







Zookeeper概述
1.官网描述
- Zookeeper解决分布式应用中经常遇到的一些数据管理问题,如集群管理,统一命名服务,分步式配置管理,分步式消息队列,分步式锁,分步式通知协调
- 多机多核,区别于JUC单机多核编程
- 服务主要有维护配置信息(配置中心),命名服务,分步式配置协调,组服务
- 包含简单的原语集(原子性),分步式应用程序基于他实现同步服务,配置维护,命名服务…
- 简单来说,Zookeeper=文件系统+监听通知机制
2.文件系统
- Zookeeper维护类似于文件系统的目录树型数据结构
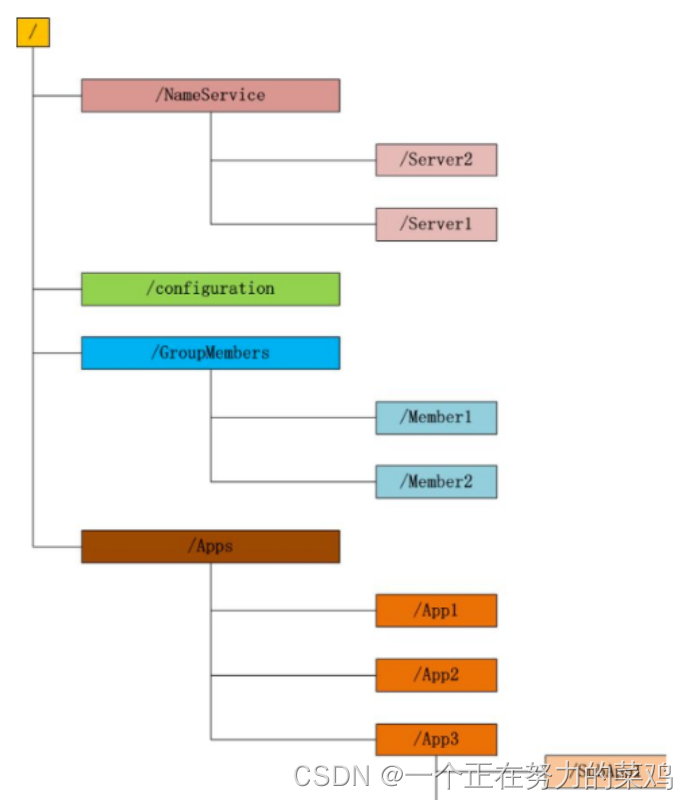
- 每个子目录被称为znode,通过路径作为唯一标识
- 与文件系统一样,我们可以自由创建删除znode,不同的是znode可以存放数据
- 5中详述
3.监听通知机制
- 客户端注册监听其关心的目录节点,当关系的目录节点变化时,Zookeeper通知客户端
4.特点
- fast fail快速失败
- 少于半数的Server挂掉不影响提供服务
Leader选举算法采用Zab协议
Zab协议核心思想是当多数Server成功,则任务成功
若有3个server,允许1个server挂掉
