






一、CASE表达式
1.简单表达式和搜索表达式
类似功能:DECODE(Oracle)、IF (MySQL)
分为简单CASE表达式和搜索CASE表达式
--简单CASE表达式和搜索CASE表达式
--simple case expression
case sex
when '1' then 'man'
when '2' then 'woman'
else 'else' end
--searched case expression
case when sex = '1' then 'man'
when sex = '2' then 'woman'
else 'else' end
执行结果相同,搜索表达式实现范围较大,一般使用搜索表达式
注:发现为真的when子句时,CASE表达式的真假值判断会中止,剩余的when子句会被忽略,
注意when子句的排他性
--when子句被忽略的写法(不论输入值是a或b,都是frist)
case when col_1 in ('a', 'b') then 'frist'
when col_2 in ('a') then 'second'
else 'else' end
2.将已有编号方式转换为新的方式并统计
在进行非定制化统计时,我们经常会遇到将已有编号方式转换为另外一种便于分析的方式并进行统计的需求。
例如,现在有一张按照“‘1:北海道’、‘2:青森’、……、‘47:冲绳’”这种编号方式来统计都道府县 2 人口的表,我们需要以东北、关东、九州等地区为单位来分组,并统计人口数量。具体来说,就是统计下表 PopTbl 中的内容,得出如右表“统计结果”所示的结果。

--使用case表达式
select case pref_name
when '德岛' then '四国'
when '香川' then '四国'
when '爱媛' then '四国'
when '高知' then '四国'
when '福冈' then '九州'
when '佐贺' then '九州'
when '长崎' then '九州'
else 'else' end as district,
sum(population)
from popTbl
group by7 case pref_name
when '德岛' then '四国'
when '香川' then '四国'
when '爱媛' then '四国'
when '高知' then '四国'
when '福冈' then '九州'
when '佐贺' then '九州'
when '长崎' then '九州'
else 'else' end
如果对转换前的列“pref_name ”进行 GROUP BY ,就得不到正确的结果
要按人口数量等级(pop_class )查询都道府县个数的时候,就可以像下面这样写 SQL 语句。
-- 按人口数量等级划分都道府县
SELECT CASE WHEN population < 100 THEN '01'
WHEN population >= 100 AND population < 200 THEN '02'
WHEN population >= 200 AND population < 300 THEN '03'
WHEN population >= 300 THEN '04'
ELSE NULL END AS pop_class,
COUNT(*) AS cnt
FROM PopTbl
GROUP BY CASE WHEN population < 100 THEN '01'
WHEN population >= 100 AND population < 200 THEN '02'
WHEN population >= 200 AND population < 300 THEN '03'
WHEN population >= 300 THEN '04'
ELSE NULL END;
--结果
pop_class cnt
--------- ----
01 1
02 3
03 3
04 2
必须在 SELECT 子句和 GROUP BY 子句这两处写一样的 CASE 表达式较为麻烦,可更改为下述写法
但是严格来说,这种写法是违反标准 SQL 的规则的。
GROUP BY 子句比 SELECT 语句先执行,在 GROUP BY 子句中引用在 SELECT 子句里定义的别称不被允许
