







目录
1. tuple元组
tuple元组,也是一种序列的形式:可以存储不同类型的数据。
定义的形式:(元素1, 元素2, 元素3) ,另 一种定义形式tuple()
tuple(arg): arg代表的是参数的意思,arg:可以是序列(字符串就是一个序列)
immutable sequence: 不可变的序列
查看python源代码和内置的帮助的方法
① : ctrl + left Mouse
② : help(对象或类)tuple源码
# help(tuple)
"""
| index(self, value, start=0, stop=9223372036854775807, /)
| Return first index of value.
|
| Raises ValueError if the value is not present.
"""注意:/ 之前的参数不能使用 参数名= 的这种方式去传值,只能写一个值。
/ 本身不是一个参数,只能来限制它前边参数的传参形式
start、stop代表的是检索的范围
tuple_data = (1, 2, 3)
# tuple_data.index(3, start=3)
# TypeError: tuple.index() takes no keyword arguments
# tuple . index ()不接受关键字参数
# / 之前的参数不能使用 参数名= 的这种方式去传值,只能写一个值
tuple_data.index(3, 1)
tuple_data = (1, 2, 3, 3)
tuple_data.index(3, 3, 50)2. list列表
list列表,也是一种序列,可以存储不同类型的数据。
定义的形式: ① [元素1, 元素2, 元素3];②list()
list_data = [1, 1.1, 1 + 1j, "汉字", b'x11', False, None, (1, 2, 3), [1, 2, 3]]
print(list_data, type(list_data))
list_data1 = list("hello")
list_data2 = list(b'x1101')
list_data3 = list((1, 2, 3))
print(list_data1, type(list_data1))
print(list_data2, type(list_data2))
print(list_data3, type(list_data3))列表是可变的。
list 列表
Built-in mutable sequence. --- 内置可变序列
If no argument is given, the constructor creates a new empty list.
如果没有给出参数,构造函数将创建一个新的空列表
The argument must be an iterable if specified.
如果指定,参数必须是可迭代的
list_data = [1, 2, 3]
list_data[1] = 10
# list_data[3] = 4
# IndexError: list assignment index out of range --- 列表赋值索引超出范围list和tuple的区别:
- list中的元素可修改,tuple中的元素不可修改。但是如果tuple中嵌套了list,那么由于list本身可修改,故此时的tuple也算是可以修改的。所以说,元组不一定不可变。
list的元素写在 [ ] 中,tuple中的元素写在 () 中。
- 构建只有一个元素的list,可以直接输入一个元素。但是在tuple中,如果要设置一个元素的元组,需要在元素后方加个英文逗号:’ , '。
学到的序列有哪几种:str、bytes、tuple、list
3. list中所有方法的使用(11种)
"""
append()方法:
| append(self, object, /)
| Append object to the end of the list.
"""
list_data = [1, 2, 3]
print(list_data) # [1, 2, 3]
list_data.append(4)
print(list_data) # [1, 2, 3, 4]
"""
clear()方法:不跟参数
| clear(self, /)
| Remove all items from list.
"""
# list_data.clear(4)
# TypeError: list.clear() takes no arguments (1 given)
list_data.clear()
print(list_data) # []
"""
count()方法
| count(self, value, /)
| Return number of occurrences of value.
"""
list_data = [1, 1, 2, 3]
print(list_data.count(1)) # 2
"""
extend()方法:
| extend(self, iterable, /)
| Extend list by appending elements from the iterable.
"""
list_str_data = list("hello")
list_bytes_data = list(b'x1101')
list_tuple_data = list((1, 2, 3))
list_list_data = [1, 11, 12, 33]
list_data = [1, 2, 3]
list_data.extend(list_str_data)
print(list_data) # [1, 2, 3, 'h', 'e', 'l', 'l', 'o']
list_data.extend(list_bytes_data)
print(list_data) # [1, 2, 3, 'h', 'e', 'l', 'l', 'o', 120, 49, 49, 48, 49]
list_data.extend(list_tuple_data)
print(list_data) # [1, 2, 3, 'h', 'e', 'l', 'l', 'o', 120, 49, 49, 48, 49, 1, 2, 3]
list_data.extend(list_list_data)
print(list_data) # [1, 2, 3, 'h', 'e', 'l', 'l', 'o', 120, 49, 49, 48, 49, 1, 2, 3, 1, 11, 12, 33]
"""
insert()方法:插入
| insert(self, index, object, /)
| Insert object before index.
