






本文将详细介绍并实践以下内容:
- LangChain 各组件(LLM、工具、链、记忆、Agent、提示、RAG、Retriever 等)在完整项目中的协作关系
- 结合 DeepSeek + bge-small-zh + FAISS + DuckDuckGoSearch
- 提供模块化代码示例,说明每部分的职责与灵活性
- 使用 FastAPI 将 Agent 封装成 API 服务,可用于 Web 前端接入
- 查漏补缺前几篇中未展开的主题,例如 Tool 封装规范、Agent 执行中间状态管理、复杂提示结构设计等
本系列文章最后一篇将系统讲解如何基于 LangChain 框架构建一个功能齐全、可部署的智能问答 Agent。我们将结合前文核心概念(ReAct 架构、RAG 检索增强、提示工程、工具调用等)逐步展开,选用 DeepSeek 聊天模型作为 LLM、BAAI/bge-small-zh-v1.5 作为中文嵌入模型、FAISS 作为向量数据库、DuckDuckGoSearchRun 作为联网搜索工具,最终封装成 RESTful 服务。
一、LangChain框架概述
- 什么是LangChain?
LangChain是一个用于开发由语言模型驱动的应用程序的框架。它允许开发者将大型语言模型(LLMs)与其他计算或知识源连接起来,从而创建更强大、更灵活的AI应用。
- LangChain核心组件
LangChain包含多个核心模块,这些模块可以组合使用来构建复杂的AI Agent:
- Models:支持多种语言模型接口
- Prompts:提示管理、优化和序列化
- Memory:短期和长期记忆管理
- Indexes:文档加载、处理和检索
- Chains:调用序列和组合
- Agents:动态决策和工具使用
- Callbacks:日志和流式传输
二、核心概念回顾
-
ReAct 框架:是一种将推理(Reasoning)与动作(Action)相结合的交互式提示方式。LangChain 的 ReAct Agent 可以让模型在对话过程中思考 (
Thought:)、采取动作 (Action:) 并观察结果 (Observation:),从而动态调用外部工具。例如,当模型面临复杂问题时,可以通过调用搜索工具或数据库工具来获取补充信息,再结合生成能力给出答案。 -
RAG(检索增强生成):指在生成回答时通过检索相关文档来提供上下文或证据的技术。RAG 适用于将领域知识融入对话,避免模型只凭「记忆」回答超出能力的问题。我们会使用向量数据库(FAISS)和文本嵌入来实现 RAG,从海量文档中检索与用户问题最相关的内容,再输入模型生成答案。
-
提示工程:通过
PromptTemplate等机制设计和组织模型提示,将任务指令、示例和变量拼接成最终输入。好的提示可以大幅提升模型理解和回答能力。我们将定制提示模板,明确说明用户意图及可用工具等,引导模型在 ReAct 交互中正确使用工具。 -
工具调用:Agent 能访问的工具(如搜索引擎、知识库查询、计算器等)需封装为符合接口的
Tool对象,包含名称、调用函数和用途说明。在 ReAct 策略下,模型可以选择某个工具并按指定格式传入参数。本文示例中,将集成联网搜索与本地向量检索两种工具供 Agent 使用。 -
多轮对话与记忆:使用
ConversationBufferMemory记录会话历史,实现上下文连续性。当用户提问时,上下文记忆会作为提示变量注入,让模型参考前文对话内容,使回答更具连贯性。
三、系统架构与组件选型
3.1 语言模型与嵌入
- LLM(聊天模型):选用 DeepSeek 提供的 deepseek-chat 模型作为对话模型。DeepSeek 是一系列开源模型,支持结构化输入、工具调用等能力。DeepSeek API 使用与 OpenAI 兼容的 API 格式,可使用 LangChain 的