在 Oracle、DB2、SQL Server 等数据库里采用这种写法时就会出错。
在 PostgreSQL 和MySQL 中,这个查询语句就可以顺利执行。
-- 把县编号转换成地区编号(2) :将CASE 表达式归纳到一处
SELECT CASE pref_name WHEN '德岛' THEN '四国'
WHEN '香川' THEN '四国'
WHEN '爱媛' THEN '四国'
WHEN '高知' THEN '四国'
WHEN '福冈' THEN '九州'
WHEN '佐贺' THEN '九州'
WHEN '长崎' THEN '九州'
ELSE '其他' END AS district,
SUM(population)
FROM PopTbl
GROUP BY district; ←-------GROUP BY 子句里引用了SELECT 子句中定义的别名
3.用一条 SQL 语句进行不同条件的统计
进行不同条件的统计是 CASE 表达式的著名用法之一。
例如,我们需要往存储各县人口数量的表 PopTbl 里添加上“性别”列,然后求按性别、县名汇总的人数。具体来说,就是统计表 PopTbl2 中的数据,然后求出如表“统计结果”所示的结果。
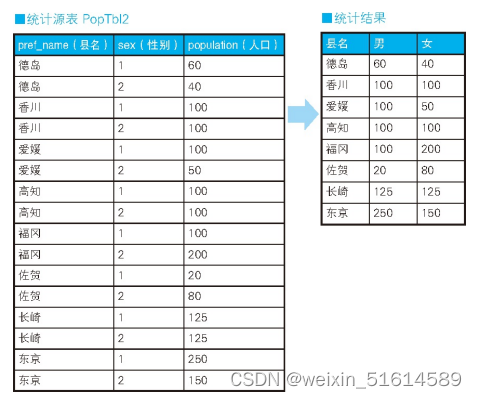
SELECT pref_name,
-- 男性人口
SUM( CASE WHEN sex = '1' THEN population ELSE 0 END) AS cnt_m,
-- 女性人口
SUM( CASE WHEN sex = '2' THEN population ELSE 0 END) AS cnt_f
FROM PopTbl2
GROUP BY pref_name;
4.用 CHECK 约束定义多个列的条件关系
假设某公司规定“女性员工的工资必须在 20 万日元以下”,而在这个公司的人事表中,这条无理的规定是使用CHECK 约束来描述的,代码如下所示。
CONSTRAINT check_salary CHECK ( CASE WHEN sex = '2'
THEN CASE WHEN salary <= 200000
THEN 1 ELSE 0 END
ELSE 1 END = 1 )
在这段代码里,CASE 表达式被嵌入到 CHECK 约束里,描述了“如果是女性员工,则工资是 20 万日元以下”这个命题。在命题逻辑中,该命题是叫作蕴含式(conditional)的逻辑表达式,记作 P → Q。
逻辑与也是一个逻辑表达式,意思是“P 且 Q”,记作 P ∧ Q。用逻辑与改写的 CHECK 约束如下所示。
CONSTRAINT check_salary CHECK
( sex = '2' AND salary <= 200000 )
这两个约束的程序行为不一样。如果在 CHECK 约束里使用逻辑与,该公司将不能雇佣男性员工。而如果使用蕴含式,男性也可以在这里工作。
蕴含与更为宽松
5.在 UPDATE 语句里进行条件分支
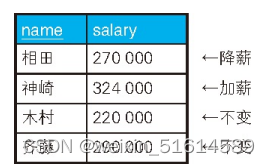
假设现在需要根据以下条件对该表的数据进行更新。
- 对当前工资为 30 万日元以上的员工,降薪 10%。
- 对当前工资为 25 万日元以上且不满 28 万日元的员工,加薪20%。
按照这些要求更新完的数据应该如下表所示。
-- 用CASE 表达式写正确的更新操作
UPDATE Salaries
SET salary = CASE WHEN salary >= 300000 THEN salary * 0.9
WHEN salary >= 250000 AND salary < 280000 THEN salary * 1.2
ELSE salary END;
需要注意的是,SQL 语句最后一行的 ELSE salary 非常重要,必须写上。因为如果没有它,条件 1 和条件 2 都不满足的员工的工资就会被更新成 NULL 。
6.表之间的数据匹配
在 CASE 表达式里,我们可以使用 BETWEEN 、LIKE和 < 、> 等便利的谓词组合,以及能嵌套子查询的 IN 和 EXISTS 谓词。因此,CASE 表达式具有非常强大的表达能力。
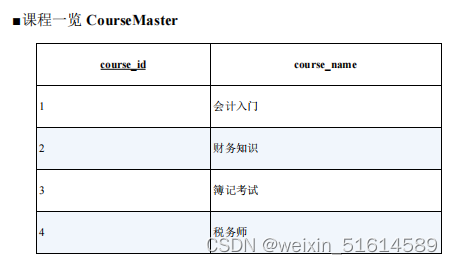
