









摘要
本文探讨了大型语言模型(LLMs)在数据预处理(DP)中的应用,这是数据挖掘流程中一个关键步骤,旨在将原始数据转化为适合于轻松处理的干净格式。虽然LLMs的使用引发了对制定通用DP解决方案的兴趣,但该领域近期的举措通常依赖于GPT API,这引发了不可避免的数据泄露担忧。与这些方法不同,我们考虑对本地LLMs(7-13B模型)进行指令调优,作为在本地、单一、低成本GPU上运行的通用DP任务求解器,以确保数据安全并允许进一步定制。我们选择了四个代表性DP任务的多个数据集,并使用数据配置、知识注入和推理数据蒸馏技术构建了针对DP的指令调优数据。通过对Mistral-7B、Llama 3-8B和OpenOrcaPlatypus2-13B进行调优,我们的模型,即Jellyfish7B/8B/13B,与GPT-3.5/4模型相比具有竞争力,并在未见任务上展现出强大的泛化能力,同时几乎没有损害基础模型在自然语言处理任务中的能力。同时,Jellyfish在推理能力上优于GPT-3.5。
1 引言
数据预处理(DP)是数据挖掘流程中的一个关键步骤,涉及将原始数据转化为可管理和可处理的格式,以便于使用。在过去几十年中,各种DP任务取得了重大进展。直到2021年,大多数努力集中在一到两个特定任务上,如错误检测(ED)(Heidari et al., 2019; Mahdavi et al., 2019)、数据填补(DI)(Rekatsinas et al., 2017; Mahdavi and Abedjan, 2020; Mei et al., 2021)、模式匹配(SM)(Zhang et al., 2021)和实体匹配(EM)(Konda et al., 2016; Li et al., 2020)。开发通用DP解决方案的一个关键挑战在于这些任务的本质不同:它们处理错误、异常、匹配等,并且需要不同的操作,如检测、修复和对齐。随着LLMs的出现,研究人员找到了应对这一挑战的关键,推动了更广泛DP任务的通用解决方案的发展。LLMs相较于非LLM的DP方法的优势在于其自然语言生成能力、内部知识、推理能力、泛化能力和通过少量(Brown et al., 2020)或零样本(Kojima et al., 2022)提示的适应性,从而降低了人力成本(例如超参数调优),并提高了解释性。尽管现有的基于LLM的DP解决方案(Narayan et al., 2022; Zhang et al., 2023a; Korini and Bizer, 2023; Li et al., 2023)依赖于GPT API,但也引发了关于数据泄露的担忧,正如OpenAI确认的数据泄露所示(OpenAI, 2023)。另一个限制是领域规范化的困难(Narayan et al., 2022)。在处理高度专业化领域的数据时,使用这些解决方案中的LLMs进行训练可能成本高昂(例如,GPT-3.5),甚至由于参数被冻结而不可用(例如,GPT-4),这给模型定制带来了困难。针对这些挑战,我们提出构建指令数据并对LLMs进行调优,以应对各种DP任务。调优后的模型Jellyfish具有几个关键特性:(1) Jellyfish是一个通用DP任务求解器,调优于以下任务:数据清洗的ED和DI,以及数据集成的SM和EM。(2) Jellyfish的规模从7B到13B不等,可以在本地、单一且低成本的GPU上运行,确保数据安全并允许进一步调优。(3) Jellyfish能够理解自然语言,允许用户手动编写DP任务的指令(或简单使用本文中的提示),并应用提示工程技术将其定制为特定任务和数据集。