ChatOpenAI进行接入,如下所示:
import os
from langchain_community.chat_models import ChatOpenAI
API_KEY = os.getenv('DEEPSEEK_API_KEY')
llm = ChatOpenAI(
model='deepseek-chat', # 指定使用的模型名称,如 gpt-4、deepseek-chat 等
openai_api_key=API_KEY, # 设置 API 密钥
openai_api_base='https://api.deepseek.com/v1', # 自定义模型地址(如 DeepSeek)
temperature=0.7, # 控制输出的随机性,越低越保守,越高越发散
max_tokens=1024, # 设置生成回复的最大 token 数
model_kwargs={ # 额外的模型参数(可选)
"top_p": 1,
"frequency_penalty": 0.0,
"presence_penalty": 0.0
},
request_timeout=60, # 请求超时时间(秒)
streaming=False, # 是否使用流式响应
verbose=False # 是否打印调试信息
)
✅ 参数使用建议
- 温度设置:
temperature=0.0适合问答、摘要、代码生成等确定性任务;temperature=0.7~1.0更适合生成富有创意的内容。
- 兼容模型:
- 若使用 DeepSeek、Moonshot、Azure OpenAI 等非官方 API,务必设置
openai_api_base。
- 若使用 DeepSeek、Moonshot、Azure OpenAI 等非官方 API,务必设置
- 高阶用法:
- 可结合
LLMChain或AgentExecutor构建复杂流程。
- 可结合
这样实例化后,llm.invoke([消息列表]) 即可获得模型回复。
response = llm.invoke("请简要说明“量子计算”和“经典计算”的主要区别。")
print(response)
输出:
content='量子计算与经典计算的核心区别主要体现在以下方面:\n\n### 1. **信息表示方式**\n- **经典计算**:使用二进制位(bit),每个bit只能是0或1。\n- **量子计算**:使用量子位(qubit),可处于0、1或两者的叠加态(量子叠加),同时表示多种状态。\n\n### 2. **并行计算能力**\n- **经典计算**:逐次处理任务,N位处理器一次处理一个N位状态。\n- **量子计算**:N个qubit可同时处理2^N个状态(量子并行性),适合大规模并行问题(如因数分解、搜索)。\n\n### 3. **操作原理**\n- **经典计算**:基于布尔逻辑门(AND/OR/NOT等),确定性操作。\n- **量子计算**:通过量子门操作(如Hadamard门、CNOT门),支持叠加态和纠缠态的操作,具有概率性。\n\n### 4. **纠缠与关联性**\n- **经典计算**:比特间独立或通过经典关联。\n- **量子计算**:qubit可纠缠(entanglement),一个qubit状态变化立即影响另一个,即使相距遥远(非局域性)。\n\n### 5. **算法效率**\n- **经典计算**:解决常规问题(如排序、数据库查询)效率高。\n- **量子计算**:特定问题指数级加速,如Shor算法(因数分解)、Grover算法(无序搜索)。\n\n### 6. **错误处理**\n- **经典计算**:通过冗余校验(如重复编码)纠错。