若有4个server,同样允许1个server挂掉
所以3个4个可靠性相同,一般选举单数个server
- 保证顺序,最终,强一致
5.常见应用场景
- 分步式配置管理
发布与订阅即配置管理,其实就是将数据发布到zk(zookeeper)节点上
供订阅者动态获取数据,实现配置信息的集中管理与动态更新
- 命名服务
zk的create node能简单的创建全局唯一path,该path可以作为名称
- 分步式通知/协调
zk的watcher实现分步式环境下不同系统间的通知与协调,实现数据实时处理
过程是不同系统监听zk上同一个znode,当监听的znode变化(包含子节点),不同系统能很快的接收通知,作出处理
- 分步式锁
zk保证数据的强一致性,zk集群中任意一节点上相同的znode数据一定相同
- 集群管理
HBase Master选举
- 分步式队列
一种是常规的先进先出队列
另一种是等到队列成员聚集后才统一按序执行
5.Zookeeper节点
- 每个子目录被称为znode,通过路径作为唯一标识
- 与文件系统一样,我们可以自由创建删除znode,不同的是znode可以存放数据
- znode存放的数据量很小(KB)
- znode维护状态Stat结构(版本号,ACL变化,时间戳),以允许缓存验证与协调更新
- 每当znode内容改变,多一个版本号,每当客户端获取数据,同时也获取版本号
- znode数据内容以原子方式读写
- znode具有一个访问控制列表,用于约束访问操作,即权限控制
- 节点类型
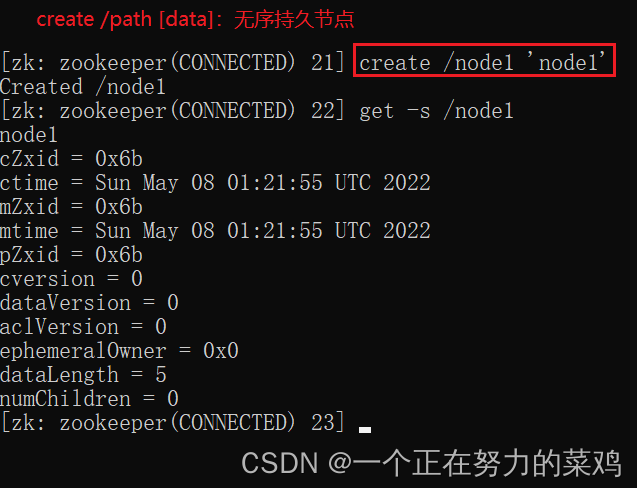
1.PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2.PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3.EPHEMERAL-临时目录节点(没有子节点)
客户端与zookeeper断开连接后,该节点被删除
4.EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
6.Zookeeper事件
- znode增删改都可以触发监听
- watch事件是一次性触发器,当watch监听的数据发生变化,则通知设置该watch的client,即watcher,此时该事件失效,当还需要监听时需重新设置
- 获取watch事件与设置新watch事件间有延迟,所以不能可靠的观察到节点的每一次变化
- watch异步发送给观察者
Zookeeper安装在Docker