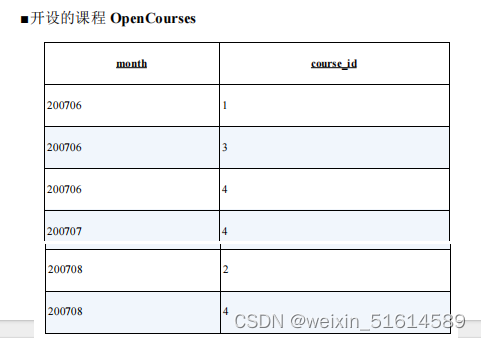
--生成结果
course_name 6 月 7 月 8 月
----------- ---- ---- ----
会计入门 ○ × ×
财务知识 × × ○
簿记考试 ○ × ×
税务师 ○ ○ ○
--
-- 表的匹配:使用IN 谓词
SELECT course_name, CASE WHEN course_id IN (SELECT course_id FROM OpenCourses WHERE month = 200706)
THEN '○' ELSE '×' END AS "6 月",
CASE WHEN course_id IN (SELECT course_id FROM OpenCourses WHERE month = 200707)
THEN '○' ELSE '×' END AS "7 月",
CASE WHEN course_id IN (SELECT course_id FROM OpenCourses WHERE month = 200708)
THEN '○' ELSE '×' END AS "8 月"
FROM CourseMaster;
-- 表的匹配:使用EXISTS 谓词
SELECT CM.course_name, CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC WHERE month = 200706 AND OC.course_id = CM.course_id)
THEN '○' ELSE '×' END AS "6 月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC WHERE month = 200707 AND OC.course_id = CM.course_id)
THEN '○' ELSE '×' END AS "7 月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC WHERE month = 200708 AND OC.course_id = CM.course_id)
THEN '○' ELSE '×' END AS "8 月"
FROM CourseMaster CM;
无论使用 IN 还是 EXISTS ,得到的结果是一样的,但从性能方面来说, EXISTS 更好
7.在 CASE 表达式中使用聚合函数
有的学生同时加入了多个社团(如学号为 100、200 的学生),有的学生只加入了某一个社团(如学号为 300、400、500 的学生)。对于加入了多个社团的学生,我们通过将其“主社团标志”列设置为 Y 或者 N 来表明哪一个社团是他的主社团;对于只加入了一个社团的学生,我们将其“主社团标志”列设置为 N。
接下来,我们按照下面的条件查询这张表里的数据。
- 获取只加入了一个社团的学生的社团 ID。
- 获取加入了多个社团的学生的主社团 ID。
很容易想到的办法是,针对两个条件分别写 SQL 语句来查询。要想知道学生“是否加入了多个社团”,我们需要用HAVING 子句对聚合结果进行判断
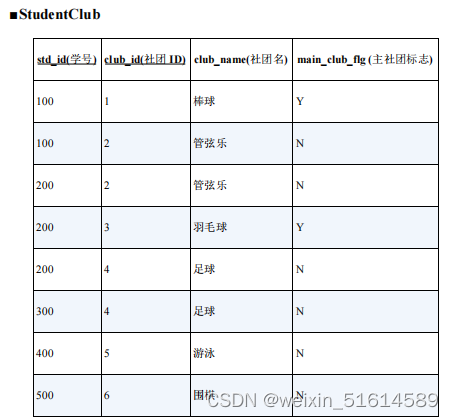
-- 条件1 :选择只加入了一个社团的学生
SELECT std_id, MAX(club_id) AS main_club FROM StudentClub
GROUP BY std_id
HAVING COUNT(*) = 1;
--执行结果 1
std_id main_club
------ ----------
300 4
400 5
500 6
-- 条件2 :选择加入了多个社团的学生
SELECT std_id, club_id AS main_club FROM StudentClub
WHERE main_club_flg = 'Y' ;
--总结语句
SELECT std_id, CASE WHEN COUNT(*) = 1 -- 只加入了一个社团的学生
THEN MAX(club_id) ELSE MAX(CASE WHEN main_club_flg = 'Y'
THEN club_id ELSE NULL END)
