






Abstract
移动边缘计算:5G生态关键组成部分,将服务器部署在靠近最终用户的地方,类比章鱼——大脑+触手。
延迟:5G与MEC不协调,产生长响应延迟。
Tutti:将5G RAN与MEC耦合(couple)在用户空间,确保延迟关键视频分析(latency-critical video)的性能。Tutti通过融合5G RAN的瞬时无线动态和边缘服务器的应用层内容变化,做到了精确定制应用服务需求。然后,Tutti通过5G RAN与边缘服务器间的实时交互,为应用程序强制提供资源。
结果:响应延迟降低了61.69%,交互成本可忽略。
1. Introduction
5G的兴起带来了很多产业的变化,同时带来了大量的带宽和计算资源需求,也产生了低延迟的需求。
Tutti将5G RAN和MEC耦合在一起,满足延迟敏感型应用的需求。核心思想是,将边缘服务器的应用层信息与5G RAN的物理链路动态相结合,再以此为基础定制每一帧的需求。例如,当边缘服务器发现某一帧已经要接近ddl,服务器会督促基站(BS,Base Station)优先分配资源。5G运营商也在采用网络切片(network slicing)划分专用的资源。Tutti就定位在网络切片中。
Tutti的two unique challenges:
-
如何准确理解应用的需求?
困难之处:一方面,视频分析的应用层内容会不断变化;另一方面。无线信道在帧传输的过程中是时变的,难以预测的。如果不能解决这两方面的问题,将导致:过度分配降低资源利用率和低估用量影响服务质量(QoE)两个相反的问题。而Tutti可以感知到丰富的跨层信息,这样就引出了一种定制应用需求的预测方法。即,Tutti采用上下文感知回归学习算法来预测应用层内容的变化,使用概率似然模型来估计无线动态;随后Tutti将这两种算法融合成一个精确的应用需求规则。 -
如何可靠地执行对截止日期敏感的资源供应?
Tutti学习到应用程序的需求,其可靠执行将依赖于RAN的物理/介质访问控制层资源分配。一种简介的 方式是,基站强制提前预留足够的资源,当用户设备(UE)请求时分配下去。但是这种方式需要对蜂窝标准栈(the cellular standard stack)和基础设施进行重构,会产生高昂的成本。
于是,文章提出了一种对期限敏感的资源分配方法(Deadline-Sensitive),促进边缘服务器与5G RAN之间的轻量级交互,保证资源的及时授予,根据奖励和加速机制灵活确定资源分配的优先级。Tutti存在激励机制,鼓励在时间充足时提供资源,如果ddl将近,则确立新的优先级,加速提供。
PRB(Physical Resource Block,物理资源块)Tutti预测间隔为Microscope的五分之一,资源供应效率接近于Oracle上界,只有一个供应回合差距。存在部分可忽略的开销。
贡献:Tutti是第一个用户空间LTE/5G RAN和MEC耦合框架,并在real world进行部署与评估。现场测量研究揭示了现有5G MEC中松散耦合导致的低用户体验质量;设计了Tutti—>轻量级、标准兼容—>预测应用需求并保证资源供应;在虚拟的蜂窝MEC平台上对Tutti进行原型设计。
2. Motivation(动机)
5G User -> shoots -> 5G BS -> Edge Servers -> infer objects -> 5G BS -> User
帧响应延迟(frame response latency)和每个快照的感知精度是视频分析的关键QoE指标。
2.1. Measurement Methodology
5G RAN与边缘服务。在5G MEC系统中,边缘服务器集群通常部署在5G RAN的背面,涉及大量分布式基站。实验的设备:5G RAN:sub-6 GHz(3.5 GHz频率,NSA架构下的100 MHz频段);边缘服务器:V100 32GB、Intel I9、8 cores。
表1,
延迟关键视频分析。分两类,一类对延迟敏感,具有即时改变的特性,如目标检测、目标追踪和实例分割等;另一类对延迟并不具有高敏感性,如环境检测、车牌、人脸识别、物体计数等。文章关注第一类。