- 下载zookeeper最新版镜像
docker search zookeeper//查看
docker pull zookeeper//拉取镜像
docker images//查看下载的本地镜像
docker inspect zookeeper
- 在windows下d盘中创建一个文件夹
d:
mkdir dockercontainers
cd dockercontainers
mkdir zookeeper
- 启动服务
docker run -d -e TZ="Asia/Shanghai" -p 2181:2181 -v d:\dockercontainers\zookeeper:/data --name zookeeper --restart always zookeeper
-e TZ="Asia/Shanghai" # 指定上海时区
-d # 表示在一直在后台运行容器
-p 2181:2181 # 对端口进行映射,将本地2181端口映射到容器内部的2181端口
--name # 设置创建的容器名称
-v # 将本地目录(文件)挂载到容器指定目录;
--restart always #始终重新启动zookeeper
- 查看:docker ps
- 进入zookeeper目录
- 通过Docker的link机制来对这个ZK容器进行访问
1>.docker run -it --rm --link zookeeper:zookeeper zookeeper zkCli.sh -server zookeeper//登录容器时直接进入到zkCli中
2>.docker exec -it zookeeper bash//只登录容器,不登录zkCli
Zookeeper命令
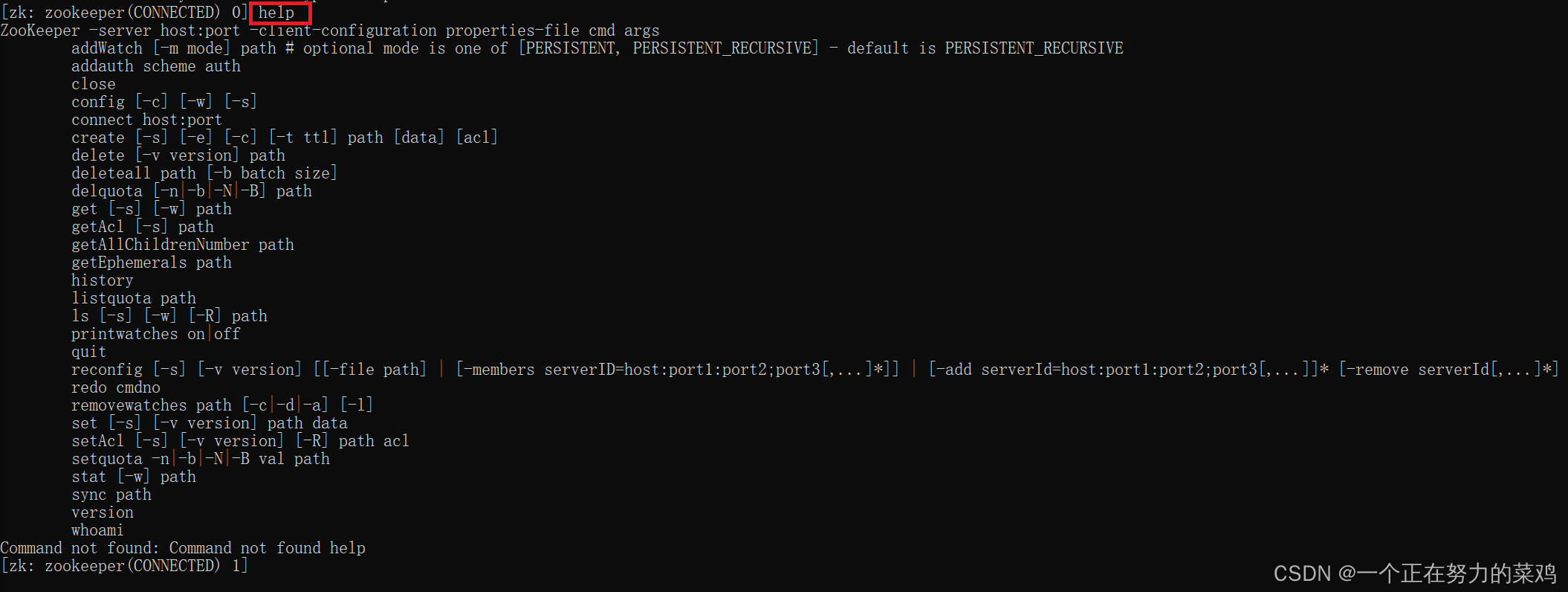
1.help
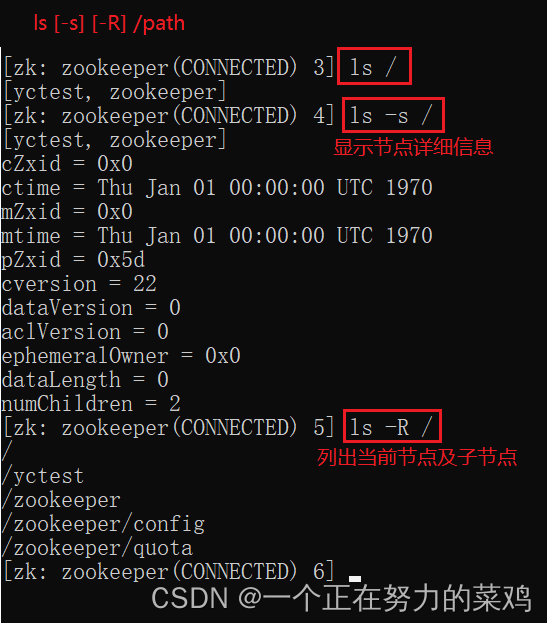
2.ls
3.get
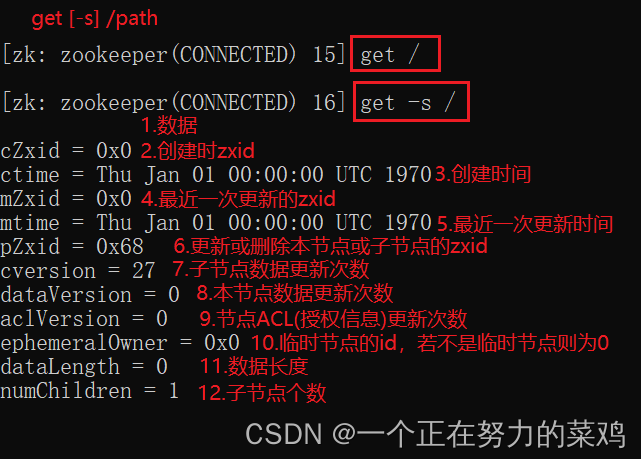
4.create
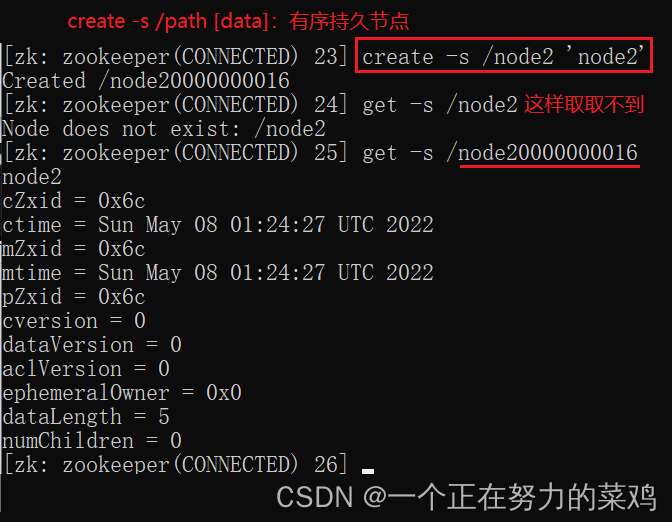
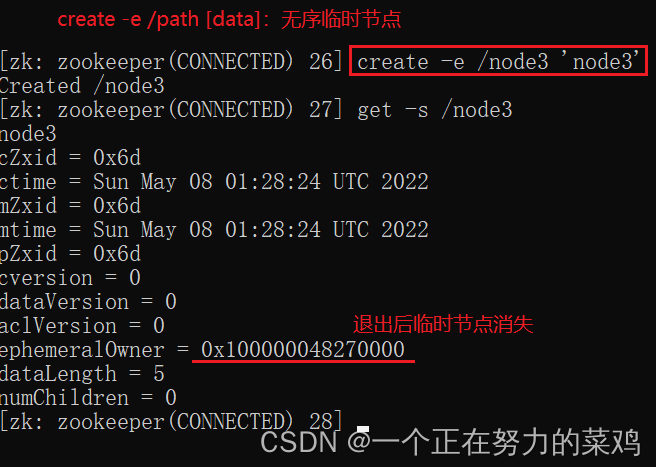
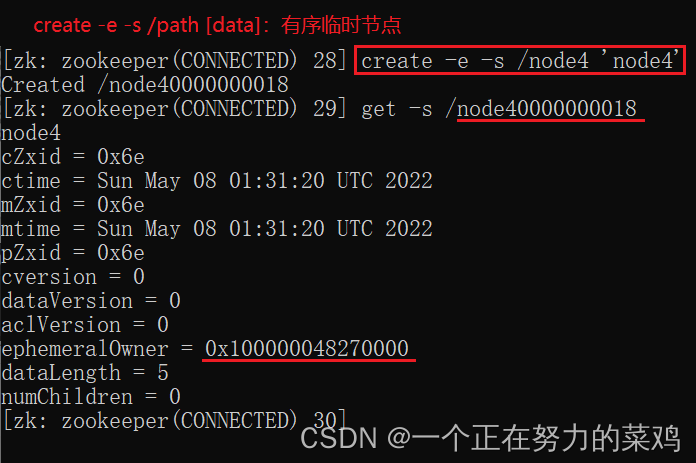
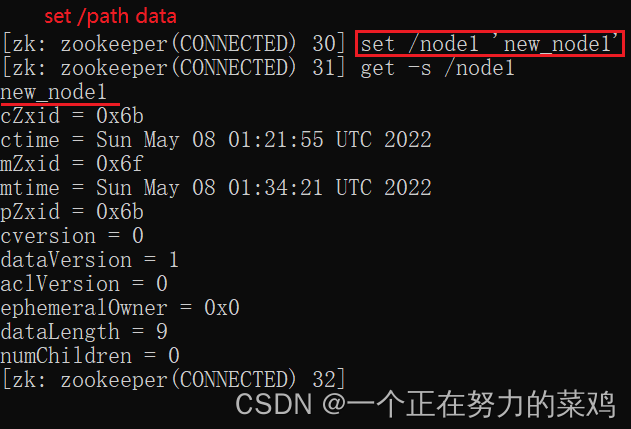
5.set
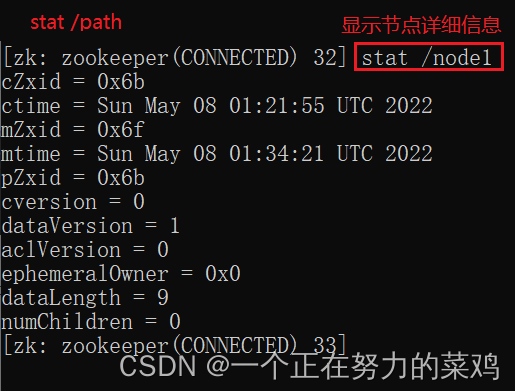
6.stat