END AS main_club
FROM StudentClub
GROUP BY std_id;
8.练习题
练习题1-1-1 :多列数据的最大值
用 SQL 从多行数据里选出最大值或最小值很容易——通过 GROUP BY子句对合适的列进行聚合操作,并使用 MAX或 MIN 聚合函数就可以求出。
那么,从多列数据里选出最大值该怎么做呢?样本数据如下表所示。
P45
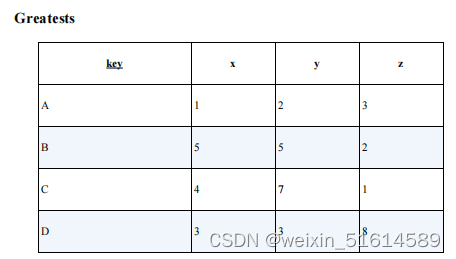
key greatest
----- ---------
A 2
B 5
C 7
D 3
--答案1
二、自连接的用法
1.可重排列、排列、组合
假设这里有一张存放了商品名称及价格的表,表里有“苹果、橘子、香蕉”这 3 条记录。在生成用于查询销售额的表等的时候,我们有时会需要获取这些商品的组合。
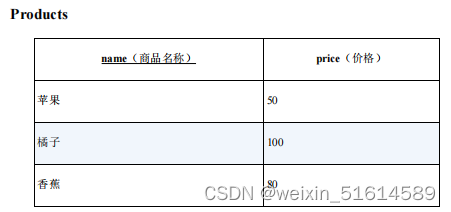
这里所说的组合其实分为两种类型。一种是有顺序的有序对(ordered pair),另一种是无顺序的无序(unordered pair)。
有序对用尖括号括起来,如 <1, 2>;无序对用花括号括起来,如 {1, 2}。在有序对里,如果元素顺序相反,那就是不同的对,因此 <1, 2> ≠ <2, 1> ;
而无序对与顺序无关,因此 {1, 2} = {2, 1}。用学校里学到的术语来说,这两类分别对应着“排列”和“组合”。用 SQL 生成有序对非常简单。像下面这样通过交叉连接生成笛卡儿积(直积),就可以得到有序对 。
select p1.name as name_1, p2.name as name_2
from products p1,products p2

执行结果里每一行(记录)都是一个有序对。因为是可重排列,所以结果行数为 3^2 = 9。结果里出现了(苹果, 苹果)这种由相同元素构成的对,而且(橘子, 苹果)和(苹果, 橘子)这种只是调换了元素顺序的对也被当作不同的对了。这是因为,该查询在生成结果集合时会区分顺序。
接下来,我们思考一下如何更改才能排除掉由相同元素构成的对。首先,为了去掉(苹果, 苹果)这种由相同元素构成的对,需要像下面这样加上一个条件,然后再进行连接运算。
select p1.name as name_1, p2.name as name_2
from products p1,products p2
where p1.name <> p2.name
这次的处理结果依然是有序对。接下来我们进一步对(苹果, 橘子)和(橘子, 苹果)这样只是调换了元素顺序的对进行去重。
同样地,存在 P1 和 P2 两张表。在加上“不等于”这个条件后,这条 SQL 语句所做的是,按字符顺序排列各商品,只与“字符顺序比自己靠前”的商品进行配对,
-- 用于获取组合的SQL 语句:扩展成3 列
SELECT P1.name AS name_1, P2.name AS name_2, P3.name AS name_3
FROM Products P1, Products P2, Products P3
WHERE P1.name > P2.name
AND P2.name > P3.name;
--output
name_1 name_2 name_3
------- -------- --------
香蕉 苹果 橘子
2.删除重复行
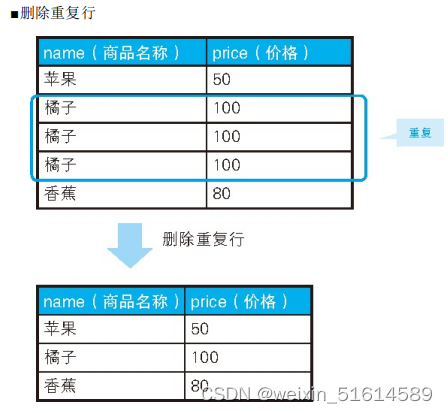
delete from products p1
where rowid < ( select MAX(p2.rowid)
from products p2
where p1.name = p2.name
and p1.price = p2,price);
3.查找局部不一致的列
假设有下面这样一张住址表,主键是人名,同一家人家庭 ID 一样。相信在寄送新年贺卡等时,有人会制作这样一张表吧。
一般来说,同一家人应该住在同一个地方(如加藤家),但也有像福尔摩斯和华生这样不是一家人却住在一起的情况。
接下来,我们看一下前田夫妇。这两个人并没有分居,只是夫人的住址写错了而已。前面说了,如果家庭 ID 一样,住址也必须一样,因此这里需要修改一下。
那么我们该如何找出像前田夫妇这样的“是同一家人但住址却不同的记录”呢?