即时性,有两种实现方法:
(1)设备全部放在一个“box”里,比如把摄像机等模块都放在汽车里,固然延迟较短,但消耗成本;
(2)Figure 1中边缘辅助卸载模式。
选用评估任务:OD(YOLO),OT(SiamFC),IS(Mask R-CNN)
终端和测量工具。终端:5G 安卓手机,在手机上部署帧捕捉/解码/流媒体程序。过程:终端在城市行驶的汽车上(30-110km/h),同时以每秒30帧的速度上传开源图像集到边缘服务器,并获得反馈输出;监测蜂窝行为:使用相关软件,同时编写脚本在服务器上记录QoE指标。
2.2. QoE of Latency-critical Video Analytics
帧响应延迟极长。Table 2,所有任务都不能满足响应延迟容忍度(200ms)。最快的OT,有44.11%的帧在200ms内到达,10.67%的情况超过400ms。响应延迟包括网络传输和计算推理,前者占据支配地位,而且传输时上行链路延迟更大。
感知准确度低。用mAP(发送帧的ground truth和推理结果)进行度量。Table 2中可以看出,相比于“all-in-box”,三个任务的感知准确率显著下降。证明5G MEC不能满足视频分析的QoE需求。
2.3. An In-depth Investigation of Poor QoE
发现1:性能差与5G RAN中的无线资源紧缺无关。吞吐量完全可被上行链路容量容纳。
直接原因:帧传输过程中无线资源低下的传输效率。
Figure2(a):
①UE向BS发送测量报告,监测无线信道质量。
当新的数据包到达UE的缓冲区时,在②中触发SR/BSR(缓冲状态报告)消息,发送给BS。
在③-⑨结束后,返回一个上行链路(UL)Grant信息,包括PRB配置;最后,UE缓冲区的数据被填充到PRB中,并且上传到BS。如果UE一次传输失败,将重新发送BSR消息。
我们将数据包到达、UL授权、数据传输和重传之间的时间分别定义为
T
w
a
i
t
T_{wait}
Twait、
T
t
r
a
n
s
T_{trans}
Ttrans和
T
r
e
−
t
r
a
n
s
T_{re-trans}
Tre−trans
n代帧的上传延迟表示为:
T
n
=
∑
r
=
1
R
(
T
w
a
i
t
r
+
T
t
r
a
n
s
r
+
T
r
e
−
t
r
a
n
s
r
)
,
1
⩽
r
⩽
R
T_{n}=\sum^{R}_{r=1}(T^r_{wait}+T^r_{trans}+T^r_{re-trans}),1\leqslant{r}\leqslant{R}
Tn=r=1∑R(Twaitr+Ttransr+Tre−transr),1⩽r⩽R
r 是资源请求-授权轮次的标识符。
这种机制的不足:
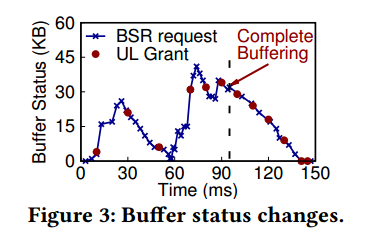
- 上行链路资源授权延迟与不足。如Figure 3所示,共50个BSR请求(X),只有12个(●)被基站成功批准;即使UE获得了UL授权,分配的资源也不足以立即清除缓冲区数据;图中93ms定为缓冲完成,即所有数据包进入缓冲区,但有6个请求,不在93ms内,即有36.11%的帧响应延迟浪费在了缓冲区清空阶段。
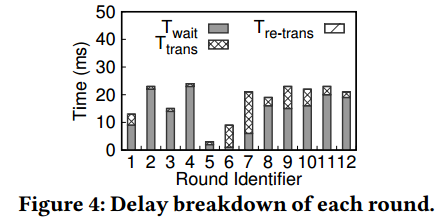
多轮交互时资源等待延迟长。Figure 4显示,①大部分延迟用于等待UL Grant。② T w a i t T_{wait} Twait在多数情况下占据主导地位。
根本原因:5G RAN与MEC彼此透明。
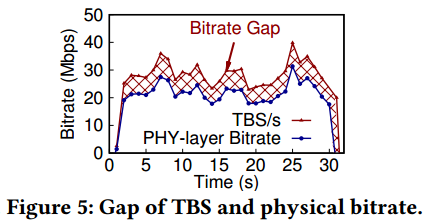
- RAN不知道视频分析的延迟关键需求,只能根据用户设备缓冲区的状态和瞬时链路的容量进行非精确的预测和服务。在文章的研究中,调度器优先满足有较大无线资源请求的用户,而忽略请求量较小的,Figure 5验证了这一点:TBS(传输块大小)与物理层比特率之间存在明显的、不正常的缺口。这种调度策略无法满足对延迟要求很高的用户的需求,这会导致这类用户继续向BS发送额外的BSR messages,直到最后得到满足。