\n- **量子计算**:需量子纠错码(如表面码),因量子态脆弱易受退相干影响。\n\n### 7. **物理实现**\n- **经典计算**:基于硅基半导体(CPU/GPU),技术成熟。\n- **量子计算**:需极端环境(超导、离子阱、光量子等),维持量子态难度大。\n\n### 8. **应用领域**\n- **经典计算**:通用计算,覆盖日常需求。\n- **量子计算**:专长于优化、模拟量子系统、密码学等,无法完全替代经典计算。\n\n### 总结\n量子计算利用量子力学特性(叠加、纠缠)突破经典限制,但在通用性和稳定性上仍面临挑战。两者未来可能互补共存,量子处理特定任务,经典负责其余部分。' additional_kwargs={} response_metadata={'token_usage': {'completion_tokens': 499, 'prompt_tokens': 18, 'total_tokens': 517, 'prompt_tokens_details': {'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 18}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'finish_reason': 'stop', 'logprobs': None} id='run--95a492b6-37f7-4e73-b5cf-12265c945c46-0'
3.2 文档加载与预处理
在构建 Agent 之前,我们需要先将原始文档转化为可以检索的向量形式,具体包括:
(1)加载本地文档
LangChain 提供多种 Loader 来读取不同格式的文档。
- 读取 Markdown 文件(
.md):
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./docs/智能体简介.md', encoding='utf-8')
documents = loader.load()

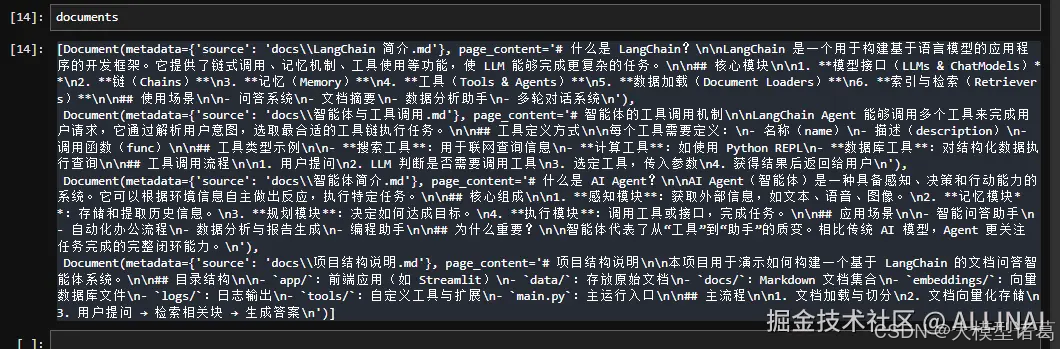
- 读取整个目录下的 Markdown 文件:
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader('./docs', glob='**/*.md', loader_cls=TextLoader, loader_kwargs={'encoding': 'utf-8'})
documents = loader.load()
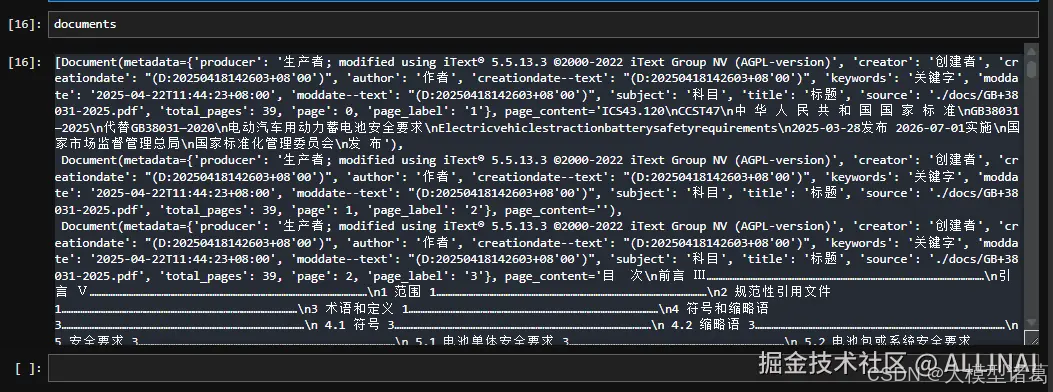
- 读取 PDF 文件:
对于 PDF 文件,可以使用 PyPDFLoader 进行加载。它会按页读取并自动转为 Document 对象。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader('./docs/GB+38031-2025.pdf')
documents = loader.load()
如果你希望将多个来源的文档合并处理,只需拼接多个 documents 列表即可:
all_documents = md_documents + pdf_documents + other_documents
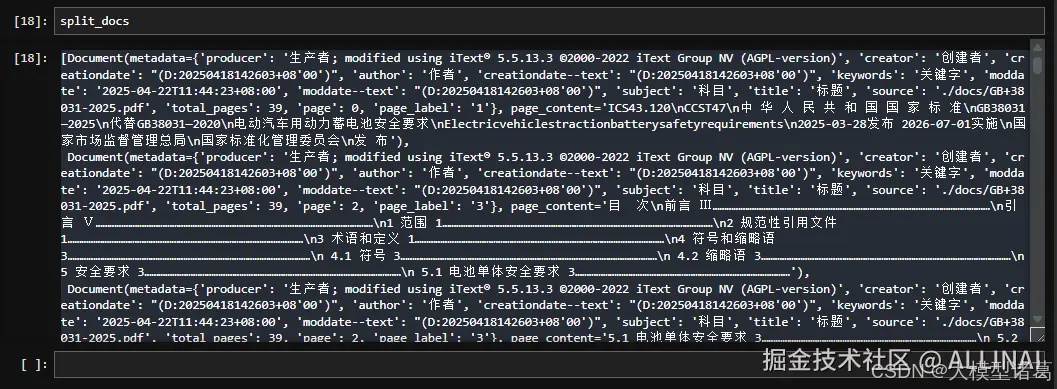
(2)文档切分
为了让长文档适配向量数据库,我们需要按段落或语义块进行切分。推荐使用 RecursiveCharacterTextSplitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ".", "!", "?"]