"""
list_data = [1, 2, 4]
list_data.insert(2, 3)
print(list_data) # [1, 2, 3, 4]
"""
pop()方法:弹出
| pop(self, index=-1, /)
| Remove and return item at index (default last).
|
| Raises IndexError if list is empty or index is out of range.
"""
list_data = [1, 2, 3, 4]
# print(list_data.pop()) # 4
# print(list_data) # [1, 2, 3]
print(list_data.pop(2)) # 3
print(list_data) # [1, 2, 4]
"""
remove()方法:删除, 使用remove方法进行删除有风险,需要对要删除的元素进行判断
| remove(self, value, /)
| Remove first occurrence of value.
|
| Raises ValueError if the value is not present.
"""
list_data = [1, 1, 2, 3]
# list_data.index(4) # 检索不存在的元素时会报错,ValueError: 4 is not in list
# 如果需要判断一个元素在不在数据中,使用count()方法进行判断。
return_value = list_data.count(4)
print(return_value) # 0
list_data.remove(1)
print(list_data) # [1, 2, 3]
"""
reverse()方法:倒置
| reverse(self, /)
| Reverse *IN PLACE*.
"""
list_data = [1, 3, 2]
list_data.reverse()
print(list_data) # [2, 3, 1]
"""
sort()方法:排序
| sort(self, /, *, key=None, reverse=False)
| Sort the list in ascending order and return None.
|
| The sort is in-place (i.e. the list itself is modified) and stable (i.e. the
| order of two equal elements is maintained).
|
| If a key function is given, apply it once to each list item and sort them,
| ascending or descending, according to their function values.
"""
list_data = ["hello", "hey"]
list_data.sort()
print(list_data) # ['hello', 'hey']
自定义sort:
def get_last_char(str_data): # 以第三个字符做排序
return str_data[2]
def get_last_char1(str_data): # 以最后一个字符做排序,如果相等则比较倒数第二个,依次类推
return str_data[-1], str_data[-2], str_data[-3]
fruit_list = ["banana", "durian", "pineapple", "cherry", "strawberry", "kiwifruit", "peach", "grape"]
fruit_list.sort(key=get_last_char1)
print(fruit_list)
"""
以最后一个字符做排序
X[-1] => a, n, e, y, y, t, h, e
执行 X[-1],将取出来的关键字(x[-1])
"""
"""
以第三个字符做排序
X[2] => n, r, n, e, r, w, a, a
执行 X[2],将取出来的关键字(x[2])
a, a, e, n, n, r, r, w
"""4. dict字典
dict:字典: dictionary, 字典中的元素是key:value -- 键:值,的形式。字典不在是一个序列了。
class dict(object):
"""
dict() -> new empty dictionary
# dict ()-> new 空字典
dict(mapping) -> new dictionary initialized from a mapping object's
# dict (映射)->从映射对象的
(key, value) pairs
# ( key , value )对
dict(iterable) -> new dictionary initialized as if via:
# Dict ( iter able )->新字典的初始化方式如下:
d = {}
for k, v in iterable:
d[k] = v
dict(**kwargs) -> new dictionary initialized with the name=value pairs
# dict (** kwa rgs )->用 name = value 对初始化的新字典
in the keyword argument list. For example: dict(one=1, two=2)
"""定义方式:①显示定义形式:{key:value, key:value, key:value}
key: 在字典里面必须是唯一的,不可变类型的数据。
哪些数据类型不可变的:不可变的元组,基本类型:int,float,bool,str,bytes
value: 没有唯一的限制,各种类型的数据都可以。
也可以存储不同类型的数据。
能作为字典key的数据类型一定是不可变的数据类型,list是可变的所以不行。