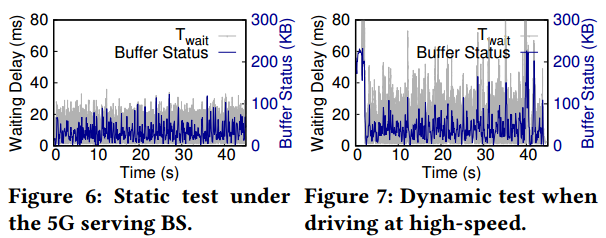
- 视频分析后端,也就是边缘服务器端,由于缺乏与5G RAN之间的交互支持,无法适应随时间变化的频道动态。Fig 6和Fig 7是文章中进行的两个对比实验,分别在静态(停车)和动态(开车)场景下,对waiting delay和UE缓冲区状态进行跟踪。可以看出,动态下是静态下的1.73倍。
二者间的透明度降低了资源分配效率,延长了延迟。将5G RAN和MEC耦合起来,使双方知道彼此的真实需求或状态变化,保证延迟敏感的应用的QoE。
3. SYSTEM OVERVIEW(系统概述)
Tutti,5G RAN与MEC耦合的框架。Figure 8是Tutti的系统概览,基本流程是,UE向服务基站不断请求资源,然后获得分配的资源,最后将其数据包传递给边缘服务器进行计算。KEY:确保UE及时获得所需的资源。
与前文提到的多轮资源“请求-授权”机制相比,Tutti选用了一种不同的方法,即以轻量级用户空间后台程序的形式在边缘服务器上来保证无线资源的及时提供。
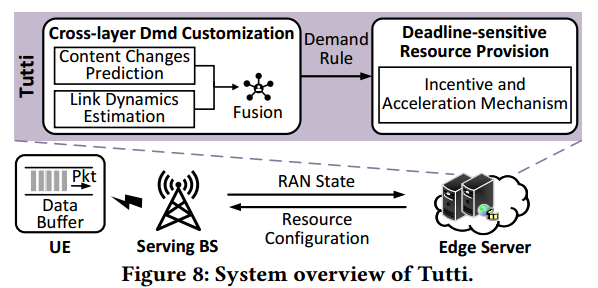
Tutti将RAN状态和应用层上下文信息(从边缘服务器获得)作为系统输入,并通过两个主要模块输出资源配置来引导基站的PRB授权。
模块Ⅰ:A cross-layer QoE demand (Dmd.)。跨层QoE需求定制方法,用于了解下一帧交付需要多少资源,具体地,通过回归学习预测应用层内容的变化,使用统计似然模型估计时变链路动态。然后,Tutti将中间结果融合到需求规则中,该规则校准所需资源的数量。
模块Ⅱ:用于动态优先发放资源的激励与加速机制,可以确保在ddl之前发放资源。e.g.,如果时间未到ddl,Tutti将会分配优先级较低的资源,否则会紧急加速资源调度与分配。为了实现这个,Tutti在资源配置消息中嵌入了授权优先指示符,同时及时与基站进行交互进行资源分配与调整。
Tutti的耦合设计带来的好处。
Ⅰ:通过了解应用层内容和物理连接的实时变化来提高视频分析的QoE,促进了RAN与边缘服务器间的交互。这样,Tutti“欺骗”了MAC层调度器,提前寻找资源容量,进行分配。
Ⅱ:Tutti位于边缘服务器端,未对网络基础设施和UE进行大量修改,是轻量级的。为5G MEC的部署提供新的视角。
4. CROSS-LAYER DEMAND CUSTOMIZATION(跨层需求设计)
准确理解视频分析的QoE需求存在两个重要的关联因素:
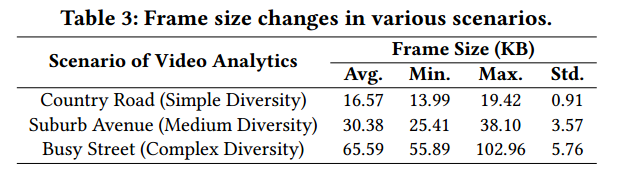
- 应用层内容在多样的场景中随机变化。Table 3显示了在不同场景下测量的帧大小。繁忙街道场景下平均大小更高,标准差也显示在复杂场景下差异更高。
- 由于信号波动、衰减损耗和用户移动,无线信道是时变的。随频带的增加,5G比LTE存在更大的波动性。
而这两个因素是互相作用的。
Tutti通过跨层信息融合的方式应对这些因素。
Ⅰ:Tutti位于边缘服务器,可以轻松获得应用层的上下文信息,包括从用户设备发送的帧和模型推断的信息,如检测框和跟踪轨迹等。
Ⅱ:在MEC(Multi-Access Edge Computing,多接入边缘计算)标准中引入了新功能,RNIS,无线网络信息服务,可以解码物理层和网络层链接,向上层服务公开微观尺度的RAN状态。而这种详细的跨层信息反映了应用内容和无线信道的实时变化,可以帮助Tutti了解ms级粒度应用的QoE需求。
过程:
- Tutti将应用层上下文输入到内容变化预测模块中,获取下一帧的大小。
- 链路动态估计模块使用细粒度RAN状态来预测实时链路质量。
- Tutti将它们融合到需求规则中,确定下一帧传输所需的资源数量。
4.1. Context-aware Content Changes Prediction(基于上下文的内容变化预测)