)
split_docs = text_splitter.split_documents(documents)
此操作会将文档拆成多个短文本块,既保留上下文连续性,又便于后续的向量化处理。
3.3 向量化与嵌入模型选型
我们选用了性能与体积兼顾的中文向量模型 —— BAAI/bge-small-zh-v1.5。它支持短语级语义检索,能生成可用于相似度计算的高质量文本向量。
from langchain_community.embeddings import HuggingFaceEmbeddings
# 初始化一个中文 BGE 嵌入模型,用于将文本转换为向量表示
embed_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5", # 使用 BAAI 提供的 bge-small-zh 中文语义嵌入模型
model_kwargs={"device": "cpu"}, # 指定运行设备为 CPU,如有 GPU 可改为 "cuda"
encode_kwargs={"normalize_embeddings": True} # 对输出的向量进行归一化,有助于相似度计算
)
- 嵌入模型(Embedding Model) 的核心功能是将自然语言文本转换为数值向量(embedding),使得我们可以基于向量做相似度检索、聚类、语义匹配等操作。在 LangChain 中,embedding model 通常用于以下两个场景:
- 文档入库(embedding + 存入向量数据库)
- 用户查询转换(embedding + 相似文档检索)
- BGE 模型推荐在
embed_query()之前添加查询指令(query_instruction),以获得更好的效果。
query_instruction = "为这个句子生成表示以用于检索相关文章:"
question = "人工智能是一门研究如何让计算机具有人类智能的科学"
query = query_instruction + question
vector = embed_model.embed_query(query) # 得到向量表示(用于查询)
print(vector)
输出:
- 向量数据库:使用 FAISS 存储文档向量。FAISS 是 Facebook 提供的高效相似度检索库,专门用于密集向量搜索。将待检索的文档列表通过
