





原文:Huang, Zhicheng, et al. "Contrastive Masked Autoencoders are Stronger Vision Learners." arXiv preprint arXiv:2207.13532 (2022).
掩码图像建模(MIM)在各种视觉任务中取得了很好的结果。然而,要想成为更强大的视觉学习者,还有很多工作要做。为此,我们提出了对比掩码自编码器(CMAE),这是一种新的自监督预训练方法,用于学习更全面、更有效的视觉表示。CMAE通过新颖的设计,将对比学习(CL)和掩码图像建模(MIM)巧妙地统一起来,综合利用它们各自的优势,以学习实例可判别和局部可感知的表示。具体而言,CMAE由两个分支组成,其中online分支采用非对称编码器-解码器,target分支采用动量更新编码器。训练期间,online编码器从掩码图像的潜在表示中重建原始图像,以学习图像的整体特征。target编码器以完整的图像作为输入,通过与online编码器的对比学习增强了特征的可判别性。为了使CL与MIM兼容,CMAE引入了两个新的组件,一个是用于生成正视图的pixel shift,另一个是用于补充对比特征的特征解码器。由于这些新颖的设计,CMAE比MIM更有效地提高了表示的质量和迁移学习的性能。CMAE在图像分类、语义分割和目标检测等基准上实现了SOTA性能。值得注意的是,CMAE-Base模型在ImageNet上实现了85.3%的top-1精度,在ADE20k上实现了52.5%的mIoU,分别超过之前的最佳结果0.7%和1.8%。
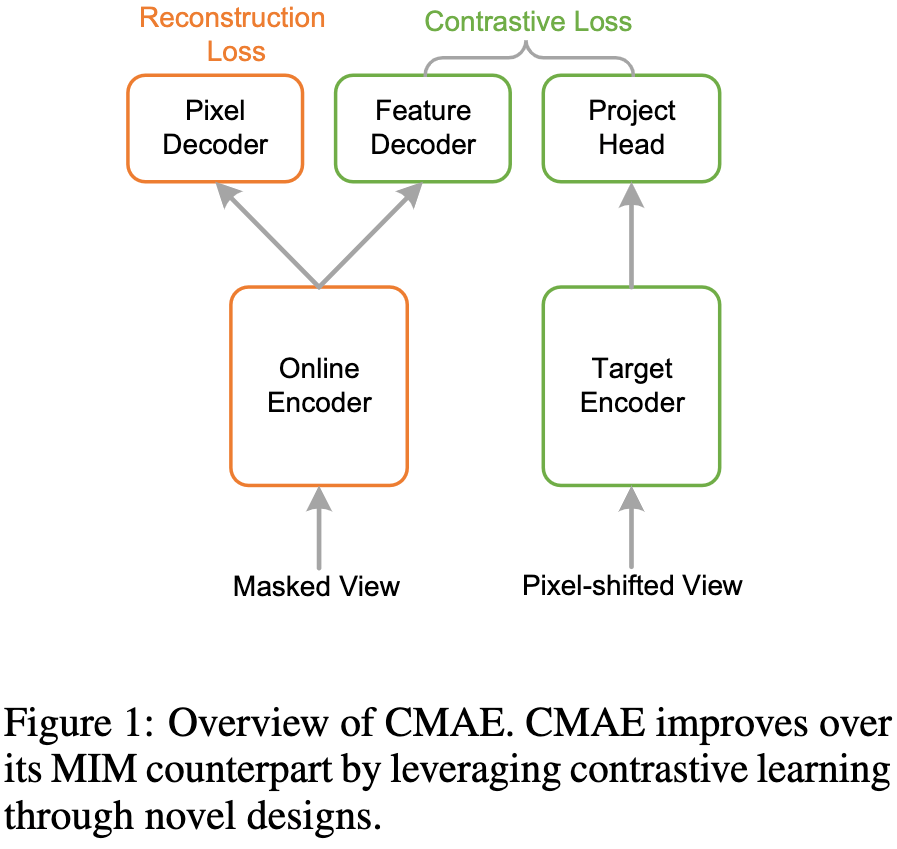
图1:CMAE总览图。CMAE创新利用对比学习,比MIM方法有所改进。