场景多样性主要受到三个因素的影响,即背景复杂性、对象元素的数量和对象的运动状态。文章中使用上下文信息通过回归算法来理解这三个因素。
Ⅰ:帧序列化。UE帧是串行上传,可以帮助Tutti理解背景复杂性的变化。
Ⅱ:对象元素的数量和运动状态可以从推断的语义信息中检测出来。
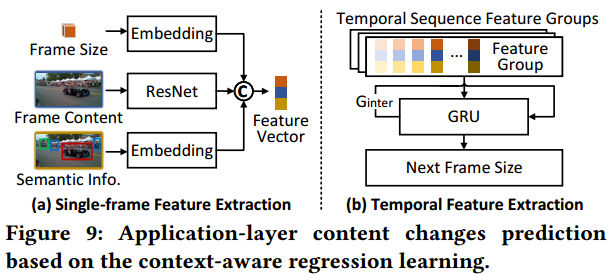
Fig 9展示了算法的两个阶段。
- 单帧特征提取。输入第 i i i帧的帧大小、帧内容和语义信息到相应的特征提取器,然后输出特征向量。公式为:
其中,⊕是串联运算,是浮点数,是三维矩阵(224,224,3),包括检测框和移动状态;和嵌入层,用来量化帧大小和对象数量/运动状态的潜在序列特征。
Tutti也使用ResNet-50来获取帧本身的特征。
- 时间特征提取阶段。
使用GRU(门控循环单元),输入时间序列特征组来预测下一帧的大小。每个特征组将个(一般为20)历史序序列化帧的特征向量串联起来,该阶段的核心是基于GRU的特征提取器。将新特征组和过去特征组生成的旧中间结果结合,然后推断出下一个值,即 F n + 1 = G R U ( G n i n t e r , { V n − m + 1 , V n − m + 2 , . . . , V n } ) F_{n+1}=GRU(G^{inter}_{n},\{V_{n-m+1},V_{n-m+2},...,V_{n}\}) Fn+1=GRU(Gninter,{Vn−m+1,Vn−m+2,...,Vn})其中, G n i n t e r = G R U ( G n − 1 i n t e r , { V n − m , V n − m + 1 , . . . , V n − 1 } ) G_{n}^{inter}=GRU(G^{inter}_{n-1},\{V_{n-m},V_{n-m+1},...,V_{n-1}\}) Gninter=GRU(Gn−1inter,{Vn−m,Vn−m+1,...,Vn−1})
4.2 Real-time Estimation of Link Dynamics(链路动态的实时估计)
目前对链路动态的理解主要基于UE进行的channel测量。CLAW和PBE-CC,通过UE的解码通道来测量链路的带宽和拥塞窗口。但是这样存在粗粒度延迟,比如每80个时隙触发一次,最多40ms,同时信道波动也会有影响。
Tutti则选用了预测的方法,不需要等待报告。
MEC的RNIS功能可以记录SINR(信噪比)轨迹(ms),提供给Tutti用来学习。
SINR曲线的统计分布。 短期SINR轨迹服从截断高斯分布,可以用统计似然方法进行预测估计;同时也选择其他RAN状态信息来对似然参数进行校准。
![[Pasted image 20231024200104.png]]
Fig 10,200ms内SINR轨迹。遵循截断高斯分布,即
S
I
N
R
∼
N
(
μ
,
σ
2
,
a
,
b
)
SINR\sim\mathcal{N}(\mu,\sigma^2,a,b)
SINR∼N(μ,σ2,a,b)。
N
(
⋅
)
\mathcal{N}(\cdot)
N(⋅)是具有
(
a
,
b
)
(a,b)
(a,b)限制的高斯分布,剩下两个分别是均值和标准差。后进行了拟合,遵循截断高斯分布的高决定系数,进一步验证,随机选择了3条SINR,使用Fig 11的拟合线绘制CDF曲线,
R
2
R^2
R2系数都很高,但有波动,归结为UE和BS的相对位置变化。UE、BS之间的距离与SINR成反比。高速行驶时会导致其波动剧烈,快速收敛。
预测:截断高斯似然估计方法。似然模型表述为:
I
e
s
t
=
L
(
{
I
1
,
⋯
,
I
i
,
⋯
,
I
m
}
)
,
I^{est}=\mathcal{L}(\{I_{1},\cdots,I_{i},\cdots,I_{m}\}),
Iest=L({I1,⋯,Ii,⋯,Im}),
I
e
s
t
I^{est}
Iest是下一时刻的SINR,
I
i