embed_model编码后,使用FAISS.from_documents()构建向量索引。例如:
1. 将前面切分后的 split_docs 向量化,并存入 FAISS
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(split_docs, embed_model)
# 保存本地索引以供后续检索调用
vectorstore.save_local("faiss_index")

这样即可快速从 FAISS 中根据用户查询检索相关文档。
2. 检索器构造(Retriever)
我们通过 vectorstore.as_retriever() 构造一个语义检索器,支持基于向量相似度的文段召回:
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 4})
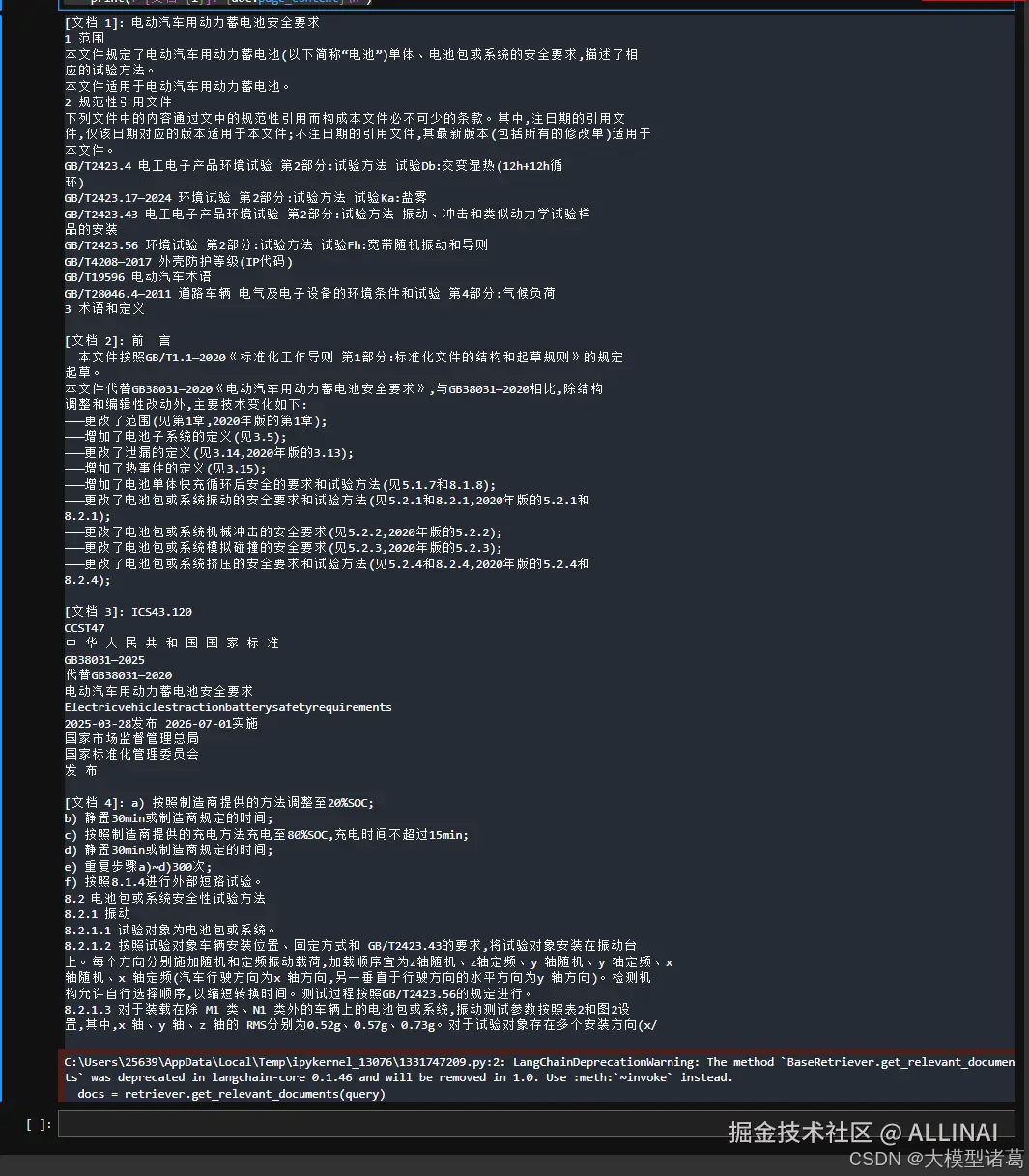
query = "电动汽车用动力蓄电池按照8.2.1进行振动试验后应达到什么要求?"
docs = retriever.get_relevant_documents(query)
for i, doc in enumerate(docs, 1):
print(f"[文档 {i}]: {doc.page_content}\n")
retriever是 LangChain 中统一的文档检索接口,而vectorstore.as_retriever()是把底层的向量数据库变成这个接口。search_type:检索方式,默认是 "similarity"(相似度检索),还可以是 "mmr"(最大边际相关性)等。search_kwargs:检索参数,比如 k=3 表示返回前 3 条相似结果。也可以传入filter等用于更精细控制的参数。
输出:
3.4 联网搜索工具
使用 DuckDuckGo 搜索工具进行实时查询。LangChain 社区提供了 DuckDuckGoSearchRun 封装,可直接调用 DuckDuckGo API。示例:
from langchain_community.tools import DuckDuckGoSearchRun
search_tool = DuckDuckGoSearchRun()
result = search_tool.invoke("最近一次 SpaceX 火箭发射是什么时候?成功了吗?")