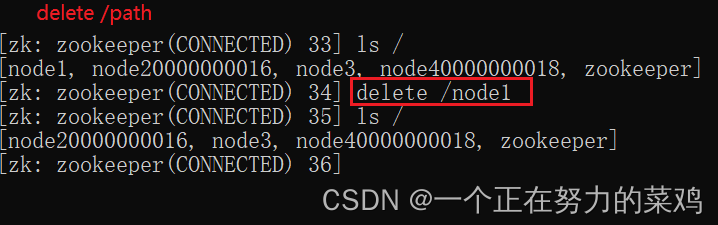
7.delete
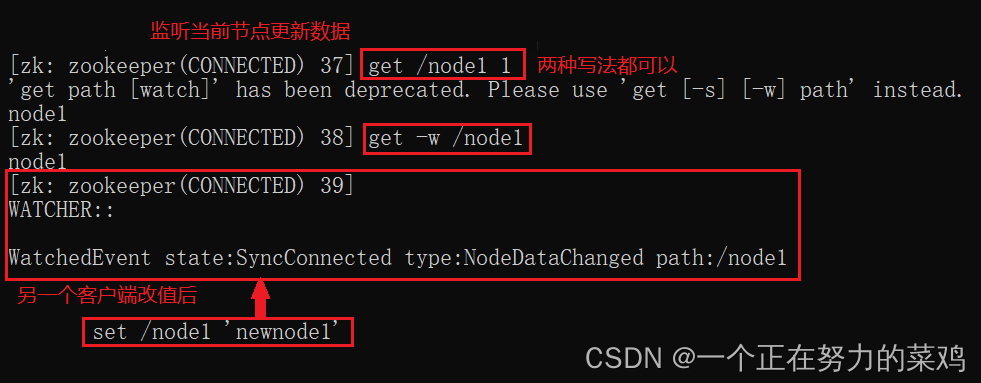
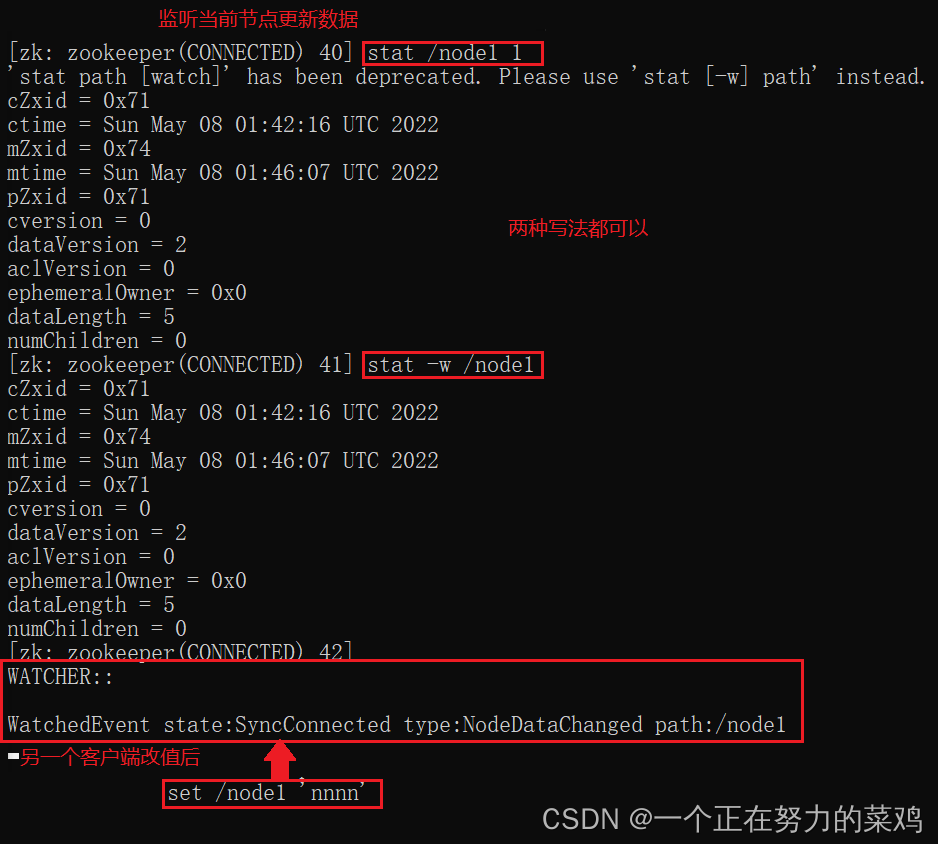
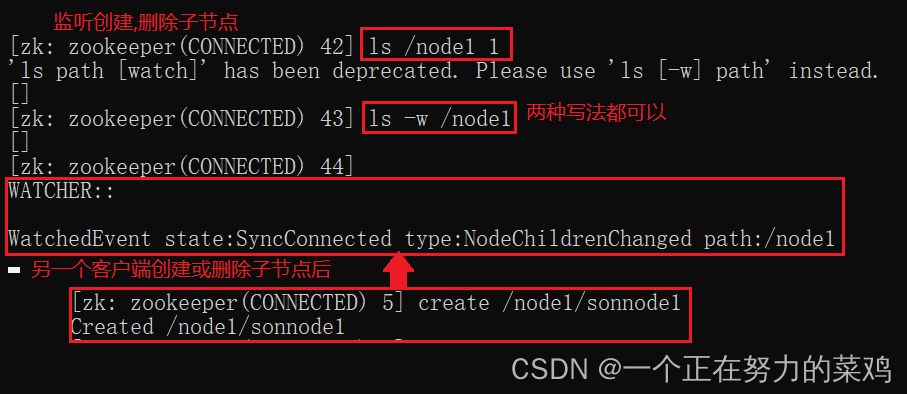
8.watch监听
- 事件只绑定一次
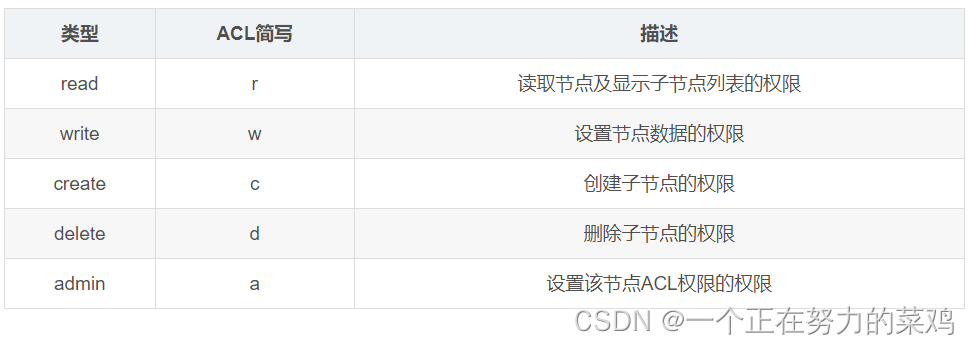
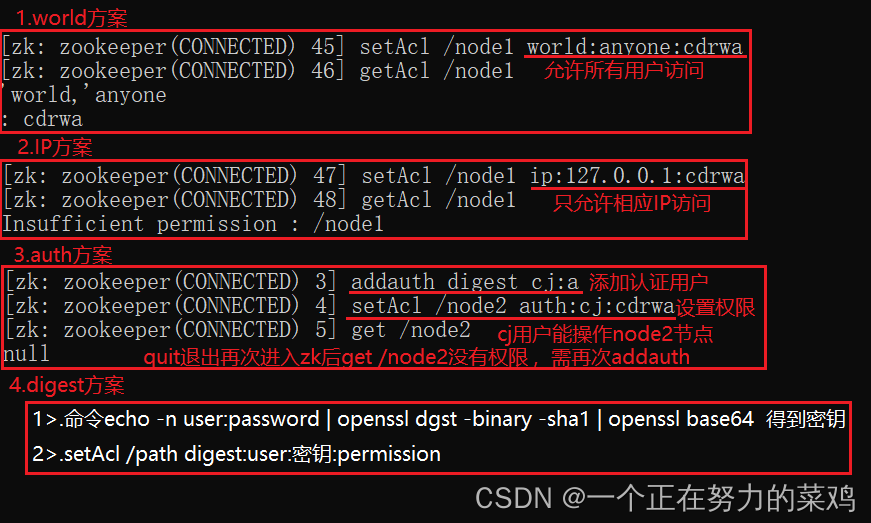
9.ACL
- 特性
1.ACL争对每个znode,父子节点的权限设置无关
2.每个znode可设置多种权限控制方案和多个权限
3.ACL主要包含三个方面:schema(权限模式):id(授权对象):permission(权限)
- schema:id

- permission
- 使用权限命令

- 不同权限方案
10.sync
- 读取数据前sync,保证在zk中读取的数据与最新数据一致














 6436
6436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