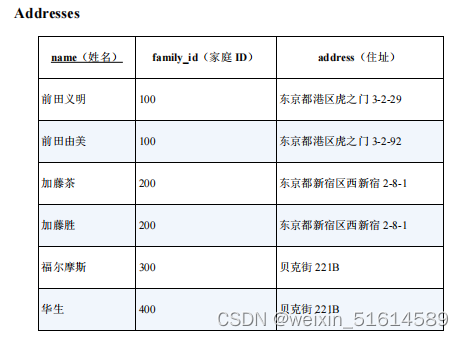
--用于查找是同一家人但住址确不同的记录的SQL
select distinct a1.name, a1.address
from addesses a1, address a2
where a1.family_id = a2.family_id
and a1.address <> a2.address;
问题:从下面这张商品表里找出价格相等的商品的组合 。
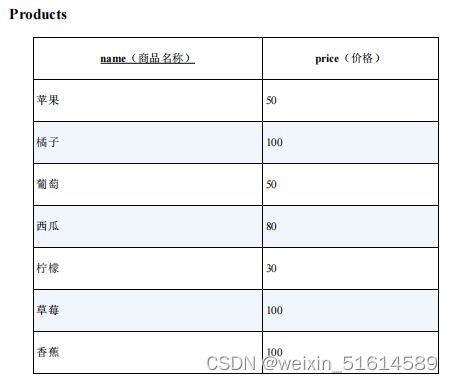
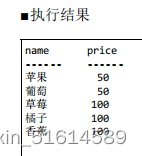
select distinct p1.name, p2.price
from products p1,products p2
where p1.price = p2.price
and p1.name <> p2.name
4.排序
如 Oracle、DB2 数据库的 RANK 函数等已实现排序功能
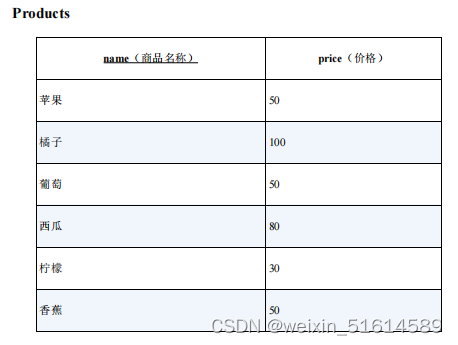
--使用窗口函数
select name, price, RANK() over (order by price desc) as rank_1
dense_rank() over (order by price desc) as rank_2
from products;
--不依赖于具体数据库来实现的方法
select p1.name, p2.price, (select count(p2.price)
from products p2
where p2.price > p1.price) + 1 as rank_1
from products p1
order by rank_1;
本节要点。
- 自连接经常和非等值连接结合起来使用。
- 自连接和 GROUP BY 结合使用可以生成递归集合。
- 将自连接看作不同表之间的连接更容易理解。
- 应把表看作行的集合,用面向集合的方法来思考。
- 自连接的性能开销更大,应尽量给用于连接的列建立索引。
三、三值逻辑和NULL
1.NULL的有关知识

请注意这三个真值之间有下面这样的优先级顺序。
AND 的情况: false > unknown > true
OR 的情况: true > unknown > false
问题:假设 a = 2, b = 5, c = NULL ,此时下面这些式子的真值是什么?