这个工具方便集成到 Agent 中,实现“需要联网搜索”时的补充信息。
3.5 工具系统设计
所有工具统一封装为 Tool 对象,包含名称、执行函数和描述。例如,我们可以准备两个工具:网络搜索 和 向量检索。
from langchain.agents import Tool
tools = [
Tool(
name="Search",
func=lambda q: DuckDuckGoSearchRun().invoke(q),
description="在互联网上搜索答案"
),
Tool(
name="Lookup",
func=lambda q: "\n".join([doc.page_content for doc in retriever.get_relevant_documents(q)]),
description="从本地向量数据库中检索相关文档"
),
# 可扩展其他工具
]
这样 Agent 在对话过程中如果决定“搜索网页”就会调用第一个工具,如果需要“查看知识库”则调用第二个。
四、代码组织与协同方式
按照 LangChain 组件化设计,我们将主要功能模块划分为不同文件或类以便维护:
- Embedding 模块:负责加载
HuggingFaceBgeEmbeddings模型并构建 FAISS 数据库。示例代码如上,将用于后续检索。 - Tool 模块:定义各种工具。可以把搜索和检索函数封装在此,例如前述的
Search、Retrieve。 - Prompt 模板:使用
PromptTemplate定义 ReAct 提示格式,插入工具列表和对话历史等变量,例如:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"你是一个智能问答助手。你可以使用以下工具:\n{tools}\n"
"请根据用户问题和工具结果给出答案。\n\n"
"用户问题: {input}\n"
"{agent_scratchpad}"
)
- 记忆模块:通过
ConversationBufferMemory保存对话记录。初始化时指定memory_key="chat_history",并将该内存作为参数传入 AgentExecutor。 - Agent 构建:使用 LangChain 的 ReAct Agent 构造器创建可调用的 Agent:
这样得到的 agent_executor.invoke({"input": 用户问题}) 会返回模型对话输出,其中模型可以在生成过程中调用 Search 或 Lookup 等工具,并将返回结果纳入思考。
response = agent_executor.invoke({"input": "中国政府对电动汽车用动力蓄电池有什么新的要求?"})
print(response)
输出:
> Finished chain.
{'input': '中国政府对电动汽车用动力蓄电池有什么新的要求?', 'chat_history': '', 'output': '中国政府对电动汽车用动力蓄电池的新要求包括加强安全性能测试、推行生产者责任延伸制度、鼓励低碳生产、提高技术标准与性能要求,以及实施全生命周期溯源管理。'}
五、FastAPI 封装与示例
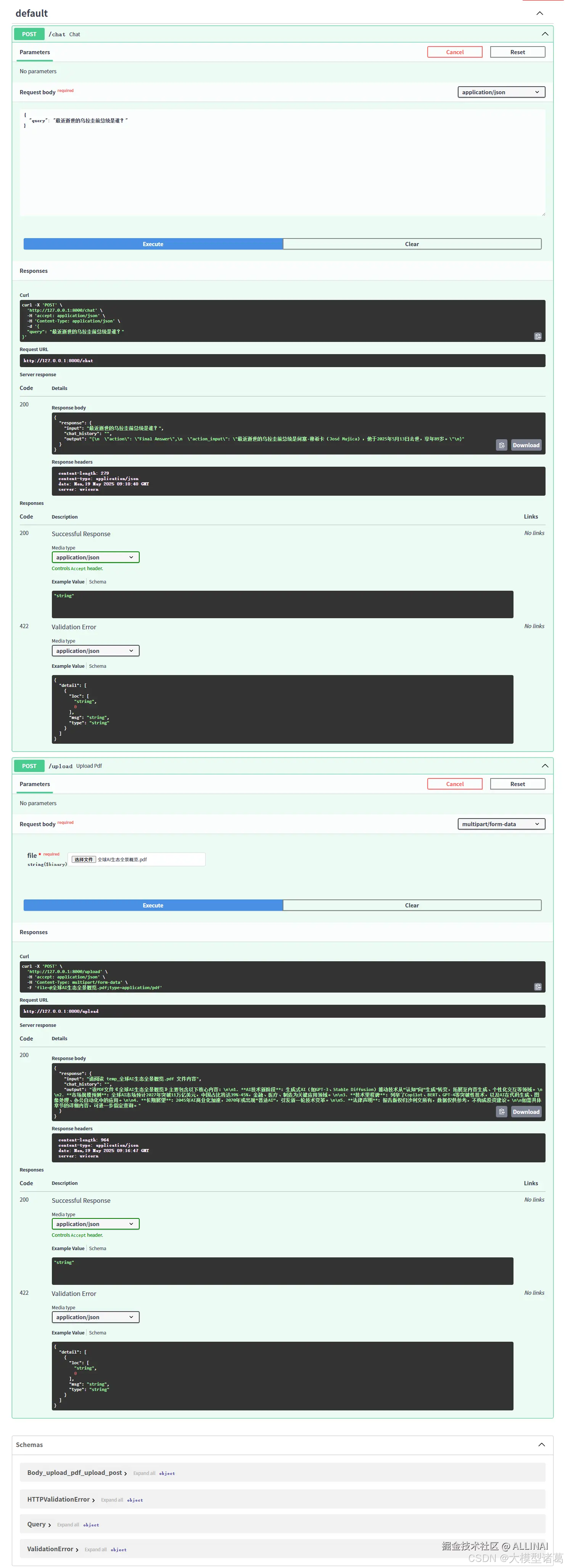
完成以上组件后,用 FastAPI 构建 API 服务接口:
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/chat")
async def chat_api(request: Request):
data = await request.json()
query = data.get("query", "")
# 调用 AgentExecutor 得到回答
result = agent_executor.invoke({"input": query})
answer = result["output"]
return {"answer": answer}
启动服务后,客户端即可通过 POST 请求访问,例如:
curl -X POST http://localhost:8000/chat -H "Content-Type: application/json" -d '{"query":"上海天气怎么样?"}'