(4) 不同于许多现有方法在推理过程中严重依赖手工知识(Rekatsinas et al., 2017; Qin et al., 2023),Jellyfish在其指令调优中融入领域知识,并在推理时支持可选的知识注入。(5) 通过在指令调优中采用推理数据,Jellyfish的解释能力能够提供其输出的自然语言说明。虽然LLMs的指令调优在很大程度上用于非结构化文本(Zhang et al., 2023b),但构建Jellyfish并非简单,因为(1) 它针对结构化数据进行调优,(2) 为各种DP任务找到良好的数据配置,(3) 指定可应用于未见数据集的领域知识。此外,预计该模型在NLP任务中的表现能够保持,以实现泛化性和进一步的定制。根据我们的了解,这是首个研究LLMs在DP中的指令调优作为通用解决方案的研究。如图1所示,Jellyfish通过精心选择几种广泛用于DP评估的公共数据集构建,考虑其对整体性能的影响。通过实例序列化,原始数据被序列化为指令调优提示。通过知识注入,特定于任务和数据集的知识——特别是可以扩展到未见数据集的领域知识——被注入到提示中。此外,我们使用Mixtral-8x7B-Instruct-v0.1生成推理数据。因此,Jellyfish提炼了Mixtral在推理DP结果中的知识。我们的评估集中在调优一组流行的开放LLM上,包括Mistral-7B-Instructv0.2(作为Jellyfish-7B)、Llama 3-8B(作为Jellyfish-8B)和OpenOrca-Platypus2-13B(作为Jellyfish-13B)。结果表明,我们的指令数据适用于所有这些基础模型,显著提高了DP性能。与两类基线方法相比,(1) 非LLM方法——通常是基于机器学习(ML)或预训练语言模型(PLMs)的解决方案——和(2) LLM方法——通常是GPT系列方法,Jellyfish-13B在其已见数据集上始终优于非LLM方法,并且在未见数据集上的有效性甚至超过了非LLM方法在其各自已见数据集上的表现。同时,Jellyfish-7B/8B在DI和EM任务上也表现出竞争力。对于未见任务,Jellyfish模型也展现出强大的性能,与GPT-3.5/4模型相抗衡,并展示出对超出调优的四个任务的更广泛DP任务的泛化能力。我们的评估揭示了数据配置和推理数据在构建Jellyfish中的影响,并发现Jellyfish几乎没有损害基础模型的NLP性能。此外,实验表明,Jellyfish在推理能力上优于GPT-3.5,并且在知识注入的有效性上也表现出优势。
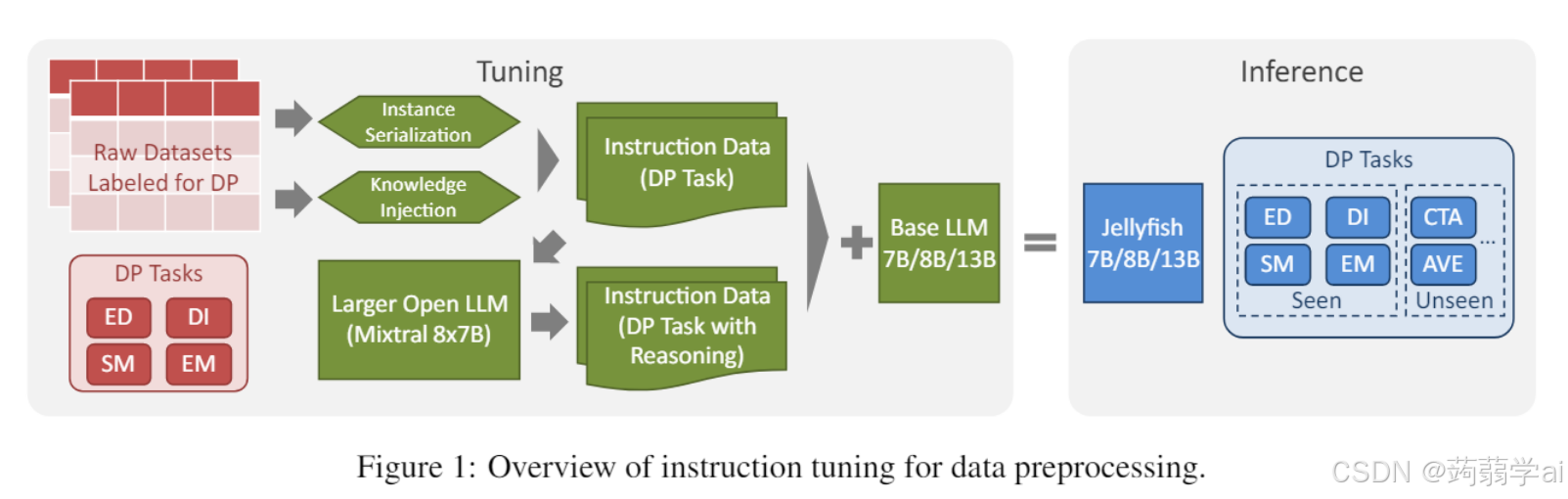
2 初步研究
在数据挖掘中,数据预处理(DP)是一个关键步骤,处理数据中的噪声、缺失值、不一致性和异质性。主要的DP过程包括数据清洗、数据集成、数据转换和数据减少(Han et al., 2022)。在对LLMs进行DP的初步探索中,我们集中于表格数据,这是最常见的数据类型之一。我们的数据模型基于由模式指定的关系表。我们假设所有属性均为数值(包括二进制)或文本(包括分类)值。与传统定义不同,传统定义展示整个数据集并查找或修复其中的所有错误(或匹配等),我们定义的问题是一次处理一条记录(或一对,具体取决于任务),以便于编写提示,并确保其长度在LLMs的令牌限制之内。接下来,我们概述本研究涉及的DP任务:(1) 错误检测(ED):给定一条记录(即关系表中的元组)和一个属性,我们的任务是检测该属性的单元格值是否存在错误。(2) 数据填补(DI):给定一条记录和一个属性,该属性的单元格值缺失,我们的任务是推断其正确值。