- a < b AND b > c
- a > b OR b < c
- a < b OR b < c
- NOT (b <> c)
答案- unknown ;2. unknown ;3. true ;4. unknown
2. NOT IN 和 NOT EXISTS 不是等价的
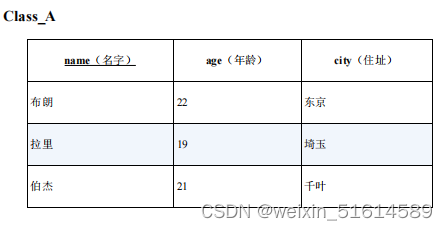
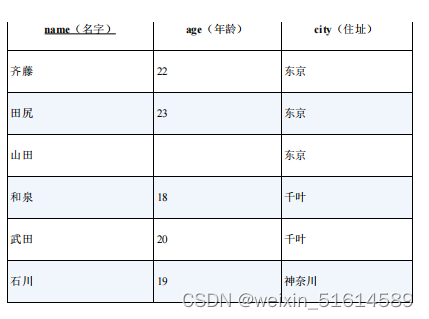
EXISTS 谓词永远不会返回 unknown 。EXISTS 只会返回 true 或者false 。因此就有了 IN 和 EXISTS 可以互相替换使用,而 NOT IN和 NOT EXISTS 却不可以互相替换的混乱现象。
select * from class_A A
where not exists ( select * from class_B B
where A.age = B.age
and B.city = '东京')
3.限定谓词和 NULL
SQL 里有 ALL 和 ANY 两个限定谓词。因为 ANY 与 IN 是等价的,所以我们不经常使用 ANY 。
ALL 可以和比较谓词一起使用,用来表达“与所有的××都相等”,或“比所有的××都大”的意思。
查询“比 B 班住在东京的所有学生年龄都小的 A 班学生”的 SQL 语句。
select * from class_A
where age < all (select age from class_B
where city = '东京');
本节要点。
- NULL 不是值。
- 因为 NULL 不是值,所以不能对其使用谓词。
- 对 NULL 使用谓词后的结果是 unknown 。
- unknown 参与到逻辑运算时,SQL 的运行会和预想的不一样。
- 按步骤追踪 SQL 的执行过程能有效应对 4 中的情况。
四、HAVING 子句的力量
1、寻找缺失的编号
- 对“连续编号”列按升序或者降序进行排序。
- 循环比较每一行和下一行的编号。
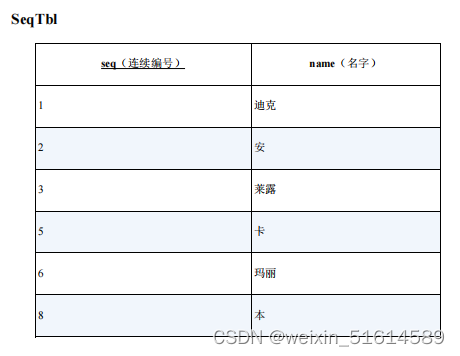
select '存在缺失的编号' as gap
from seqTbl
having count(*) <> MAX(seq)
2.HAVING求众数
注:GROUP BY 子句的作用是根据最初的集合生成若干个子集
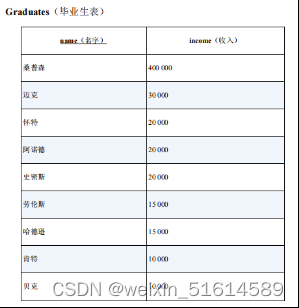
select income, count(*) as cnt
from graduates
group by income
having count(*) >= (select MAX(cnt) from(
select count(*) as cnt
from graduates group by income) tmp);
3.用关系除法运算进行购物篮分析
购物篮分析是市场分析领域常用的一种分析手段,用来发现“经常被一起购买的商品”具有的规律。有一个有名的例子:某家超市发现,虽然不知为什么,但啤酒和纸尿裤经常被一起购买(也许是因为来买纸尿裤的爸爸都会想顺便买些啤酒回去),于是便将啤酒和纸尿裤摆在相邻的货架,从而提升了销售额。

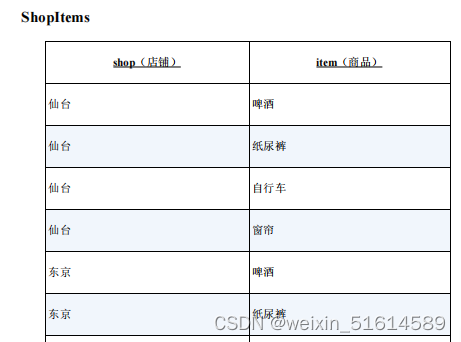
--查询啤酒、纸尿裤和自行车同时在库的店铺
select s1.shop
from shopItem s1, item I
where s1.item = I.item
group by s1.shop
having count(s1.item) = (select count(item) from item);
本节要点。
- 表不是文件,记录也没有顺序,所以 SQL 不进行排序。
- SQL 不是面向过程语言,没有循环、条件分支、赋值操作。
- SQL 通过不断生成子集来求得目标集合。SQL 不像面向过程语言那样通过画流程图来思考问题,而是通过画集合的关系图来思考。
