





原文:Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
1. Abstract
自然语言处理任务,如问答、机器翻译、阅读理解和摘要,通常在任务特定的数据集上,通过监督学习来完成。我们证明,语言模型在没有任何显式监督的情况下,可以在一个包含数百万网页的数据集WebText上来学习这些任务。针对阅读理解任务,GPT-2在没有使用CoQA数据集微调的情况下,其性能仍然匹配或超过4个基线模型中的3个。语言模型的容量对于zero-shot任务迁移至关重要,增加语言模型的容量能够以对数线性的方式提高跨任务的性能。GPT-2模型是一个具有15亿参数的Transformer,它在对WebText数据集欠拟合的情况下,仍然以zero-shot的方式在7个语言建模数据集上取得了SOTA结果。GPT-2生成的示例文本反映了这些改进,并且包含连贯的段落。这些发现为构建语言处理系统提供了一条很有前途的道路。
2. Method, Experiment and Result

图1. 在多个NLP任务上,WebText LMs的zero-shot性能作为模型大小的函数(随模型大小的变化)。

表1. 在WebText训练集中可以找到自然出现的英译法和法译英的示例。

表2. 4个不同大小的语言模型的架构超参数。最小的模型相当于原始GPT,最大的模型称为GPT-2。

表3. 模型在多个数据集上的zero-shot结果。这些结果是在没有任何训练或微调的情况下得到的。

图2. 模型在Children’s Book Test上的性能作为模型容量的函数(随模型大小的变化)。
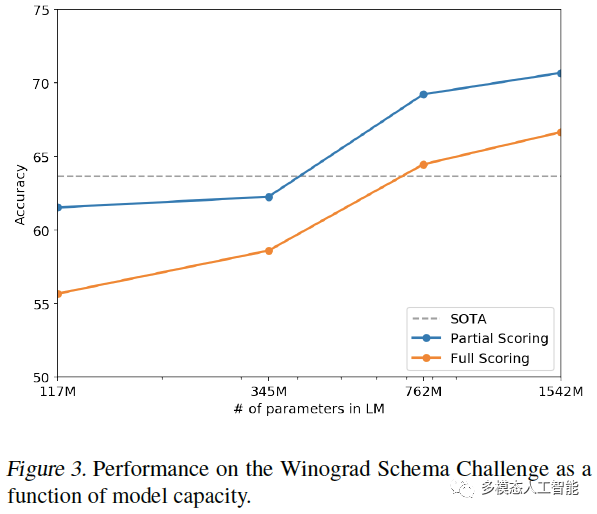
图3. 模型在Winograd Schema Challenge上的性能作为模型容量的函数(随模型大小的变化)。
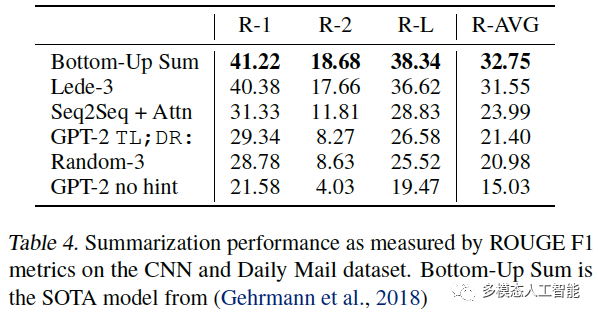
表4. 在CNN和Daily Mail数据集上,通过ROUGE F1指标来衡量模型在摘要任务上的性能。

表5. GPT-2在Natural Questions开发集上生成的30个问题的答案(按照概率排序),这些问题都不会出现在WebText训练集中。
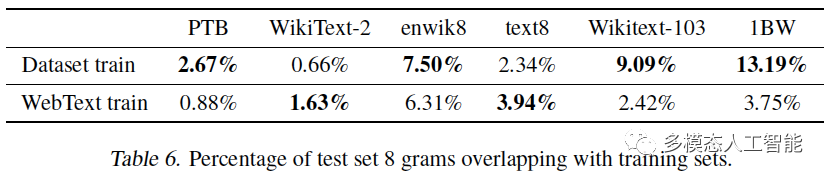
表6. 测试集与训练集重叠的百分比。
3. Conclusion / Discussion
当一个大型语言模型在足够大且多样化的数据集上训练时,它能够在许多领域和数据集上表现良好。GPT-2在7个语言建模数据集上以zero-shot的方式达到了SOTA性能。该模型在zero-shot设置下能够执行的任务的多样性表明,大容量模型能够学习如何在没有显式监督的情况下执行数量惊人的任务。
关注“多模态人工智能”公众号,一起进步!















 7311
7311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









