






习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
公式(6.50)为:
原因:在计算公式6.34中的误差项时,梯度可能过大,从而导致梯度过大问题。
解决办法:使用长短期记忆神经网络。
习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果
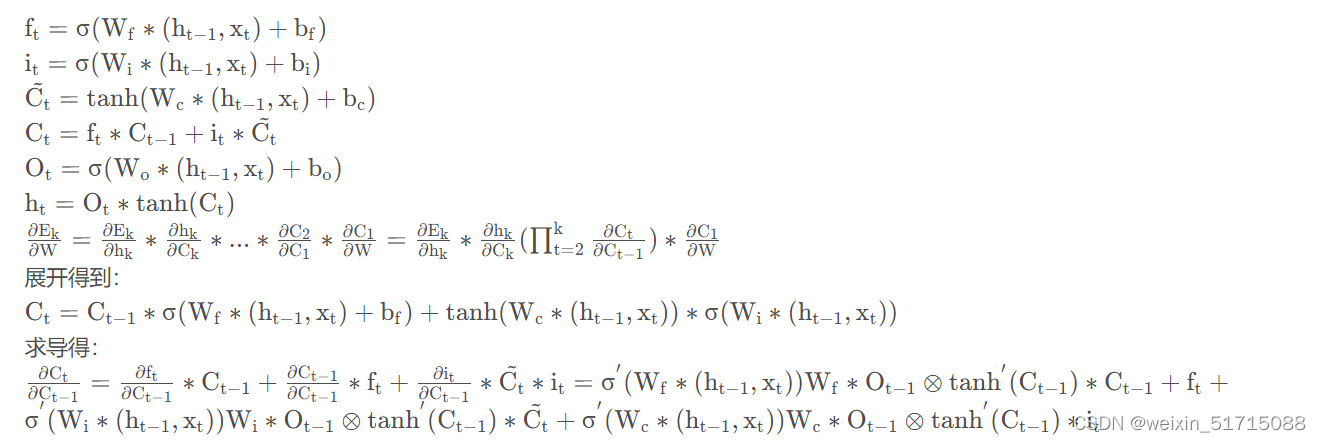
其中E为损失函数,由于LSTM中通过门控机制解决梯度问题,遗忘门,输入门和输出门是非0就是1的,并且三者之间都是相加关系,梯度能够很好的在LSTM传递,减轻了梯度消失发生的概率,门为0时,上一刻的信息对当前时刻无影响,没必要接受传递更新参数了。
习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果. (选做)


则有:
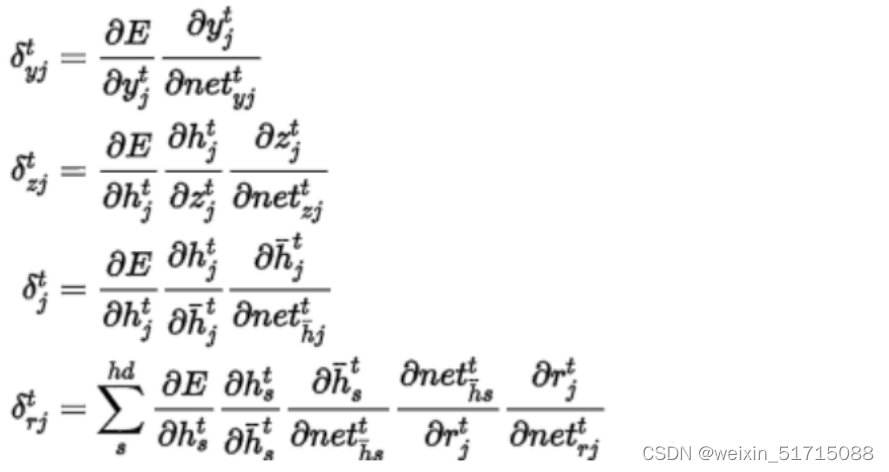
即是:
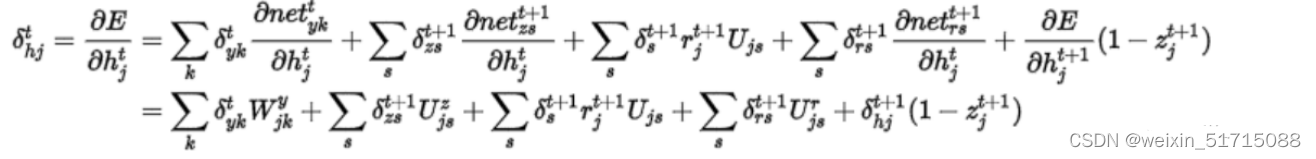
表示:

分析:GRU具有调节信息流动的门单元,但没有一个单独的记忆单元,GRU将输入门和遗忘门整合成一个升级门,通过门来控制梯度。
附加题6-1P:什么时候应该用GRU?什么时候用LSTM?(选做)
我查询了一下网上大神的说法,发现目前为止并没有一个很普适一致的观点,来说明到底那一个更好,哪一个在哪方面更加适用。只能说研究者在解决不同的问题上会选择不同的算法。

GRU的优点是其模型的简单性 ,因此更适用于构建较大的网络。它只有两个门控,从计算角度看,它的效率更高,它的可扩展性有利于构筑较大的模型;但是LSTM更加的强大和灵活,因为它具有三个门控。LSTM是经过历史检验的方法。
但大多数人会把LSTM作为默认第一个去尝试的方法。
总结
遇到纯理论的东西我是真的头疼,特别是去推导某个理论或者公式。所以只能边参考大神的东西边自己努力看懂之后尝试做,收获虽然不多但还是有的。















 1636
1636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