- GROUP BY 子句可以用来生成子集。
- WHERE 子句用来调查集合元素的性质,而 HAVING 子句用来调查集合本身的性质。
五、外连接的用法(outer join)
1.用外连接进行行列转换 (1)(行→列):制作交叉表
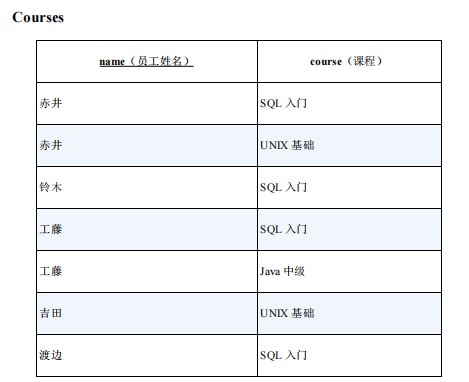
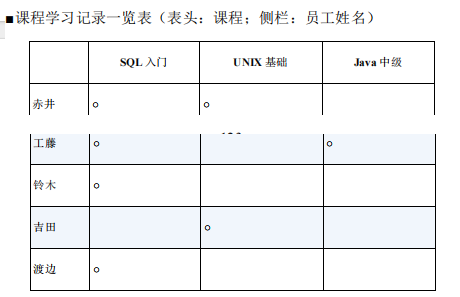
,即嵌套使用 CASE 表达式。CASE 表达式可以写在 SELECT 子句里的聚合函数内部,也可以写在聚合函数外部
(请参考 1-1 节)。这里,我们先把 SUM 函数的结果处理成 1 或者NULL ,然后在外层的 CASE 表达式里将 1 转换成○。
select name,
case when sum(case when course = 'SQL 入门' then 1 else null end) = 1
then 'o' else null end as 'SQL 入门',
case when sum(case when course = 'UNIX 基础' then 1 else null end)= 1
then 'o' else null end as 'UNIX 基础',
case when sum(case when course = 'JAVA 中级' then 1 else null end)= 1
then 'o' else null end as 'JAVA 中级'
from course
group by name;
2.用外连接进行行列转换(2)(列→行):汇总重复项于一列
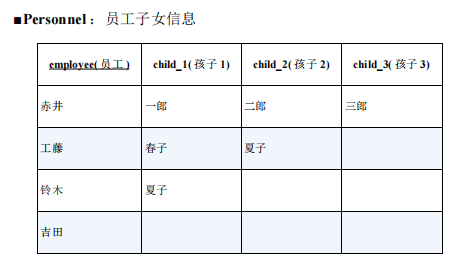
将这张表转换成行格式的数据。这里使用 UNION ALL 来实现
--列数据转换成行数据,使用UNION ALL
select employee, child_1 as from personne1
union all
select employee, child_2 as from personne1
union all
select employee, child_3 as from personne1;
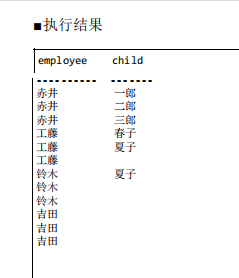
因为 UNION ALL 不会排除掉重复的行,所以即使吉田没有孩子,结果里也会出现 3 行相关数据。
把结果存入表时,最好先排除掉“child”列为 NULL 的行。

--先生成存储子女列表的视图(孩子主表)
create view children(child)
as select child_1 from personnel union
select child_2 from personnel union
select child_3 from personnel;
--获取员工子女列表的SQL语句(没有孩子的员工也要输出)
select EMP.employee, children,child
from personnel EMP
left outer join children
on children.child in (EMP.child_1, EMP.child_2, EMP.child_3);
3.章节复习
标准 SQL 里定义了外连接的三种类型,如下所示。
1.左外连接(LEFT OUTER JOIN)
2.右外连接(RIGHT OUTER JOIN)
3.全外连接(FULL OUTER JOIN)
其中,左外连接和右外连接没有功能上的区别。用作主表的表写在运算符左边时用左外连接,写在运算符右边时用右外连接。
在这三种里,全外连接相对来说使用较少。
■内连接相当于求集合的积(INTERSECT)
■全外连接相当于求集合的和(UNION)
用外连接求差集:A - B
select A.id as id, A.name as A_name