dict_data = {1: 1, 1.1: 1, 1 + 1j: 1, "汉字": 1, b'x11': 1, True: 3, None: 1,
(1, 2, 3): 1}
print(dict_data, type(dict_data))
# {1: 3, 1.1: 1, (1+1j): 1, '汉字': 1, b'x11': 1, None: 1, (1, 2, 3): 1} <class 'dict'>注意:因为True的值等于1,所以结果里不见True
定义方式:②dict():传入2-element为元素的序列
dict_data = dict(one=2, two=3)
print(dict_data, type(dict_data)) # {'one': 2, 'two': 3} <class 'dict'>
dict_data = dict({1: 2})
print(dict_data, type(dict_data)) # {1: 2} <class 'dict'>
# key: value
# 序列的格式:序列中的每个元素应该包含两部分,一部分对应字典的key,一部分对应字典的value
# 所以排除了字符串和字节,可以是元组或列表将元组和列表转换成字典:
# ((1, 2),(2, 3))
dict_data = dict([(1, 2), (2, 3)])
print(dict_data, type(dict_data)) # {1: 2, 2: 3} <class 'dict'>5. dict中所有方法的使用(10种)
- clear():清除字典中所有键值对。
"""
| clear(...)
| D.clear() -> None. Remove all items from D. 从D中移除所有项目。
"""
dict_data = dict([(1, 2), (2, 3)])
dict_data.clear()
print(dict_data) # {}- copy():浅拷贝,a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象,相互影响。
"""
| copy(...)
| D.copy() -> a shallow copy of D
"""
dict_a = {1: [1, 2, 3]}
dict_b = dict_a.copy()
print(dict_a, dict_b)- get():如果键存在于字典中,则返回该键的值。如果未找到,则返回 None。指定可选参数之后,未找到返回默认值。
"""
| get(self, key, default=None, /)
| Return the value for key if key is in the dictionary, else default.
如果键在字典中,则返回键的值,否则为默认值
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
print(dict_data.get(2)) # b
print(dict_data.get(4)) # None
print(dict_data.get(4, "d")) # d, 指定可选参数- items():返回字典中的键值对列表。items() 返回包含键值对的元组列表。每个元组中的第一项是键,第二项是键的值。
"""
| items(...)
| D.items() -> a set-like object providing a view on D's items
一个类似集合的对象,提供D的项的视图
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
print(dict_data.items()) # dict_items([(1, 'a'), (2, 'b'), (3, 'c')])- keys():返回字典中的所有键的列表。
"""
| keys(...)
| D.keys() -> a set-like object providing a view on D's keys
一个类似集合的对象,提供D键的视图
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
print(dict_data.keys()) # dict_keys([1, 2, 3])- pop():从字典中删除一个键,如果它存在,并返回它的值。如果不存在,则引发异常KeyError。指定可选参数,不存在时返回默认值,不引发异常。
"""
| pop(...)
| D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
| 删除指定的键并返回相应的值。
| If key is not found, default is returned if given, otherwise KeyError is raised
如果找不到键,则返回默认值(如果给定),否则会引发KeyError
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
print(dict_data.pop(3)) # c
print(dict_data) # {1: 'a', 2: 'b'}
# dict_data.pop(3) # 报KeyError异常
print(dict_data.pop(3, "d")) # d- popitem():移除最后的(键、值)对并将其作为元组返回。对按后进先出的顺序返回。如果dict为空,则引发KeyError。
"""
| popitem(self, /)
| Remove and return a (key, value) pair as a 2-tuple.
| 移除(键、值)对并将其作为2元组返回。
| Pairs are returned in LIFO (last-in, first-out) order.
对按后进先出的顺序返回。
| Raises KeyError if the dict is empty.