I_{i}
Ii属于短期(200ms)历史轨迹,
L
(
⋅
)
\mathcal{L}(\cdot)
L(⋅)是似然函数。同时为了减小误差,文章设置了期望,给了上下界
∫
b
a
\int^a_{b}
∫ba
提高精度:主要在
(
a
,
b
)
(a,b)
(a,b)上做文章。最初设定为历史集合的上下界,但容易受到信道波动的影响。MEC的RNIS可以记忆SINR痕迹,参考这些数据对
a
,
b
a,b
a,b进行微调。
4.3 Generating Demand Rule(生成需求规则)
了解应用层和数据链路层变化与动态后,需将帧大小 F n + 1 F_{n+1} Fn+1和SINR I e s t I^{est} Iest融合到资源需求中 P R B n + 1 a l l PRB^{all}_{n+1} PRBn+1all。
需要解决的问题:
-
填补应用层数据与物理bit之间的差距。
应用层主要是帧大小,物理层则是PRB的配置,二者间存在容量缺口。
物理位容量:
F n + 1 P H Y = ∑ j = 1 J [ ( 1 − r j ) ⋅ k j ⋅ s j + ϵ ⋅ s j ] + o ( F n + 1 c t r l ) F^{PHY}_{n+1}=\sum^{J}_{j=1}[(1-r_{j})\cdot{k_{j}}{\cdot}{s_{j}+\epsilon\cdot{s_{j}}}]+o(F_{n+1}^{ctrl}) Fn+1PHY=∑j=1J[(1−rj)⋅kj⋅sj+ϵ⋅sj]+o(Fn+1ctrl)
r j r_{j} rj取值0或1, j j j代数据包成功到达取0,反之1; k j k_{j} kj表示 j j j代报文重传次数; ϵ \epsilon ϵ表示协议开销,取0.068; o ( ⋅ ) o(\cdot) o(⋅)是控制信令占的容量。存在理想情况,所有数据包都成功到达,无重传。 -
填充物理通道的开销与占用。
根据3GPP 5G NR规范(Rel-15 TS 38.306),量化 P R B n + 1 a l l PRB_{n+1}^{all} PRBn+1all为:
P R B n + 1 a l l = 5 ⋅ 1 0 4 1 − O H ⋅ F n + 1 P H Y M ( I e s t ) , PRB^{all}_{n+1}=\frac{5\cdot{10^4}}{1-OH}{\cdot}\frac{F_{n+1}^{PHY}}{M(I^{est})}, PRBn+1all=1−OH5⋅104⋅M(Iest)Fn+1PHY,
O H OH OH是物理信道开销, M ( ⋅ ) M(\cdot) M(⋅)起到信道调制功能,可通过 I e s t I^{est} Iest进行推导。
5 DDL-SENSITIVE RESOURCE PROVISION(DDL敏感的资源提供)
上文决定了请求规则,则Tutti接下来要保证在DDL之前执行。
方法1:预留资源块,收到请求就及时授予。
存在缺点:
(1) 需要网络基础设施重构
(2) 对其他用户不公平
Tutti采用对DDL敏感的资源供应方式,轻量级、公平共享。作为用户空间守护进程促进RAN和边缘服务器的主动交互。
![[Pasted image 20231024221455.png]]
Fig 12展示了操作流程。
获取PRB Grant状态,判断是否接近截止时间(阈值100ms)。若时间充足,执行公平的优先级调整,资源倾斜到延迟敏感型用户;如果DDL接近,采用加速机制加速分配。即,在保证应用程序生存的条件下,尽可能将资源倾斜到延迟敏感型用户。
5.1 Incentive and Acceleration Mechanism(激励与加速机制)
公平分配条款的激励机制。
首先定义一个度量值
S
t
\mathcal{S}_{t}
St,表达在TTI传输时间间隔内,获取资源PRB分配时的满意程度。
S
t
=
∑
k
=
1
K
s
g
n
(
m
t
k
)
⋅
ζ
[
P
k
,
Δ
t
k
(
P
