有前景的结果。如表2所示,UniDM超越了基于搜索的方法TDE和基于LLM的FM。与FM(当前SOTA结果)相比,UniDM在两个数据集上的准确率提高了近2%。上述实验中分析了原因。这也验证了基于LLM的方法相较于其他方法的优势。
错误检测:我们报告了UniDM和竞争方法获得的F1-score。UniDM在错误检测任务上也表现出类似的行为。如表3所示,UniDM在Hospital数据集上比基线方法Holo-Clean、HoloDetect和FM的F1-score高出最多2.7%。在Adult数据集中,UniDM获得了99.7%的高F1-score,因为它使用了数据源的信息。这证明我们的方法在解释领域知识以检测错误方面是有用的。
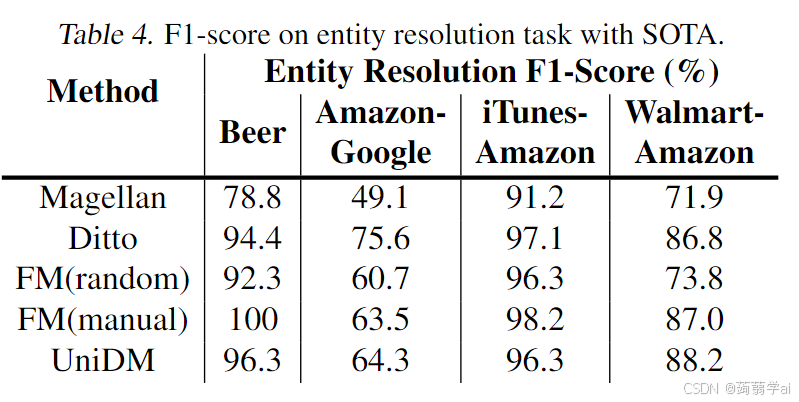
实体解析:如表4所示,UniDM在实体解析任务上也有效。与随机上下文信息的FM相比,UniDM的准确率始终更高(或至少相当)。与在大量任务特定标注数据上微调模型的Magellan和Ditto相比,UniDM在大多数情况下仍能取得相当或更好的结果。有时,UniDM的准确率低于Ditto和使用手动选择上下文的FM。这是因为这些数据集包含非常特定的领域词汇,这些词汇在语料库中不常出现。因此,LLMs对它们的语义知识较少,可能在推理中出现错误。在(Narayan et al., 2022)中也观察到了类似现象。为了避免这种情况,Ditto利用领域数据对模型进行微调,而FM手动选择实例以学习领域知识。
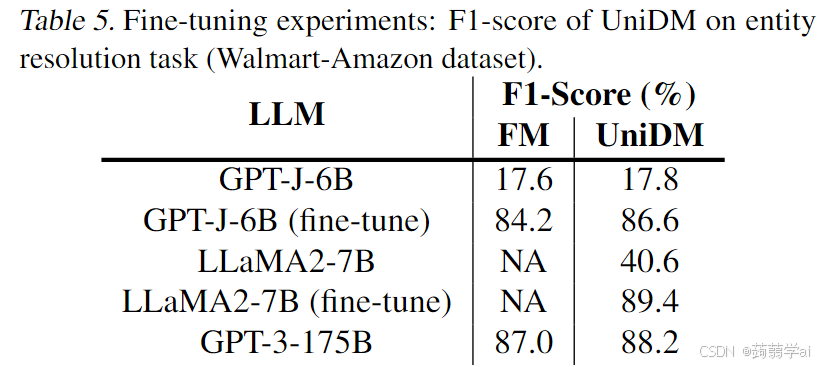
为了公平起见,我们还对我们的UniDM进行了轻量级微调,作为LLMs模型容量扩展,特别针对实体解析任务。我们基于HuggingFace(Wolf et al., 2020)库进行轻量级微调实验。在这种设置下,我们冻结了大部分预训练参数,并用一个小的可训练头(Ding et al., 2021)增强模型。在微调过程中,我们使用了WalmartAmazon数据集的训练集,该数据集由6144个元组组成。在微调期间,我们使用了AdamW优化器和余弦退火学习率调度器,线性预热步骤为100,初始学习率为4e-5,最终学习率为1e-5。我们的模型在8个V100 GPU上训练了30个周期,批量大小为16。我们还在相同设置下重现了FM的这一实验。我们将LLMs的参数规模从175B缩小到6B/7B。如表5所示,经过微调的6B/7B LLM在性能上与更大175B模型相当,表明UniDM有潜力扩展到更小的模型,且经过适当的微调。同时,在微调的小模型上,UniDM的表现优于FM。这表明我们的UniDM也可以通过微调达到更高的准确率。
