






一、指代表达理解的多重挑战
在计算机视觉与自然语言处理交叉领域中,指代表达理解(Referring Expression Comprehension, REC)一直是研究的关键方向。这一任务要求模型能够基于自然语言描述,在图像中精准定位相应的目标对象。
然而,传统视觉模型在面对多实例指代任务时表现出明显局限:大多数仅针对单一实例优化,难以应对现实世界中"一条指令对应多个目标物体"的复杂场景。这种局限源于传统模型对语言理解的浅层处理,无法有效解析句子的语法结构和语义逻辑。
二、推理新范式:从名词识别到指代逻辑理解
DINO-XSeek 通过融合DINO-X 统一视觉模型基座与多模态大语言模型,在保持精确感知能力的同时,拥有多模态大语言模型强大的推理和理解能力,突破了传统视觉模型对自然语言理解的浅层限制,实现从词汇到语法,再到指代逻辑的多层次理解。
2.1 词汇层次:从名词到多词性理解
传统模型主要关注名词识别,而 DINO-XSeek 能够理解更广泛的属性指代:
(1)形容词:比如"黑色的"、"圆形的"等描述物体属性的修饰词;
(2)动词:比如"奔跑的"、"持有的"等描述行为状态的词汇;
(3)介词:比如"在...上方"、"位于...之间"等描述空间关系的词汇。
例如,面对"没熟的西红柿(unripe tomato)"这一描述,DINO-XSeek 能够理解"没熟的"(形容词)和“西红柿”(名词),从而理解它们之间的修饰关系。系统会首先识别出场景中所有的"西红柿",然后通过属性分析把“没熟的西红柿”从所有西红柿中指认出来。

图1 DINO-XSeek 标注“没熟的西红柿”
2.2 语法层次:理解句法结构与依存关系
DINO-XSeek 能够分析句子的语法结构,理解词与词之间的依存关系,包括:
(a)主谓关系:辨别"人正在走路"中的主体和行为;
(b)修饰关系:区分"红色的大车"中颜色和大小对车的修饰;
(c)所属关系:理解"车的后座"中的从属关系。
例如,面对"站在钢筋下方的工人(The worker under the steel bars)"这一描述,DINO-XSeek 能够精确分析"站"(动词)、"钢筋"(名词)、"下方"(位置关系)、"工人"(名词)之间的语法依存关系,并理解"站在...下方"构成的位置状语如何修饰"工人"这一主体。系统会首先识别出场景中所有的"工人",然后通过空间位置分析确定哪些工人位于"钢筋下方",从而精准地从多个工人中识别出处于危险位置的特定工人。

图2 DINO-XSeek 标注“站在钢筋下方的工人”
2.3 语义与逻辑层次:多步骤推理能力
基于优秀的词汇和语法理解能力,DINO-XSeek 拥有更加智能的高层语义推理能力,能够处理需要多步骤逻辑分析的复杂指令。
例如,面对“在攀岩墙下方但没有坐着的人(People who are below the rock climbing wall but are not sitting)”这一指令,模型执行的是复杂的逻辑分析:
-
识别所有"人"的类别;
-
筛选出位于"攀岩墙下方"的人;
-
在该区域内识别所有"没有坐着的"目标。
这种多步骤的逻辑推理能力,使 DINO-XSeek 能够处理现实世界中的复杂语言指令。同时也意味着 DINO-XSeek 有能力直接根据用户描述的业务逻辑执行目标检测任务,从传统的“以物体为核心”转向以“以处理物体逻辑为核心”,从而避免传统的基于视觉模型进行二次处理的繁琐工作,显著降低实际生产环境中的后期开发成本。