如果dict为空,则引发KeyError。
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
print(dict_data.popitem()) # (3, 'c')
print(dict_data.popitem()) # (2, 'b')
print(dict_data.popitem()) # (1, 'a')
# dict_data.popitem() # 报KeyError异常- setdefault():和get()类似,如果键存在于字典中,则返回该键的值。如果未找到,则返回 None。指定可选参数之后,未找到返回默认值。 但如果键不存在于字典中,将会添加键并将值设为default
"""
| setdefault(self, key, default=None, /) 设置默认值
| Insert key with a value of default if key is not in the dictionary.
| 如果关键字不在字典中,请插入默认值为的关键字。
| Return the value for key if key is in the dictionary, else default.
如果键在字典中,则返回键的值,否则为默认值。
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
print(dict_data.setdefault(2)) # b
print(dict_data.setdefault(4)) # None
print(dict_data.setdefault(5, "d")) # d
print(dict_data) # {1: 'a', 2: 'b', 3: 'c', 4: None, 5: 'd'}- update():将字典与另一个字典或可迭代的键值对合并。当有相同键值的情况, 会直接替换成 update 的值。
"""
| update(...) 更新
| D.update([E, ]**F) -> None. Update D from dict/iterable E and F. 从dict/iterable E和F更新D。
| If E is present and has a .keys() method, then does: for k in E: D[k] = E[k]
如果E存在且有a.keys()方法,然后执行:对于E中的k:D[k]=E[k]
| If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v
如果E存在且缺少a.keys()方法,然后执行:对于k,E中的v:D[k]=v
| In either case, this is followed by: for k in F: D[k] = F[k]
在任何一种情况下,后面都是:对于F中的k:D[k]=F[k]
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
dict_data1 = {4: 'd', 5: 'e', 6: "f"}
dict_data.update(dict_data1)
print(dict_data) # {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f'}
# 键相同的情况,更新使用的值为update
a = {1: 2, 2: 2}
b = {1: 1, 3: 3}
b.update(a)
print(b) # {1: 2, 3: 3, 2: 2}- values():返回字典中的值的列表。
"""
| values(...) 值
| D.values() -> an object providing a view on D's values
提供D值视图的对象
"""
dict_data = {1: 'a', 2: 'b', 3: "c"}