(3) 模式匹配(SM):给定一对以(名称,描述)形式表示的属性,我们的任务是判断它们是否指代同一属性。(4) 实体匹配(EM):给定一对记录,我们的任务是推断它们是否指代同一实体。这四个任务构成了DP中最关键的部分(Narayan et al., 2022; Zhang et al., 2023a),并在数据挖掘的背景下进行了广泛讨论(Han et al., 2022)。我们将它们用于指令调优。此外,我们考虑两个未见任务:(1) 列类型注释(CTA):给定一个没有标题的表,我们的任务是从一组预定义类型中推断每一列的类型(例如,名称、时间、位置)。(2) 属性值提取(AVE):给定一个实体的文本描述和一组预定义属性,任务是从文本描述中提取属性值。我们将每个输入对象称为实例,即,对于ED和DI是记录,对于SM是一对属性,对于EM是一对记录,对于CTA是一个表或一列,对于AVE是一个文本描述。
3 Jellyfish的指令调优
3.1 数据集准备
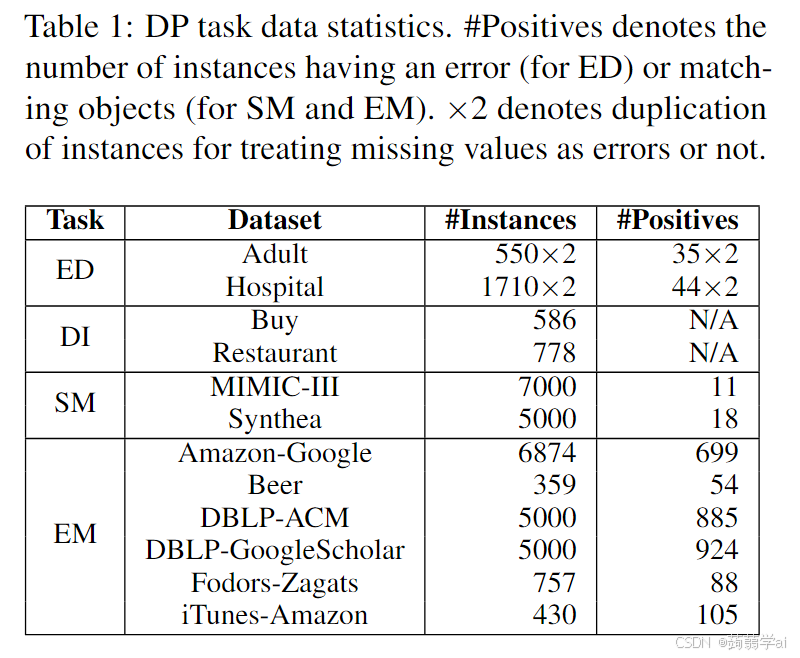
对于四个已见任务,我们选择了一系列在之前研究中被广泛使用并涵盖多种应用领域的数据集。(1) 错误检测(ED):Adult和Hospital(Heidari et al., 2019);(2) 数据填补(DI):Buy和Restaurant(Mei et al., 2021);(3) 模式匹配(SM):MIMIC-III和Synthea(Zhang et al., 2021);(4) 实体匹配(EM):来自Magellan数据仓库的Amazon-Google、Beer、DBLP-ACM、DBLP-GoogleScholar、Fodors-Zagats和iTunes-Amazon(Das et al.)。我们使用这些数据集的公开可用版本(Narayan et al., 2022),其中错误和缺失值已经注入到ED和DI的数据集中。为了确定每个任务的数据大小,我们首先考虑一个约束条件,为了与非LLM方法进行公平比较(Mei et al., 2021;Zhang et al., 2021;Li et al., 2020),在构建Jellyfish时使用的训练数据不能超过用于构建这些方法的数据,这些方法的实例池为115k。然后,我们有以下观察结果(见第5.5节):(1) DI的性能可以受益于其他三个任务,但增加DI数据对其他任务的影响相对较负面。(2) 增加ED和SM数据通常对其他任务是有利的。(3) 增加SM数据对整体DP性能是有益的。(4) 增加EM数据会影响其他任务的性能,但保持其数量对EM性能至关重要。基于这些观察结果,我们使用115k池中所有的ED和DI数据,因为它们的数量较少,然后选择SM的大数据量和EM的适度数据量。具体来说,我们控制用于大EM数据集的数据(例如,对于DBLP-GoogleScholar,从池中选择1/3)。因此,我们确定了四个任务的数据大小,如表1所示。此外,我们在准备数据时采取以下措施:(1) 鉴于正实例与负实例的数量不成比例地小,我们纳入数据集中所有可用的正实例。(2) 对于ED,由于缺失值可以根据上下文被解释为错误或非错误,我们为每个实例创建两个版本:一个将缺失值视为错误,另一个视为非错误。复制的过程由知识注入指导,这将在第3.2节中详细说明。接下来,我们将原始数据转换为:(1) DP任务数据,用于DP任务解决能力,以及(2) 带推理数据的DP任务,用于解释能力。这两者可以共同用于调优Jellyfish模型。

3.2 DP任务数据