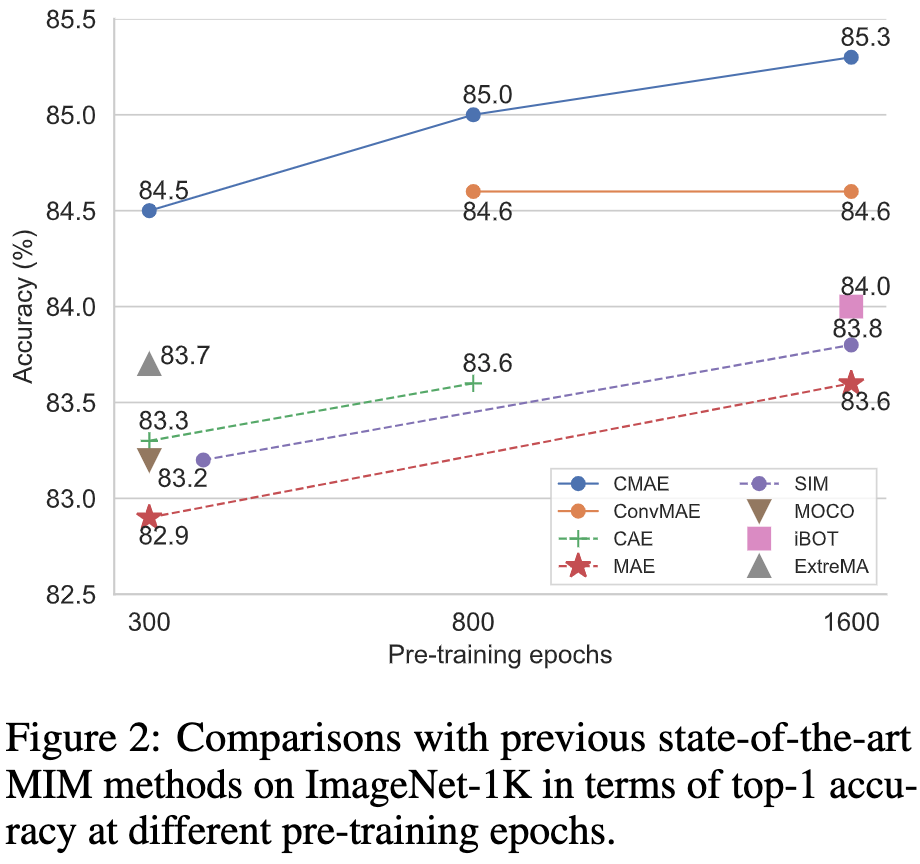
图2:在ImageNet-1k数据集上,CMAE与之前MIM方法的比较。
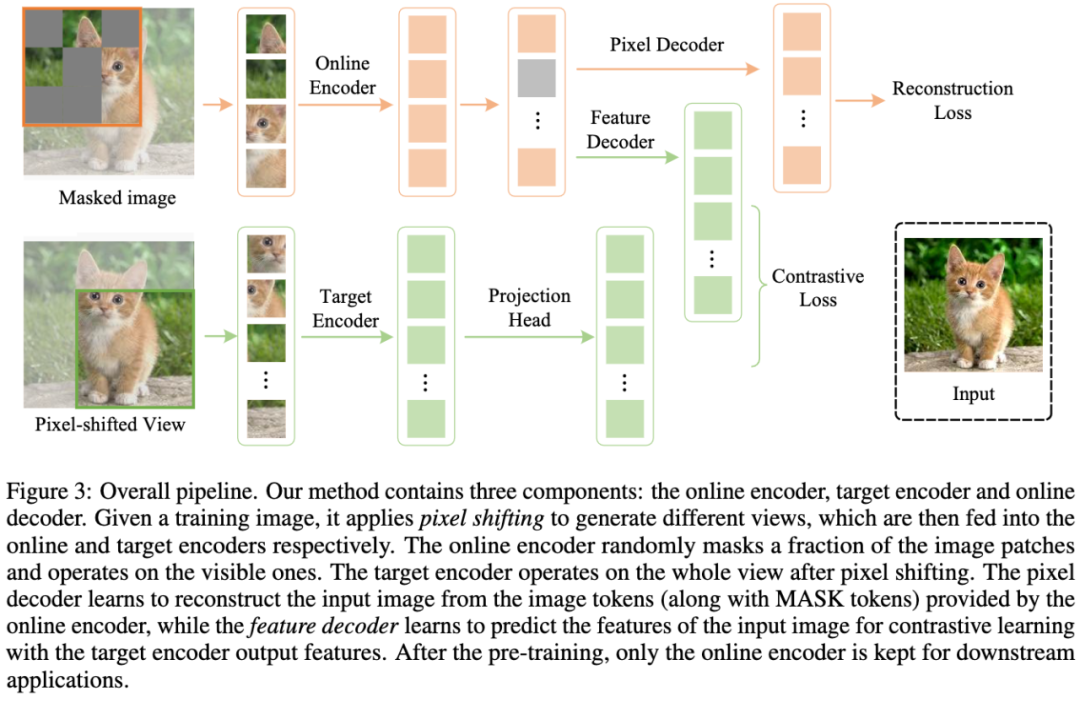
图3:CMAE总体流程图。CMAE包括三个部分:online编码器、target编码器和online解码器。给定一张训练图像,利用pixel shifting生成不同视图,然后将这些视图分别输入online编码器和target编码器。online编码器随机掩码部分patches,并对可见的patches进行编码。target编码器在pixel shifting之后对整个视图进行操作。像素解码器学习利用online编码器提供的图像tokens(连同掩码tokens)重建输入图像,特征解码器学习预测输入图像的特征,以便与target编码器输出的特征进行对比学习。在预训练之后,仅保留online编码器用于下游应用。