from class_A A left outer join class_B B
on A.id = B.id
where B.name is null;
用外连接求差集:B - A
SELECT B.id AS id, B.name AS B_name
FROM Class_A A RIGHT OUTER JOIN Class_B B
ON A.id = B.id
WHERE A.name IS NULL;
本节要点。
- SQL 不是用来生成报表的语言,所以不建议用它来进行格式转换。
- 必要时考虑用外连接或 CASE 表达式来解决问题。
- 生成嵌套式表侧栏时,如果先生成主表的笛卡儿积再进行连接,很容易就可以完成。
- 从行数来看,表连接可以看成乘法。因此,当表之间是一对多的关系时,连接后行数不会增加。
- 外连接的思想和集合运算很像,使用外连接可以实现各种集合运算。
六.用 SQL 进行集合运算
1.寻找相等的子集
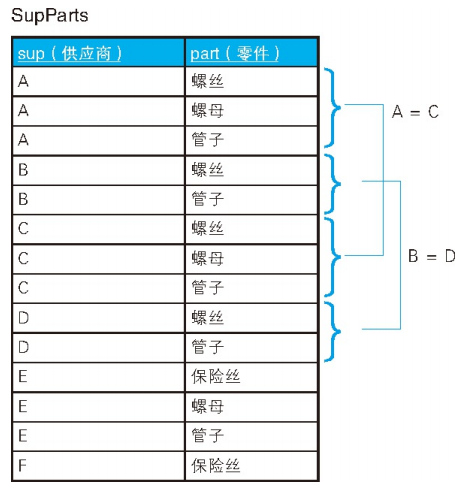
我们需要求的是,经营的零件在种类数和种类上都完全相同的供应商组合。
由上面的表格我们可以看出,答案是 A-C 和 B-D 这两组。
select sp1.sup as s1, sp2.sup as s2
from supparts sp1, suparts sp2
where sp1.sup < sp2.sup --生成供应商的全部组合
and sp1.part = sp2.part --条件1:经营同种类型的零件
group by sp1.sup, sup2.sup
having count(*) = (select count(*) from supparts sp3 --条件2:经营的零件种类数相同
where sp3.sup = sp1.sup)
and count(*) = (select count(*) from supparts sp4
where sp4.sup = sp2.sup);
)
2.用于删除重复行的高效 SQL
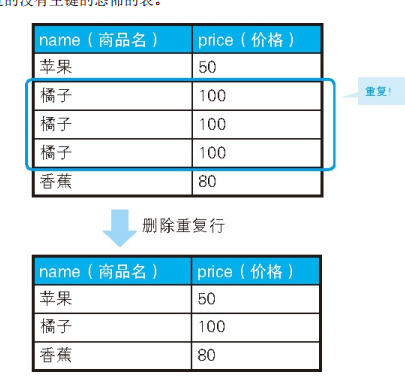
-- 用于删除重复行的高效SQL 语句(1):通过EXCEPT 求补集
DELETE FROM Products
WHERE rowid IN ( SELECT rowid -- 全部rowid
FROM Products
EXCEPT -- 减去
SELECT MAX(rowid) -- 要留下的rowid
FROM Products
GROUP BY name, price) ;
-- 删除重复行的高效SQL 语句(2):通过NOT IN 求补集
DELETE FROM Products
WHERE rowid NOT IN ( SELECT MAX(rowid)
FROM Products
GROUP BY name, price);
七.简单的性能优化
1.参数是子查询时,使用 EXISTS 代替 IN
IN 谓词非常方便,而且代码也容易理解,所以使用的频率很高。
但是方便的同时,IN 谓词却有成为性能优化的瓶颈的危险。
如果代码中大量用到了 IN 谓词,那么一般只对它们进行优化就能大幅度地提升性能。
2.避免排序
会进行排序的代表性的运算有下面这些。
GROUP BY 子句
ORDER BY 子句
聚合函数(SUM 、COUNT 、AVG 、MAX 、MIN )
DISTINCT
集合运算符(UNION 、INTERSECT 、EXCEPT )
窗口函数(RANK 、ROW_NUMBER 等)
灵活使用集合运算符的 ALL 可选项
SQL 中有 UNION 、INTERSECT 、EXCEPT 三个集合运算符。
在默认的使用方式下,这些运算符会为了排除掉重复数据而进行排序。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