为了为LLM准备DP任务数据,我们需要将原始数据中的每个实例序列化(即上下文化)为提示。提示包含任务描述、实例内容和任何注入的知识。为了描述我们为训练构建DP任务数据的技术,我们使用一个来自Beer数据集的实例作为实体匹配(EM)的示例,如图2所示。首先,有一个系统消息指导模型的行为。在这里,我们指示模型充当AI助手来回答用户的问题,其响应应始终遵循这一约束。然后,我们描述DP任务。接下来的部分涉及注入的知识。注入知识分为两类:(1) 适用于多个数据集的一般知识,(2) 仅适用于给定数据集的特定知识。在此示例中,知识属于一般知识,涉及缺失值。这种知识注入可以防止模型错误处理数据集中某些值,尤其是在训练数据噪声较大时。接下来的部分涉及实例内容。最后,给模型提出一个问题,并随后指定输出格式。在上述示例中,我们指定了关于缺失值的知识,调优时还使用了其他形式的一般知识,包括错误类型和术语。例如,对于ED,我们告知模型错误可以包括但不限于拼写错误、不一致性或对该属性没有意义的值;对于EM,我们指示模型在判断两个值是否相同时考虑属性的全名及其缩写。特定知识高度依赖于应用领域,主要包括与数据集相关的约束或规则。例如,在出版物数据集中,即使对于同一篇文章,作者的名字可能以不同的形式和顺序出现。此外,模型可以被配置为对某些属性赋予更高的重要性。例如,在产品数据的上下文中,模型被指示优先比较产品编号。特定知识可以适用于同一领域内的数据集,从而提高模型在未见数据集上的性能,特别是在对这些数据集缺乏先验知识的情况下。总体而言,通过调优注入的知识成为模型的内置知识,即使在推理过程中没有用户指定,也可以使用。
3.3 带推理数据的DP任务
带推理数据的DP任务不仅增强了模型对DP结果的解释能力,还有潜力提升DP性能,因为模型可以学习DP背后的推理,从而推广到底层逻辑与调优任务/数据集相似的未见场景。另一方面,由于本地LLMs的规模较小,使用过多的推理数据进行调优可能会影响其执行调优DP任务的能力。因此,我们需要在DP性能和泛化能力之间取得平衡。
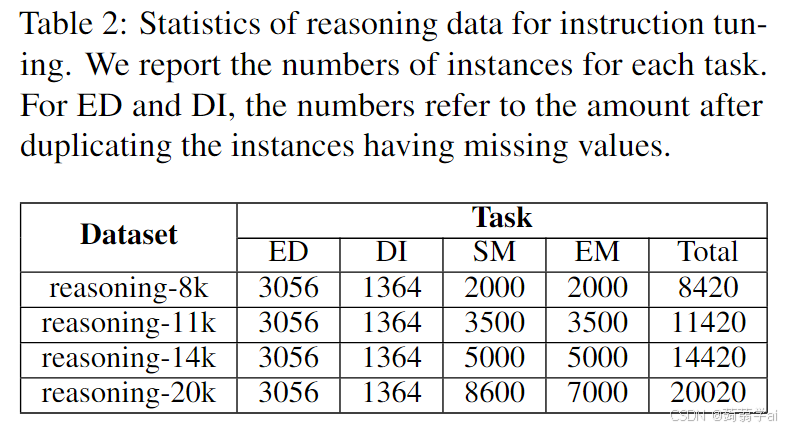
通常,我们观察到本地模型(Mistral和Llama 3)更有可能从使用推理数据中受益(见第5.6节)。我们推理数据的另一个关键特性是,我们利用一个更大的开放LLM,Mixtral8x7B-Instruct-v0.1,来检索推理答案作为地面真相。因此,Jellyfish提炼了Mixtral在DP推理中的知识。由于这不涉及像GPT-4这样的外部API,因此可以确保数据安全,以防用户希望在推理数据中包含机密信息。我们使用与DP任务数据相同的数据集来构建推理数据。推理数据中的提示仅在推理指令上与DP任务数据有所不同(如图2,系统消息和输出格式)。为了从Mixtral中检索推理答案,我们在提示的末尾添加一个提示,以获取正确的DP结果(例如,对于匹配任务的“是/否”),以此指导Mixtral朝正确的方向推理(见附录D.2)。请注意,这种提示不会出现在提供给Jellyfish的提示中。为了控制推理数据的大小和质量,我们按如下方式选择数据:(1) 对于ED和SM,由于正实例数量较少,我们保留所有正实例,然后抽样负实例。(2) 对于DI,由于数据量小,我们保留所有实例。(3) 对于EM,我们进行实例抽样。从115k池中,我们调整样本中的数字,以制作四组推理数据,分别为8k、11k、14k和20k实例(见表2)。此外,从Mixtral返回的答案中,我们删除那些简单重述实例内容的低质量答案,因为它们几乎不涉及推理。
4 使用Jellyfish进行推理
在推理过程中,提示与图2中显示的指令数据相同。用户可以将特定于数据集的知识融入提示中,例如前面章节中概述的领域知识(如约束)。这种用户指定的知识是可选的。