R
B
)
]
,
\mathcal{S}_{t}=\sum_{k=1}^{K}sgn(m^k_t){\cdot}\zeta[P_{k},\Delta^k_t(PRB)],
St=k=1∑Ksgn(mtk)⋅ζ[Pk,Δtk(PRB)],
m
t
k
m^k_t
mtk表示满意度,有三个值:1(分配资源大于最低生存线),0(分配资源等于最低生存线),-1(分配资源小于最低生存线)。
为延迟敏感型用户提供:
S
t
∗
=
s
g
n
(
m
t
k
)
⋅
ζ
[
P
k
,
Δ
t
k
(
P
R
B
)
]
\mathcal{S}_{t}^{*}=sgn(m^k_t){\cdot}\zeta[P_{k},\Delta^k_t(PRB)]
St∗=sgn(mtk)⋅ζ[Pk,Δtk(PRB)],文章接着调整延迟关键用户的服务优先级窗口
P
w
n
d
∗
P_{wnd}^*
Pwnd∗来引导资源的分配。
满足DDL的加速机制。
激励机制中仍存在风险:不能确保一个frame在DDL内完全交付。如,即使
P
w
n
d
∗
P_{wnd}^*
Pwnd∗以线性增长,由于存在其他更高优先级的用户,延迟关键用户也可能无法首先被分配资源。所以加入了bottom-line方法来保证最后期限。
加速机制的直观概念是,当用户TTL接近DDL时,优先为用户提供资源,文章以指数增加
P
w
n
d
∗
P_{wnd}^*
Pwnd∗的方法来实现。
P
w
n
d
∗
=
e
−
(
T
k
d
d
l
−
t
⋅
T
T
I
)
⋅
(
P
R
B
n
+
1
a
l
l
−
∑
i
=
1
t
P
R
B
i
g
r
a
n
t
)
\large{P_{wnd}^*=e^{-(T_{k}^{ddl}-t{\cdot}TTI){\cdot}(PRB_{n+1}^{all}-\sum_{i=1}^{t}PRB^{grant}_{i})}}
Pwnd∗=e−(Tkddl−t⋅TTI)⋅(PRBn+1all−∑i=1tPRBigrant)
(
T
k
d
d
l
−
t
⋅
T
T
I
)
(T_{k}^{ddl}-t{\cdot}TTI)
(Tkddl−t⋅TTI)表示DDL的接近程度,
(
P
R
B
n
+
1
a
l
l
−
∑
i
=
1
t
P
R
B
i
g
r
a
n
t
)
(PRB_{n+1}^{all}-\sum_{i=1}^{t}PRB^{grant}_{i})
(PRBn+1all−∑i=1tPRBigrant)表示资源分配的状态。
5.2 Standard-compatible Interaction Protocol(标准兼容交互协议)
目的:方便RAN与边缘服务器间的通信。
![[Pasted image 20231025164123.png]]
如图所示,根据SDN/NFV原则将软件空间分为用户区域和控制区域,与通用的标准相兼容。用户平面功能(UPF)起到传输流量的作用,控制平面则是与Tutti相关。
GTP-U、N4/N6、N5接口:保证数据包传输;
Northern API:Tutti和边缘应用程序交互,获取应用层上下文信息;
Southern API:Tutti和RAN之间,获取RAN状态和资源配置消息;
为了减少在接口通信中花费的时间,采取了以下措施:
1. 定义RESTful节点,统一两个API的消息类型
2. 以8bit标准化消息格式,包括协议版本、消息类型、标志和长度项。
6 IMPLEMENTATION(安装)
![[Pasted image 20231025170326.png]]
设备如图14,
蜂窝网络实现:选用修改后的“4G RAN with 5G Core”作为蜂窝实现。
在笔记本电脑上搭建基于srsRAN的4G LTE BS;
开发了基于free5GC的5G Core;
在LTE RF设置下对SIM卡进行重新编程
Tutti部署:
- Tutti 部署在一台边缘服务器上,该服务器的配置为 Intel I9-10900X 处理器和 NVIDIA Tesla V100 32G 显卡。