print(dict_data.values()) # dict_values(['a', 'b', 'c'])6. list或dict浅拷贝画图加代码解释
python中可以通过id()方法查看对象的“身份证号”,一个对象的id值在CPython解释器里就代表它在内存中的地址。此处所说的对象应该特指复合类型的对象(如类、list等),对于字符串、整数等类型,变量的id是随值的改变而改变的。
def id(*args, **kwargs): # real signature unknown
"""
Return the identity of an object.
This is guaranteed to be unique among simultaneously existing objects.
(CPython uses the object's memory address.)
"""
pass- a = 1 b = a: 赋值引用,a 和 b 都指向同一个对象。内存中真实存在的是1,a = 1是在1上打了一个标签a,b = a则是在1上又打了一个标签b
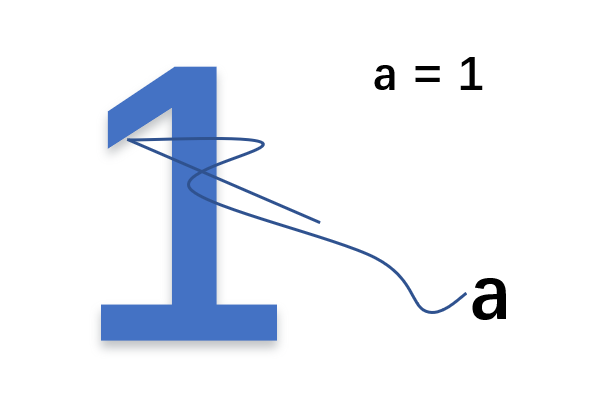
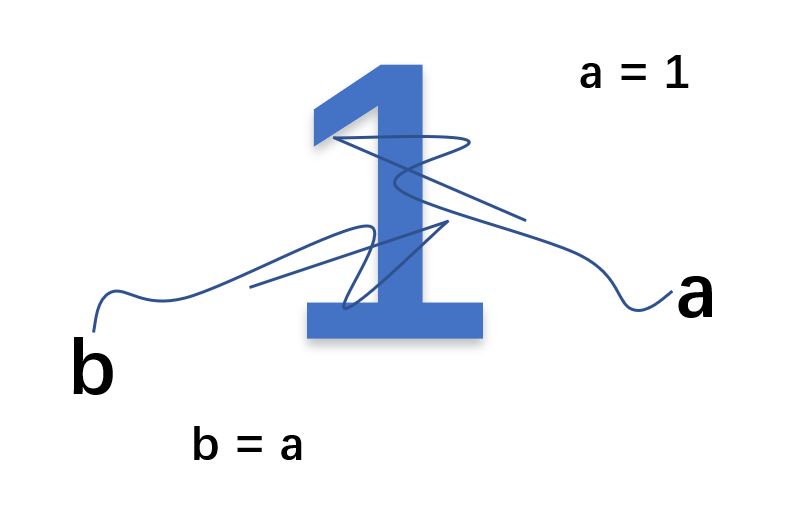
代码解释如下:
a = 1
b = 1
c = b
print(id(1)) # 1858782521648
print(id(a)) # 1858782521648
print(id(b)) # 1858782521648
print(id(c)) # 1858782521648- b = a.copy()浅拷贝:,a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。所以如果更改a或b中的值,另一个也会改变。
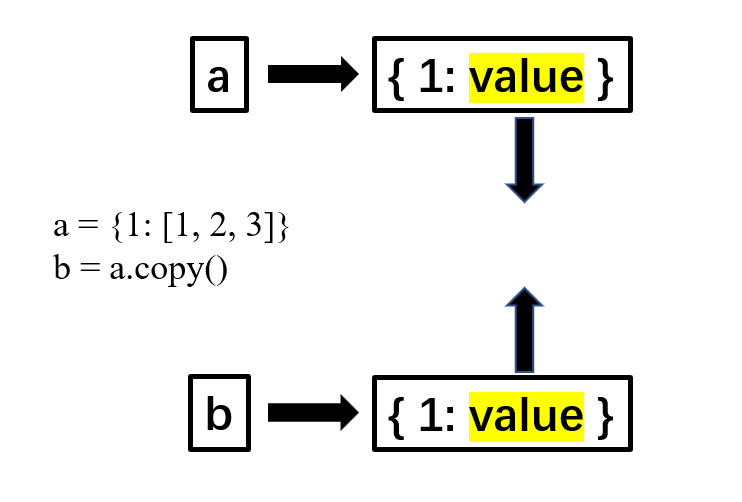
代码解释如下:
a = {1: [1, 2, 3]}
b = a.copy()
print(a, b)
print(id(a)) # 查看a的id:1211503294912
print(id(b)) # 查看b的id:1211503294784
print(id(list(a.keys())[0])) # 查看a中key的id:1211498916144
print(id(list(a.keys())[0])) # 查看b中key的id:1211498916144
print(id(a[1])) # 查看a中key为1的id:1211503295040
print(id(b[1])) # 查看b中key为1的id:1211503295040
a[1][2] = 5 # 修改的是a中key为1对应值当中的索引为2的元素的值
print(a, b) # {1: [1, 2, 5]} {1: [1, 2, 5]}- b = copy.deepcopy(a)深度拷贝:a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的,互不影响。

代码解释如下:
# 深copy
a = {1: [1, 2, 3]}
b = copy.deepcopy(a)
print(a, b)
print(id(a)) # 查看a的id:2742925896384
print(id(b)) # 查看b的id:2742923121728
print(id(a[1])) # 查看a中key为1的id:2742925896832
print(id(b[1])) # 查看b中key为1的id:2742925896768
a[1][2] = 5
print(a, b) # {1: [1, 2, 5]} {1: [1, 2, 3]}














 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