特征工程。用户可以选择性地选择特征子集以提高性能。例如,对于Beer数据集中的EM,名称和工厂是更相关的特征,而风格和ABV则相关性较低。因此,用户可以选择仅使用名称和工厂作为属性。这种特征工程也可以在提示中作为特定知识实现,例如,您应该只考虑名称和工厂,忽略其他属性。
提示工程。提示工程(Weng, 2023)是结构化文本以增强模型性能的过程。我们结合了少量示例提示(Brown et al., 2020),使Jellyfish模型能够从数据集中抽取的小部分示例中学习。少量示例的提示在附录F中报告。
批处理。为了使Jellyfish模型能够批量推理,而不是单独处理单个实例,我们可以使用前缀缓存(Kwon et al., 2023),该功能可在vLLM(vLLM团队,2024)库中找到,因为批处理的指令共享相同的前缀,仅在实例内容上有所不同。
5 实验
5.1 实验设置
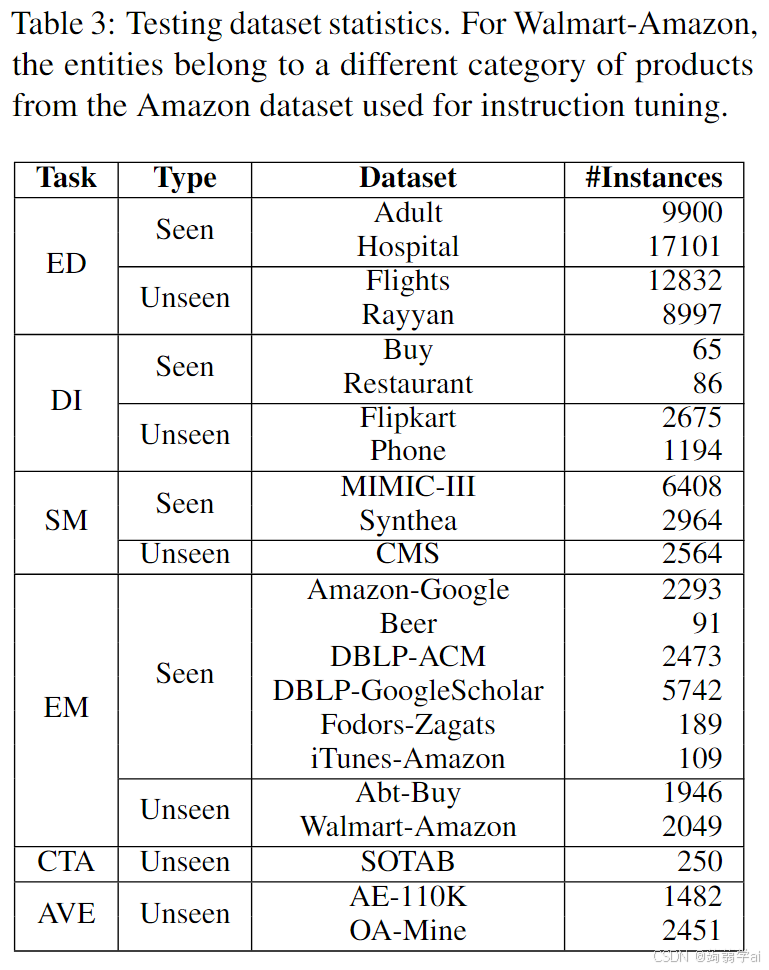
数据集。我们在表3中显示的数据集上进行实验。CTA和AVE是未见任务。
Jellyfish模型。我们对三个基础模型进行指令调优:(1) Mistral-7B(Mistral-7B-Instructv0.2 (Jiang et al., 2023)),(2) Llama 3-8B(Llama-3-8B-Instruct (Meta AI, 2024)),和(3) OOP2-13B(OpenOrca-Platypus2-13B (Lee et al., 2023)),这是Llama 2-13B的一个增强推理能力和逻辑能力的变体。调优后的模型分别命名为Jellyfish-7B、Jellyfish-8B和Jellyfish-13B。7B和8B模型使用DP任务和推理数据进行调优(7B模型有15k推理实例,8B模型有8k推理实例)。13B模型仅使用DP任务数据进行调优。因此,Jellyfish-7B和Jellyfish-8B是解释模型,而Jellyfish-13B则是专门针对调优任务的任务求解器。我们在附录A中报告超参数设置,在附录E中报告注入的知识。对于推理,(零样本)提示与DP任务数据和推理数据相同。我们在提示中应用一般知识,例如匹配任务中的缺失值和基线中的错误类型。我们将现有方法分为非LLM方法和LLM方法。对于非LLM方法,我们选择以下基线:(1) ED:HoloDetect (Heidari et al., 2019) 和 Raha (Mahdavi et al., 2019);(2) DI:IPM (Mei et al., 2021);(3) SM:SMAT (Zhang et al., 2021);(4) EM:Ditto (Li et al., 2020) 和 Unicorn (Tu et al., 2023);(5) CTA:RoBERTa (Liu et al., 2019)。对于它们的性能,我们遵循先前工作中报告的最佳数据(Narayan et al., 2022;Korini and Bizer, 2023;Tu et al., 2023)。LLM方法包括GPT-3、GPT-3.5、TableGPT (Li et al., 2023)(针对表格微调的GPT-3.5)、GPT-4、GPT-4o、Stable Beluga 2 70B (Mahan et al., 2023) 和 SOLAR 70B (Upstage, 2023)。我们遵循先前工作中报告的数字(Narayan et al., 2022;Zhang et al., 2023a;Brinkmann et al., 2023)。少量示例用于与Jellyfish的公平比较。