图3 DINO-XSeek 标注“在攀岩墙下方但是不是坐着的人”
三、技术架构:检测与理解的协同机制
DINO-XSeek 采用混合架构解决了传统模型的双重局限:目标检测模型缺乏语言理解能力,而语言模型缺乏精确定位能力。其检索式框架分为两个关键阶段:
-
视觉感知阶段:使用 DINO-X 开集目标检测模型扫描图像,生成所有潜在目标的边界框及特征表示;
-
语言理解阶段:大语言模型解析自然语言描述,理解其中的属性要求、位置关系、交互行为和逻辑条件,从已检测目标中检索符合条件的对象集合。
核心处理流程涉及三个组件:视觉编码器提取图像视觉 token,目标检测模型提取物体 token,tokenizer 处理文本输入。三种 token 通过大语言模型深度交互,实现从词性分析到句法结构理解的全面语言推理。
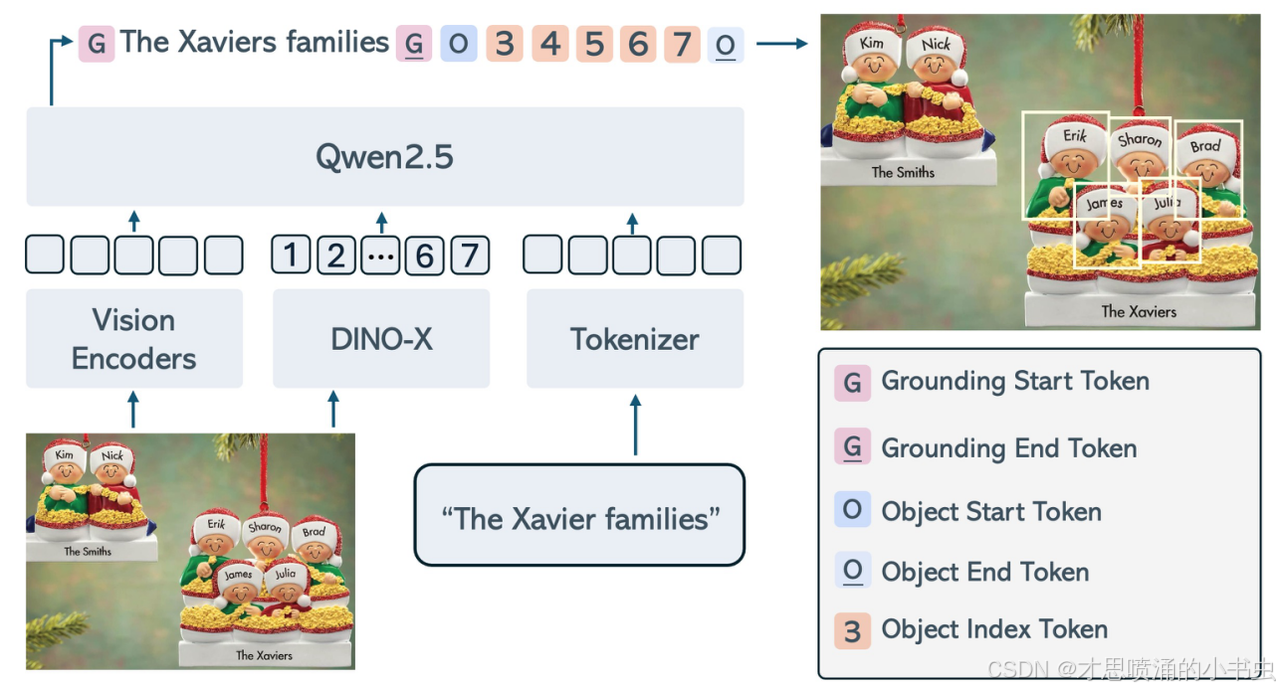
图4 DINO-XSeek 模型概览图
通过架构创新,DINO-XSeek 相比传统模型展现出四大核心优势:
-
多模态深度融合:DINO-XSeek 实现了视觉信息与语言信息的无缝融合,不仅能"看见"图像中的物体,还能"理解"这些物体与语言描述之间的复杂对应关系,真正达到多模态理解的深度整合。
-
增强鲁棒性:基于 DINO-X 的视觉感知基础,DINO-XSeek 显著提高了对非标准形态物体、部分遮挡场景以及密集多目标环境的处理能力,使系统在复杂真实环境中保持稳定表现。
-
高层语义推理:借助大语言模型的强大推理能力,DINO-XSeek 能够处理包含多重条件、隐含关系的复杂指令,解决了传统检测模型在语义理解和逻辑推理方面的固有局限。
-
配置灵活性:用户只需通过自然语言描述即可灵活配置检测策略,无需编写复杂代码或调整模型参数,极大降低了技术门槛和开发成本。
这些优势使 DINO-XSeek 成为连接高级视觉理解与自然语言交互的重要桥梁,为行业智能化带来了全新的想象力。
四、结语:从感知到认知的 AI 视觉新纪元
DINO-XSeek通过融合目标检测与大语言模型的技术优势,实现了从简单物体识别到复杂指代理解的重要跨越,标志着计算机视觉正在从基础"感知"向高级"认知"演进。这一技术突破不仅解决了传统视觉模型在多实例指代任务中的根本性困难,更重要的是开辟了人机交互的全新范式。
随着此类技术的持续发展与应用深化,我们可以预见人工智能将在各行各业中扮演更加智能的角色,比如:工厂流水线上,它能精准识别各类缺陷并进行分类;智慧城市中,它能监测异常行为并预警潜在风险;农业生产中,它能辨别作物生长状态并优化资源分配;自动驾驶领域,它能理解复杂道路环境并做出安全决策。
DINO-XSeek不仅是一种技术创新,更代表了人工智能向着真正智能化方向迈出的关键一步。通过打破传统视觉模型与自然语言处理的壁垒,它为未来人机协作创造了更加自然、高效的可能性,使人类能够用最直观的语言方式与AI系统交流,从而将人类的认知能力与机器的计算能力融为一体,共同应对更加复杂的现实世界挑战。
DINO-XSeek 官方博客:https://deepdataspace.com/blog/dino-xseek
立即体验 Playground:https://cloud.deepdataspace.com/playground/dino-x


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