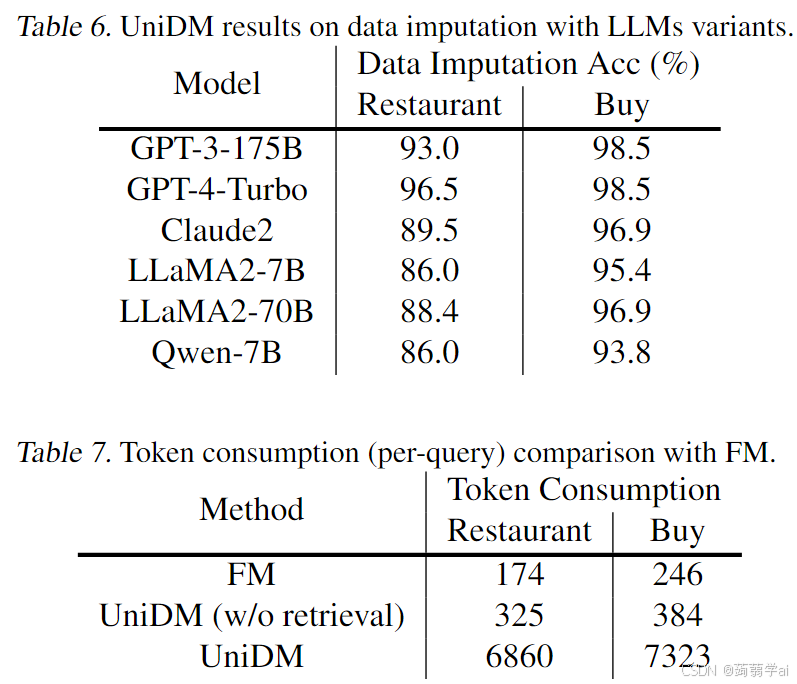
为了展示我们UniDM在不同基础模型上的性能,我们进一步在数据插补任务上评估了五个LLM变体:GPT-4-Turbo(OpenAI, 2021)、Claude2(约100B)(Claude2, 2023)、LLaMA2(7B和70B)(LLaMA2, 2023)以及Qwen-7B(Qwen, 2023)。我们观察到在这些不同基础LLM上,UniDM始终保持高性能,展示了其适应性和鲁棒性。如表6所示,即使在7B模型上,我们的UniDM也保持了令人印象深刻的表现,并且在更大的模型上能够以更高的成本获得更好的结果。在表7中,我们比较了FM和我们的UniDM之间的LLMs令牌消耗。显然,我们的方法的令牌消耗比FM更高。然而,我们的UniDM自动化了上下文检索和目标提示构建的过程,这显著减少了人工劳动。
5.3 模型组件的影响
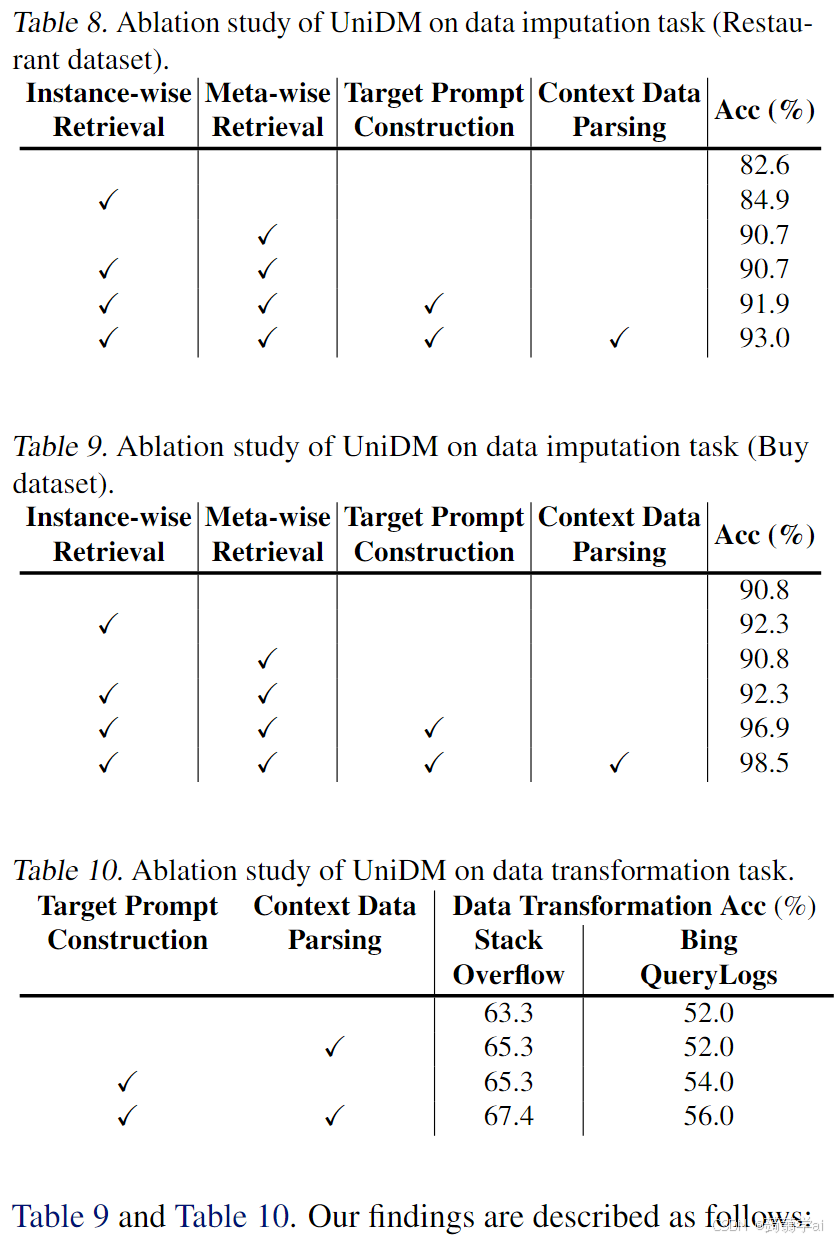
为了进行消融研究,我们分析UniDM中每个组件的有效性。具体而言,我们禁用UniDM中的一个或多个组件,并比较UniDM与其变体的性能。结果如表8所示。
上下文检索:当禁用上下文检索组件时,UniDM随机从表中抽取相同数量的属性和/或记录作为上下文信息。这时,UniDM的准确率显著下降。我们观察到,对于数据插补任务,仅通过实例级和元级检索,UniDM在Restaurants数据集上的准确率分别提高了2.3%和8.1%。此外,在Buy数据集上,使用上下文检索也提高了1.5%的准确率。这是因为我们的上下文检索利用LLMs捕获具有语义关系的相关属性和/或实例,为目标提示提供了更丰富的背景知识。对于数据转换任务,不需要提取上下文数据,因此此步骤未包含在消融研究中。
上下文数据解析:在没有上下文数据解析的情况下,我们仅应用序列化函数将表格上下文信息转换为字符串。我们观察到,对于数据插补任务,数据解析也有助于提高结果准确率,在Restaurants数据集上提高了1.1%,在Buy数据集上提高了1.6%。类似地,对于数据转换任务,使用数据解析在StackOverflow数据集上提高了2%的准确率。这是因为我们的数据解析弥合了结构化表格数据与自然语言表示之间的差距,使上下文信息更易于被LLMs解释。