指标。对于DP任务求解,我们测量DI的准确率、ED、DI、EM和AVE的F1分数,以及CTA的微F1,所有报告均以100为尺度。
环境。LLMs的训练和推理在NVIDIA A100 80GB GPU上进行。我们使用LoRA (Hu et al., 2021) 和 FlashAttention2 (Dao, 2023) 进行调优,并使用带有PageAttention (Kwon et al., 2023) 的vLLM进行推理。
5.2 DP性能
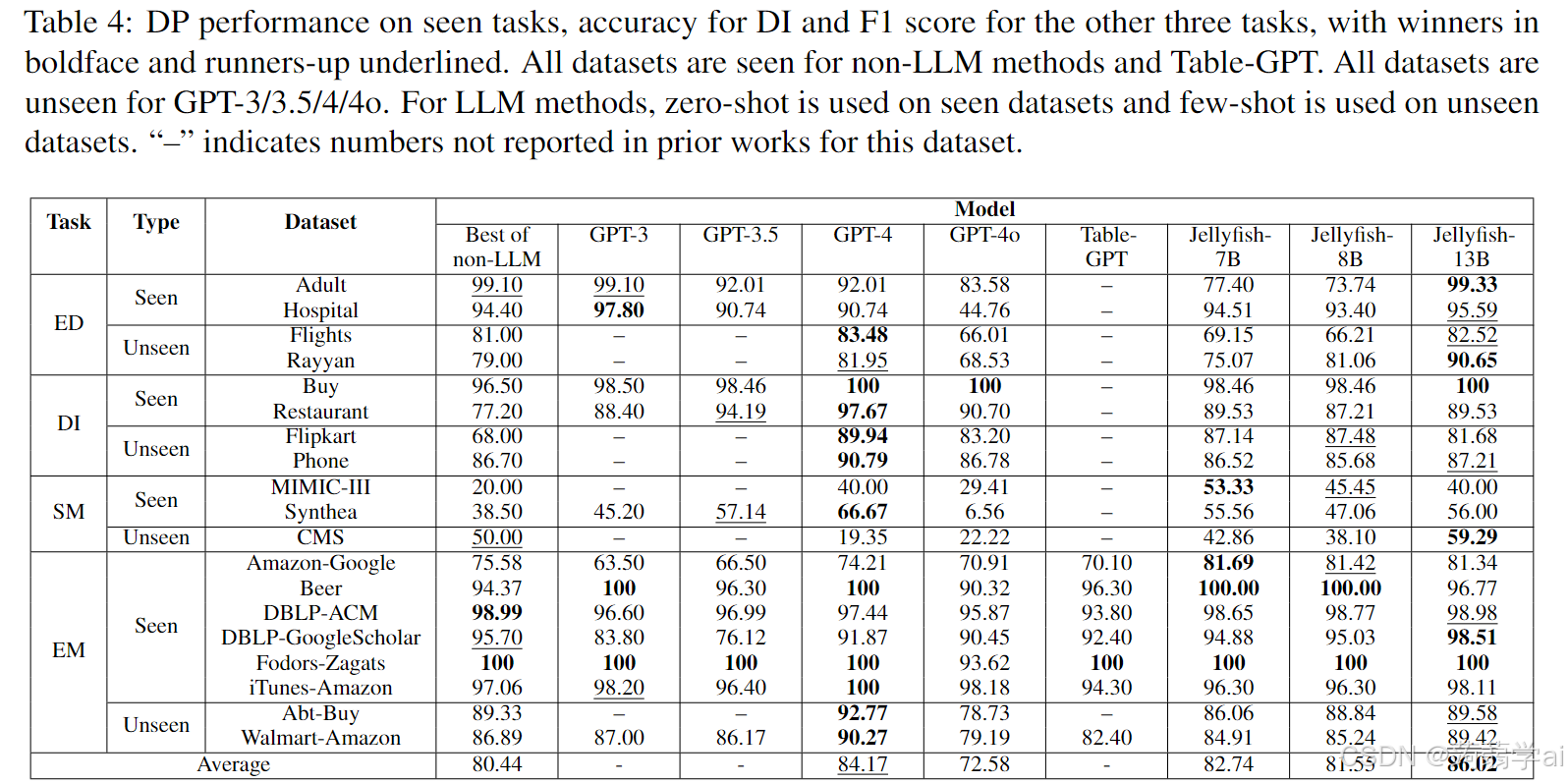
已见任务。表4报告了已见任务的性能。GPT-4在大多数情况下表现最佳(19个任务中有11个)。然而,其在CMS数据集的SM任务中的得分中等。Jellyfish-13B在19个任务中获得第二多的胜利(7个),并因在CMS数据集上对GPT-4的优势而报告最佳平均得分。将Jellyfish-13B与GPT-3、GPT-3.5、GPT-4o和Table-GPT进行比较,Jellyfish-13B在更多案例中获胜。Jellyfish-13B还在所有未见数据集和除一个已见数据集外的所有已见数据集上优于非LLM的最佳表现。请注意,对于非LLM方法,所有数据集都是已见的,因为它们需要在上面进行微调。同时,7B和8B的Jellyfish模型在竞争力上也表现出色,特别是在DI和EM任务上,其平均得分超出非LLM的最佳表现和GPT-4o。
未见任务。表5报告了未见任务的性能比较。在CTA任务中,GPT-4表现最好。Jellyfish模型也表现出竞争力,尤其是7B和13B模型。在AVE任务中,所有Jellyfish模型展示了强大的泛化能力。特别是Jellyfish-8B和Jellyfish-13B在两个数据集上均超越了两个70B模型,并在AE-110k数据集上优于GPT-4。

5.3 Jellyfish相较于基础模型的改进
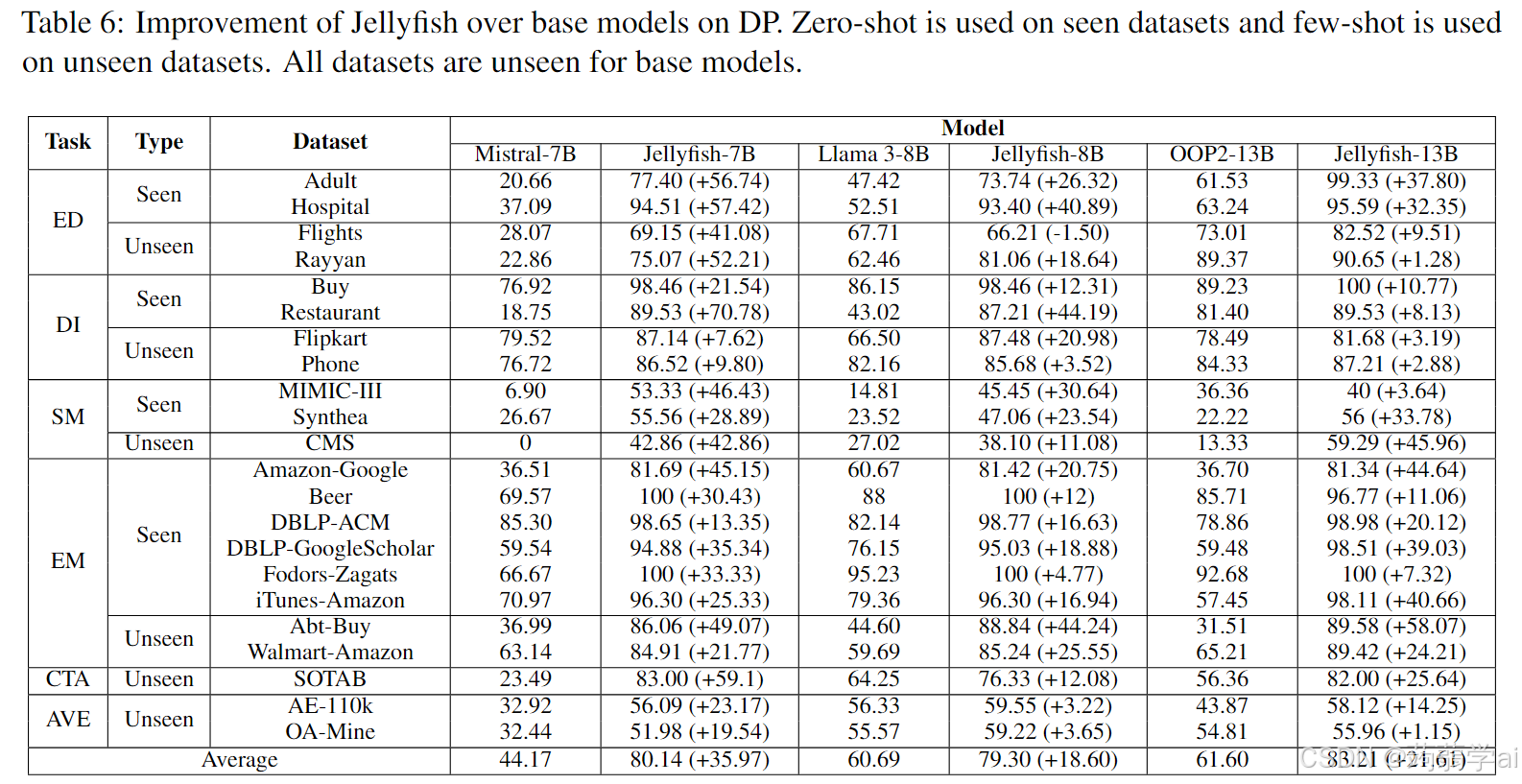
表6比较了Jellyfish模型与其基础模型在DP任务上的表现。我们观察到7B和13B模型在所有数据集上均有一致的性能提升,而8B模型在所有数据集上仅有一个未得到提升。7B模型的改进最为显著,平均得分提高了35。对于8B和13B模型,改进同样显著,平均得分分别提高了18和21。我们还观察到,调优有利于未见数据集和未见任务的性能。这种影响在EM的未见数据上最为显著,展示了通过调优注入的知识能够很好地应用于未见场景。
5.4 NLP性能
表7比较了Jellyfish模型与其原始模型在各种NLP基准(Hendrycks et al., 2020;Sakaguchi et al., 2021;Lin et al., 2021;Chollet, 2019;Cobbe et al., 2021;Zellers et al., 2019)上的表现,这些基准来自开放LLM排行榜(Face, 2024)。对于8B和13B模型,它们在经过DP调优后,NLP性能基本保持不变,变化极小(平均分别为0.56和0.36),甚至在两个基准上有所提升。这是因为我们使用自然语言指令对Jellyfish进行DP任务的调优,保持了与其基础模型相同的交互格式。7B模型在DP性能上牺牲了更多的NLP性能(平均下降1.32)。我们认为这反映了无免费午餐定理(Wolpert和Macready, 1997),考虑到它在三者中规模最小。
5.5 指令数据配置的影响