上述请求返回的 JSON 会包含智能体的回答。整个服务基于组件化设计,后续可替换模型、增加工具或更换向量数据库,而不影响主逻辑。
六、推荐阅读与项目结构示例
- 推荐阅读:深入了解 LangChain 文档,如 ReAct Agent 和工具调用机制,探索 LangGraph 新架构;学习 DeepSeek 和 BGE 模型的官方资料。
- 项目目录及代码详情(以模块化方式组织代码):
ai_agent_demo/
├── agents/
│ └── base_agent.py # 构建智能体
├── tools/
│ ├── search_tool.py # 搜索工具(DuckDuckGo)
│ ├── doc_reader.py # 文档读取工具
│ └── vectorstore.py # 构建向量数据库
├── multimodal/
│ └── image_captioning.py # 图像识别/图文描述工具
├── memory/
│ └── memory.py # 智能体记忆模块(新增)
├── app/
│ └── main.py # FastAPI 接口入口
├── sample.pdf # 示例文档
├── sample.jpg # 示例图像
├── main.py # 命令行入口
└── requirements.txt # 依赖管理
命令行交互入口(main.py)
from agents.base_agent import build_agent
def run():
agent = build_agent()
print("🔧 智能体已启动... 输入 exit 退出")
while True:
user_input = input("\n🧑 用户: ")
if user_input.lower() in {"exit", "quit"}:
print("👋 再见!")
break
response = agent.invoke(user_input)
print(f"\n🤖 Agent: {response}")
if __name__ == "__main__":
run()
输出:

FastAPI 部署接口(app/main.py)
# -*- coding: utf-8 -*-
from fastapi import FastAPI, UploadFile, File
from pydantic import BaseModel
from agents.base_agent import build_agent
app = FastAPI()
agent = build_agent()
class Query(BaseModel):
query: str
@app.post("/chat")
async def chat(q: Query):
response = agent.invoke(q.query)
return {"response": response}
@app.post("/upload")
async def upload_pdf(file: UploadFile = File(...)):
content = await file.read()
path = f"temp_{file.filename}"
with open(path, "wb") as f:
f.write(content)
response = agent.invoke(f"请阅读 {path} 文件内容")
return {"response": response}
uvicorn app.main:app --reload
总结:本文展示了如何将 RAG、工具调用、多轮记忆等技术融合到一个 LangChain Agent 中,结合 DeepSeek 聊天模型和本地向量数据库,实现实用的问答系统。该架构具有良好可扩展性,可根据需求添加更多工具或采用更强大的模型,以满足复杂的应用场景。
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以在文末CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享

AI产品经理,0基础小白入门指南
作为一个零基础小白,如何做到真正的入局AI产品?
什么才叫真正的入局?