目标提示构建:我们还将UniDM与简单的提示进行比较,该提示直接将任务描述、上下文信息和任务输入组合以获得最终结果。对于数据插补任务,我们发现使用填空题构建的目标提示在Restaurants数据集上提高了1.2%的准确率,在Buy数据集上提高了4.6%。此外,对于数据转换任务,使用该方法也可以在StackOverflow和Bing-QueryLogs数据集上提高2%的准确率。这验证了我们目标提示构建方法的有效性。它通过学习示例来识别最合适的提示,而不是简单的组合。
5.4 讨论
我们实验研究的主要目标是展示LLMs在增强数据湖和减少人工工作中的有效性。处理大量数据的挑战是数据湖系统面临的共同问题。数据关系呈现多种形式。例如,在某些情况下,我们可能有共享的值或键;而在其他情况下,数据可能是互补的,因此完全没有值重叠。为了应对这一挑战,我们的方法利用LLMs理解数据关系、整合异构数据源,并自动识别关系数据以进行数据任务。我们的研究发现,通过选择关系数据和过滤噪声数据,数据检索可以提升性能。数据湖系统的另一个重大挑战是支持各种按需查询。我们的UniDM灵活地提供了数据模块和任务模块的组合。从数据模块的角度来看,自动数据检索用于提取有用信息,而数据解析用于数据解释。从任务模块的角度来看,提示工程展示了在各种数据任务中的显著跨任务能力。总的来说,我们的UniDM使数据湖中的数据可操作,并以灵活的方式丰富了数据湖。
6 结论
在本文中,我们设计了UniDM,一个统一框架,用于解决数据湖中的数据操作任务。UniDM将多种数据操作任务总结为统一形式,并设计了一般步骤,以使用适当的提示通过LLMs解决这些任务。实验结果表明,UniDM在各种数据操作任务上与传统和学习方法相比表现优越。在未来的工作中,我们展示了在数据、模型和算法方面仍有足够的改进空间。我们希望UniDM中提出的策略能够为探索LLMs与数据库系统的结合贡献并启发更多进展。
6.1 未来工作
UniDM可以通过显式检索数据(可能包含证据和事实信息)来受益,这在数据操作处理之前。然而,当处理商业用例所需的领域特定知识时,模型可能不可靠。在这种情况下,LLMs可能生成在实际应用中存在问题的信息,其中事实准确性至关重要。另一个限制是可解释性。在大多数数据应用(例如根本原因分析)中,包含所有应用于得出结论的规则的良好解释对用户来说是有价值的。尽管LLMs在各种数据任务中取得了显著成功,但它们的推理和解释能力通常被视为一种限制。我们总结了一些未来的研究方向,涉及数据、模型、算法和效率的不同视角,如下所述。