表1:在训练目标、输入生成和体系架构方面,CMAE与以往方法的比较。
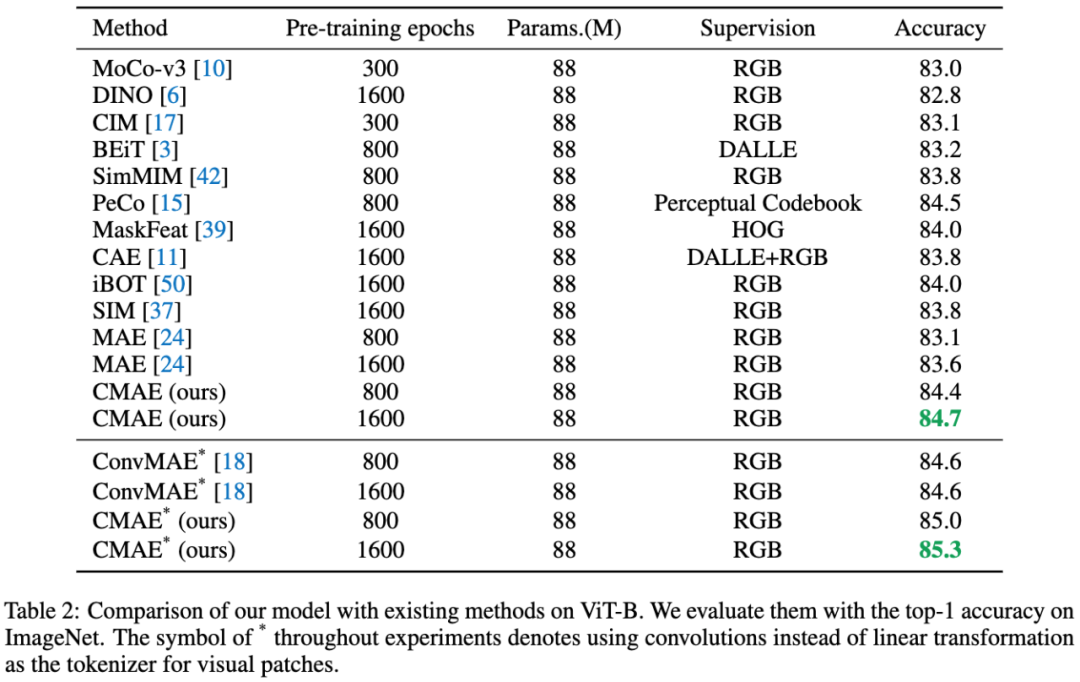
表2:在ImageNet-1k数据集上,CMAE与其他方法的比较(基于ViT-Base)。
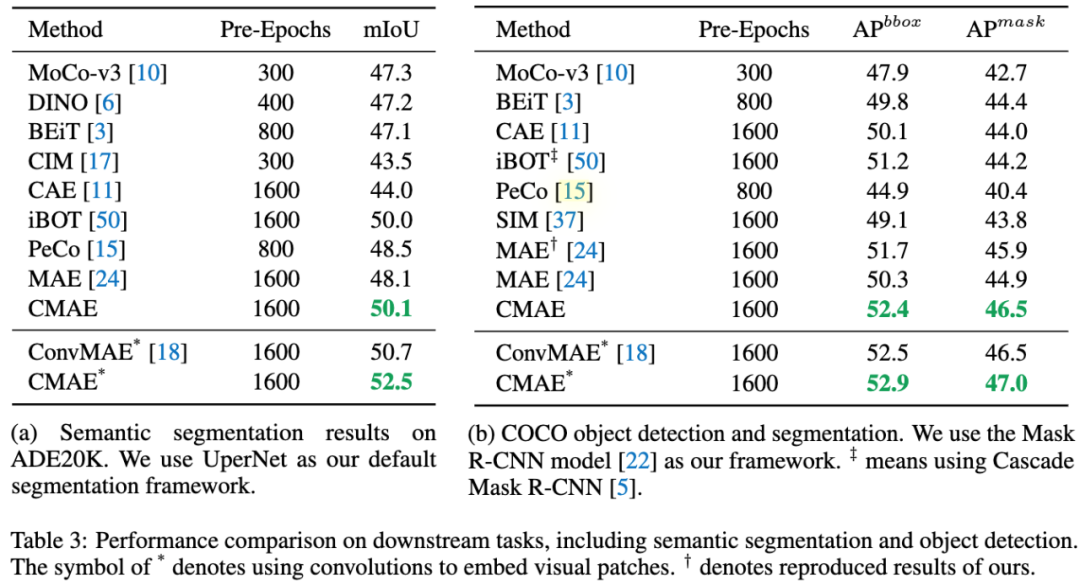
表3:CMAE与其他方法在语义分割(ADE20K)和目标检测(COCO)任务上的比较。
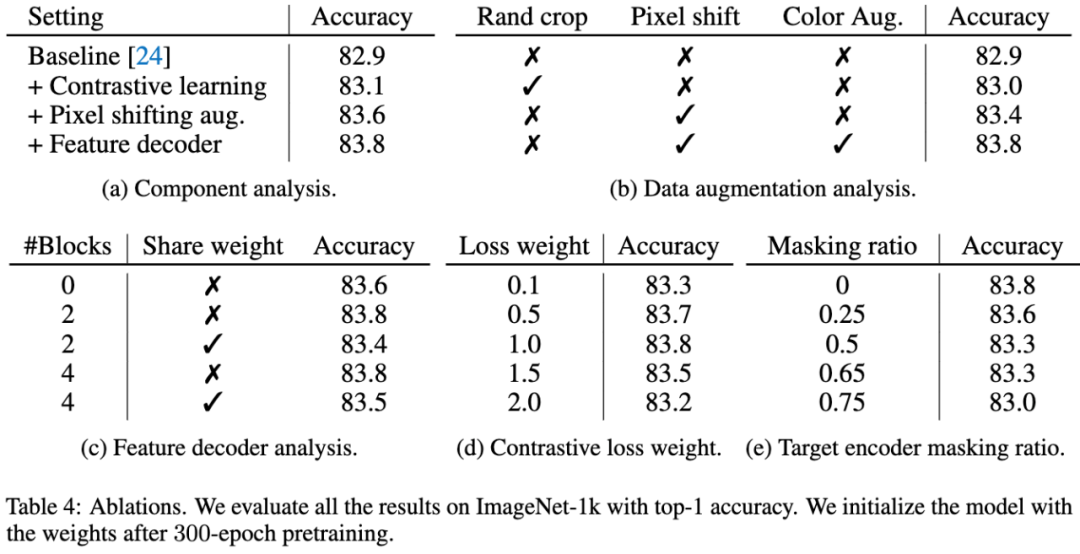
表4:消融研究的结果。
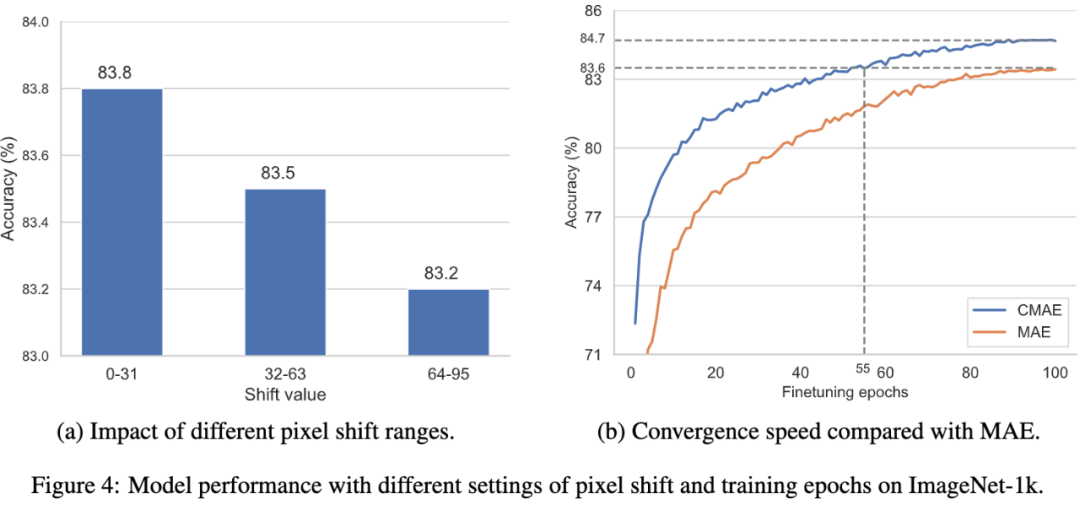
图4:在ImageNet-1k数据集上,不同pixel shift和训练轮数对模型性能的影响。