是否懂 AI、是否懂产品经理,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
你是否遇到这些问题:
1、传统产品经理
不懂Al无法对AI产品做出判断,和技术沟通丧失话语权
不了解 AI产品经理的工作流程、重点
2、互联网业务负责人/运营
对AI焦虑,又不知道怎么落地到业务中想做定制化AI产品并落地创收缺乏实战指导
3、大学生/小白
就业难,不懂技术不知如何从事AI产品经理想要进入AI赛道,缺乏职业发展规划,感觉遥不可及
为了帮助开发者打破壁垒,快速了解AI产品经理核心技术原理,学习相关AI产品经理,及大模型技术。从原理出发真正入局AI产品经理。
这里整理了一些AI产品经理学习资料包给大家
📖AI产品经理经典面试八股文
📖大模型RAG经验面试题
📖大模型LLMS面试宝典
📖大模型典型示范应用案例集99个
📖AI产品经理入门书籍
📖生成式AI商业落地白皮书
🔥作为AI产品经理,不仅要懂行业发展方向,也要懂AI技术,可以帮助大家:
✅深入了解大语言模型商业应用,快速掌握AI产品技能
✅掌握AI算法原理与未来趋势,提升多模态AI领域工作能力
✅实战案例与技巧分享,避免产品开发弯路
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
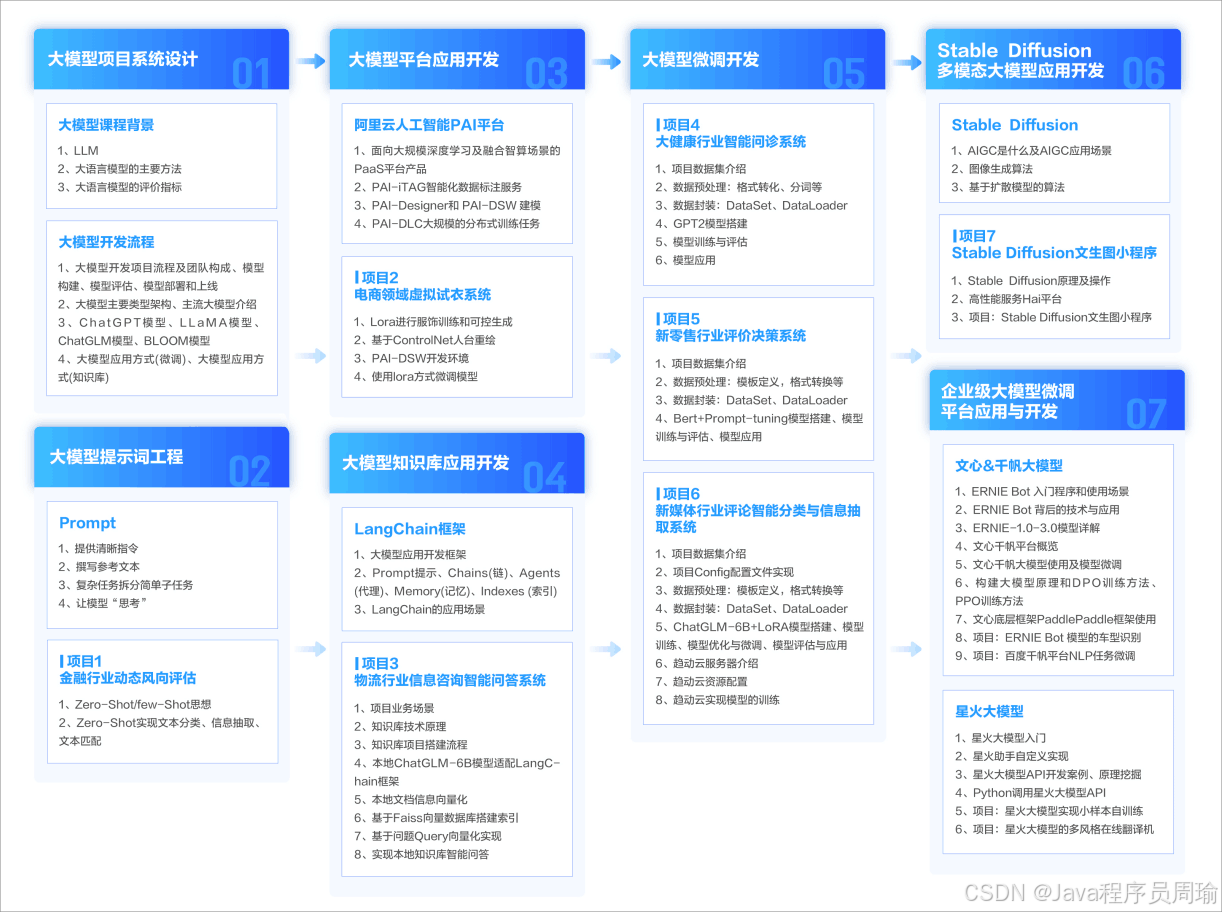
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享免费领取【保证100%免费】🆓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