与领域知识的集成:从第5.2节的结果中,我们观察到UniDM在通用数据上表现良好,但在领域特定数据上可能表现不佳。然而,数据湖通常包含来自高度专业化领域的数据,例如金融、生物和学术数据。目前,广泛采用的方法是用领域特定数据对LLMs进行微调。然而,微调仍然面临挑战,例如如何从数据湖中提取高质量数据作为语料库来微调LLMs。此外,探索新的集成方法而不是微调LLMs也非常有趣。
为数据库任务设计大型模型:LLMs主要是在文本语料上训练,以解决NLP任务。尽管我们可以设计序列化函数和提示以将LLMs应用于表格数据,但这本质上是一个“量体裁衣”的过程。更好的方法是从头开始设计和训练大型模型,以捕捉数据库任务的语义,包括表格(和其他类型)数据。一些先前的工作尝试利用BERT(例如,TaPas(Herzig et al., 2020)、TaPEx(Liu et al., 2021)、Tableformer(Yang et al., 2022)、TURL(Deng et al., 2022))来理解(半)结构化数据。然而,所有的概念、模型结构、训练方法和大型模型的整个范式都需要重新设计以适应数据库任务。
效率考虑:我们方法中应用的LLMs带来了好处,但也增加了计算资源的消耗。在未来的工作中,考虑如何在保持LLM基方法有效性的同时提高效率显得尤为重要。一种可能的方法是设计更高效的检索方法,从数据中提取相关信息,以最小化计算开销。另一种方法是选择计算成本最低的LLMs以满足每个任务的需求。如表5所示,微调的小型LLM的性能可能与规模更大的通用LLM相匹配。
基于LLM的方法与传统方法:尽管我们的基于LLM的解决方案在结果有效性方面表现出优势,但它们无法完全取代传统方法。LLM仍然是一个难以解释、调试和分析的黑箱。这些都是对需要稳固稳定的数据库系统的风险因素。依赖几十年人类经验调优的规则和逻辑的传统方法具有独特的优势。它们在系统部署上更为友好。因此,基于LLM的方法和传统方法并不冲突,而是相辅相成。将它们的优势结合起来以控制部署风险,同时仍能获得高效的结果,将是非常务实的。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