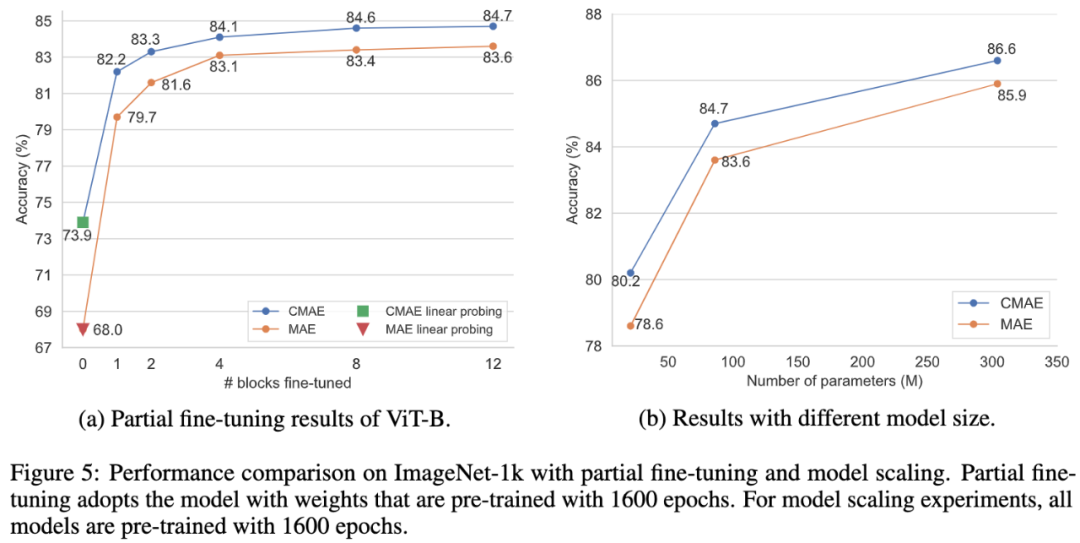
图5:在ImageNet-1k数据集上,(a)是CMAE和MAE线性分类结果的比较,(b)是CMAE和MAE在不同大小ViT上的结果比较。
本文提出了一种新的自监督学习框架——对比掩码自编码器(CMAE),旨在利用对比学习来提高MIM的表示质量。在CMAE中,我们分别从输入生成和体系架构方面提出了两种新颖的设计,以协调MIM和对比学习。大量实验证明,CMAE可以显著提高预训练表示的质量。值得注意的是,在图像分类、语义分割、目标检测三个下游任务上,CMAE取得了最先进的性能。未来,我们将研究把CMAE扩展到更大的数据集上。
多模态人工智能
为人类文明进步而努力奋斗^_^↑

















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