我们研究了指令数据中数据配置的影响。对于这一实验集,我们随机从表1中的数据集中抽样数据,并禁用有关正实例和缺失值的数据准备技术(第3.1节),以清晰地观察数据集大小的影响。为了简化评估,我们对单一DP任务的数据调优13B模型并评估其效果。通过改变数据量,图3显示了特定任务的调优数据如何影响DP性能。一般而言,四个任务在提高整体性能上均有用。对于任务内部性能(例如,ED到ED),如预期,调优数据具有显著的积极影响。对于任务间性能,ED和SM通常对其他任务是积极的,而DI和EM报告了负面影响。当我们增加调优数据量时(例如,将EM从21k加倍到43k),也观察到对整体DP性能的这种影响。我们还发现DI可以从其他三个任务中受益。我们认为这是因为其他三个任务都包含属性的正确值,从而增强了模型填补缺失值的能力。此外,增加调优数据量对SM的好处是显而易见的。总体而言,这些观察结果影响了构建Jellyfish时的数据配置(第3.1节)。更多关于此实验的结果见附录C.2。
5.6 推理数据的影响
图4显示了推理数据(8k、11k、14k和20k实例)如何影响DP性能。对于7B和8B模型,平均得分先上升后下降,当使用更多推理数据进行调优时,这表明少量推理数据——伴随DP背后的推理——可以增强模型的DP性能。由此,我们选择14k和8k作为两个模型的推理数据大小,以实现整体性能的平衡。对于13B模型,得分急剧下降,然后在增加推理数据后反弹。这可能归因于OOP2-13B的推理和逻辑能力,旨在增强Llama 2的能力,但最终与DP的底层逻辑不完全对齐。只有当DP推理数据达到20k时,模型才能学会有效处理DP。然而,得分仍低于没有推理时的表现,因此我们选择不对13B模型进行推理数据的调优。关于解释性能,请参考附录C.4。
5.7 效率比较
使用8个A100 80G GPU进行指令调优,Jellyfish-13B约耗时5小时,Jellyfish-7B和Jellyfish-8B约耗时3小时。在单个A100 80G GPU上进行推理时,Jellyfish-7B、8B和13B平均处理一个实例的时间分别为0.07、0.08和0.15秒。作为参考,GPT-4平均每个实例耗时1-8秒。虽然LLMs需要大量计算资源,从而增加使用成本并降低效率,但一些非LLM方法,如RoBERTa及其衍生方法(如IPM),在应用于未见数据集时需要微调。这一微调时间应计入总时间成本,以进行公平比较。此外,先进的学习技术使Jellyfish模型能够被量化(Liu et al., 2023)或蒸馏以提高效率,这将在未来考虑。为了进一步节省处理时间,建议用户使用一种简单但更快的方法来检索一组候选项,然后将Jellyfish模型应用于这些候选项。例如,对于EM,通常使用阻塞方法根据某些属性将相似记录分组,从而将比较范围缩小到每个块内。在多个实例的批处理过程中,当在vLLM中启用前缀缓存时,8B和13B模型的速度分别可以提高1.31和1.27倍。然而,由于Mistral-7B中使用了滑动窗口注意力,这种优化在7B模型中不可用。关于内存消耗,Jellyfish-7B、8B和13B分别消耗18GB、20GB和30GB的VRAM(包括模型)。为了进一步减少内存消耗,我们可以采用基于激活的权重量化(Lin et al., 2024)。通过这样做,7B和8B模型的内存消耗可以分别减少到7.5GB和8GB,而几乎不影响性能(7B模型和8B模型的平均微F1/准确率分别下降-1.25和-0.52)。
6 相关工作