- 部署遵循 CUPS(Control and User Plane Separation)原则,分为数据面和控制面。
- 数据面负责将流量路由到边缘应用程序,采用了 LightEdge 作为简单的 UPF(User Plane Function)实现,使用 ETSI(European Telecommunications Standards Institute)兼容的 openvSwitch 并通过 P4 规则路由流量。
- 控制面包括两个模块,一个是定制需求模块(demand customization module),使用 Python 实现,负责根据需求调整资源。另一个是资源分配模块,使用 C/C++ 实现,用于实时分配资源。
- 为了在 Tutti 和底层蜂窝平台之间实现透明的互动(避免更改原始消息交互),采用了 5GEmPOWER 的切片管理和资源抽象层,用于监控 RAN 状态信息并执行 Tutti 的资源配置。
- 使用 Flask-RESTful APIs 实现了南北接口,其中南接口使用 C++ 编写,北接口使用 Python 编写
7 EVALUATION
7.1 Experiment Setup
系统级比较方法:
基线:srsRAN+LightEdge+边缘服务器,遵循多轮资源“请求-授予”机制;OnSlicing网络切片方法,针对视频分析进行了实现。
实验应用程序:
开发了具有不同QoE需求的应用程序,web uploading(流量短、突发)、file transfer(对延迟不敏感、消耗带宽大)。web上传的响应延迟从页面上传开始记录,直到ACK;FT使用数据块来作为统计单元。
实验场景:
空的篮球场,保持UE与BS的连接,在30m的覆盖区域内自由行走。
7.2 System-level Evaluation
Tutti显著提高了视频分析QoE。
Tutti可以满足三种任务的帧响应容差(200ms)。
Tutti的感知精度相对于二者均有提升。同时相对于“all in box”组也有较小的差距。
原因:RAN与MEC的耦合设计。
通过需求定制模块理解应用程序需求,准备足够的资源。
Tutti所有都在46.2ms内,OnSlicing有8.82%大于,srsEdge只有73%在46.2ms内。
对截止日期敏感的资源提供方法可以保证PRB配置的及时执行。
Tutti所有记录道都在17.29ms内,srsEdge则有19%,OnSlicing有6.06%的记录高于17.29ms。
Tutti对其他边缘辅助用例友好。
srsEdge与Tutti有不同的响应延迟。
srsEdge很平均,均在236ms左右;Tutti中,OD任务实现最小延迟响应,Web和FT则较高。
原因:Tutti能有效理解OD任务中的延迟关键型QoE需求,srsEdge则是依赖用户设备的缓冲状态来决定分配无线资源。
同时,Tutti在其他应用中不会导致性能下降的太多,在Web和FT中增加的延迟是可接受的。
频道随用户移动而波动时,Tutti非常有用。
首先在场景中测试信道波动,基于测试结果,进行了两个实验:
UE-BS距离从5-25米,在位置站点周围行走,绘制OD帧响应延迟。
Tutti保持200ms以内,srsEdge持续增加。
静态与动态进行比较:
无论是静态还是动态,srsEdge都不能满足DDL,而Tutti表现良好。
综上,作者认为Tutti良好的适应性在于它可以从RNIS中捕获ms级别的RAN状态信息,用来进行提前预测。
Tutti为多用户实现了可扩展性和公平性。
开发了跟踪驱动模拟器来评估大规模用户下的Tutti。
用户小于28时,共享相似的响应延迟;
28<用户<56时,延迟逐渐增加,但也在200ms内。
大于60时,明显增加。
但是,标准差小且稳定,都在10.49ms内,意味着Tutti的资源分配是公平的。
Tutti涉及轻量级通信和系统成本
①Northern API的通信时间平均仅为0.26ms
②Southern API通信时间也很低,即时消息包高达240字节,时间成本依然约为2ms