本文针对的DP任务已被广泛研究。尽管传统方法主要依赖手工规则(Chu et al., 2013;Rekatsinas et al., 2017;Song et al., 2018;Papadakis et al., 2020),但先进的方法采用了机器学习(ML)技术。(1) 对于ED,HoloDetect(Heidari et al., 2019)利用带噪声通道模型的少样本学习,而Raha(Mahdavi et al., 2019)则采用一系列ML管道,如特征工程。(2) 对于DI,显著的方法基于变分自编码器(VAE)(Nazabal et al., 2020)、生成对抗网络(GAN)(Yoon et al., 2018)、注意力机制(Wu et al., 2020;Tihon et al., 2021)和预训练语言模型(PLMs)(Mei et al., 2021)。(3) 对于SM,已开发学习排序(Gal et al., 2019)、深度相似矩阵(Shraga et al., 2020)和基于注意力的方法(Zhang et al., 2021)。(4) 对于EM,流行的方法使用深度学习模型进行阻塞(Thirumuruganathan et al., 2021)或成对匹配(Mudgal et al., 2018),以及PLMs用于这两种过程(Li et al., 2020)。此外,还有一个PLM解决方案(Tu et al., 2023)可用于SM和EM。(5) 对于CTA,流行的方法主要基于表格表示学习(Iida et al., 2021;Deng et al., 2022;Suhara et al., 2022)。最近,ChatGPT也被利用(Korini and Bizer, 2023)。(6) 对于AVE,早期方法采用LSTM(Kozareva et al., 2016;Zheng et al., 2018)。随着PLMs的出现,许多解决方案依赖于对BERT的调优(Xu et al., 2019;Wang et al., 2020;Zhu et al., 2020)。最近的工作(Brinkmann et al., 2023)考虑了调优GPT-3.5和提示GPT-4。上述方法是LLM时代之前的非LLM解决方案。其中许多基于PLMs,仅适用于一到两个DP任务,并需要在目标数据集上进行微调。最近的发展基于冻结的LLMs(如GPT-3)提出了通用的DP解决方案(Narayan et al., 2022),GPT-3.5和GPT-4(Zhang et al., 2023a)。还研究了对GPT-3.5和ChatGPT进行微调以处理各种与表格相关的任务(Li et al., 2023)。除了本文探讨的六个任务外,其他DP任务还包括数据修复(Rekatsinas et al., 2017;Mahdavi和Abedjan, 2020;Lew et al., 2021;Qin et al., 2023)、数据融合(Azzalini et al., 2023;Heidari et al., 2023)和数据转换(He et al., 2018;Jin et al., 2020)。我们将在未来的工作中研究这些任务。
7 结论
我们研究了将LLMs指令调优作为通用DP任务求解器的问题。通过设计数据准备和知识注入技术,我们提出了Jellyfish,使用户能够为DP任务制定指令。Jellyfish的另一个显著特征是其解释能力,能够提供输出的解释。我们调优了三个基础模型,规模从7B到13B,能够在本地GPU上运行而不影响数据安全性。实验展示了Jellyfish在现有DP解决方案中的竞争力、对新任务的出色泛化能力、在NLP任务中保持性能的能力,以及解释能力的优秀表现。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