都可以归结为Tutti的标准兼容RESTful knot和统一信令格式。
CPU、GPU开销记录如表5,Tutti的CPU利用率仅增加了2.69%,GPU利用差距也相近。
7.3 Micro-benchmarks(小规模基准测试)
Tutti两个模块的作用:
三种方法消融研究:
- 基线,srsEdge
- srsEdge+跨层需求定制模块,记作DMD,遵循多轮资源“请求-授予”机制
- Tutti,将DMD与对截止日期敏感的资源提供模块(PROV)结合
![[Pasted image 20231025205919.png]]
两关键模块一起工作完全优于原有的机制。
DMD模块的预测精度:
DMD融合应用层和物理层信息来融合需求。
将其与三种方法进行了比较:
- Microscope,根据聚合的移动流量预测每个网络切片的需求。本质是应用层信息的估计,与物理层RAN无关。
- APP-pre,应用层预测
- Mean-pre,基于相应历史轨迹的平均值来预测应用层和物理层的动态。
DMD延迟分布在[56.4, 218.34]之间,Microscope在[89.57, 379.57],[90.2, 385.2]为APP-pre,[101.27, 395.2]为Mean-pre。后三种方法都存在异常响应值。
DMD的更好效果在于其在帧传输过程中的跨层自适应。Micro与APP缺少对物理层的考量。而二者中,APP-pre直接从帧内容预测应用,故精度略高于Micro。而Mean-pre考虑了跨层变化,但与DMD仍有差距。测试了实际与传输的PRB间隙,DMD的间隙最小,仅为3.48。
应用层内容变化的预测准确性。
Concerto,通过调整应用层变化来提高QoE,但其自适应是以一种隐含的方式进行的,只使用几个性能指标。Tutti可以获得更丰富的上下文信息来预测下一帧大小。为突出上下文信息对预测精度的增益,表6显示MAE和MRE。
对于①,使用Concerto作为比较方法,
F
i
F_{i}
Fi为其通过帧传输延迟,使用Wireshark在真实世界测试、收集其他性能指标。
对于②、③,使用APP-pre进行预测。APP-pre与③实现了更高的预测精度,③中的分割信息对提高预测精度有更大的贡献。
对链路动态的估计精度。
BS通常有两种了解链路动态的方法,一种基于测量,如PEB-CC;一种基于预测,如PHY-pre和Kriging。使用开源数据集进行了测试,PHY-pre的误差最小,是PEB的
1
3
\frac{1}{3}
31
,Kriging的
1
2
\frac{1}{2}
21左右。
PROV模块的资源提供有效性。
比较了PROV和三种资源分配方法的性能。
- 多轮资源“请求-授予”,RG
- LACO,保证低延迟用户的资源分配
- Oracle,理想化分配方法
- PROV,文中提出的方法,通过在线资源配置实现低延迟应用的资源分配。
实验中,在一个UE上运行OD任务,另一个UE上驱动FT应用程序作为背景流。FT遵循贪婪模式,其余三个通过DMD方法获得应用需求。
由于资源分配过程中的决策差异,PROV的延迟有更大的优势;同时PROV严格遵循预测的资源需求。
在资源供应轮次中,PROV与Oracle接近,仅与Oracle差1回合,这一轮的差距在于PROV采用了用户公平的服务优先级适应,与Oracle中的强制保留不同。
8 RELATED WORK
5G和MEC优化;延迟关键需求保证;跨层融合,提高需求QoE;
9 DISCUSSION
5G MEC的松散耦合缺陷是一个新问题,在于RAN与后端的不透明交互,这个问题会影响5G MEC的性能。
在开源5G蜂窝平台上进行实验。是优先事项。
10 CONCLUSION
文章提出了一个用户空间框架,将5G RAN与MEC耦合起来,了解应用层内容和链路层的动态,通过预测进行主动的资源授予,达到减小延迟的效果。同时,Tutti遵循轻量级和标准兼容的设计原则,便于部署在5G网络中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









