







第五章
战士哥镇楼!!!
字符串



str.strip()是去掉特定的字符,与字符的顺序无关;
格式换字符串

name = "马冬梅"
age = 23
score=96
print('姓名:%s,年龄:%d,分数%f'%(name,age,score))#后加占位元素是元组形式
print(f'姓名:{name},年龄:{age},分数:{score}')
print('姓名:{0},年龄:{1},分数:{2}'.format(name,age,score))
formate格式控制

引导符写在''里面;
s='hello world'
print('{0:*<20}'.format(s))
print('{0:*>20}'.format(s))
print('{0:*^20}'.format(s))
print('{0:,}'.format(23145645612356.21331546))
print('{0:.6f}'.format(232356.213463521))
a=123465
print('二进制:{0:b},八进制:{0:o},十进制:{0:d},十六进制:{0:x},十六进制:{0:X}'.format(a))
bh=3.1415926
print('{0:.4f},{0:.4e},{0:.4E},{0:.4%}'.format(bh,bh,bh,bh))

字符串的编码和解码
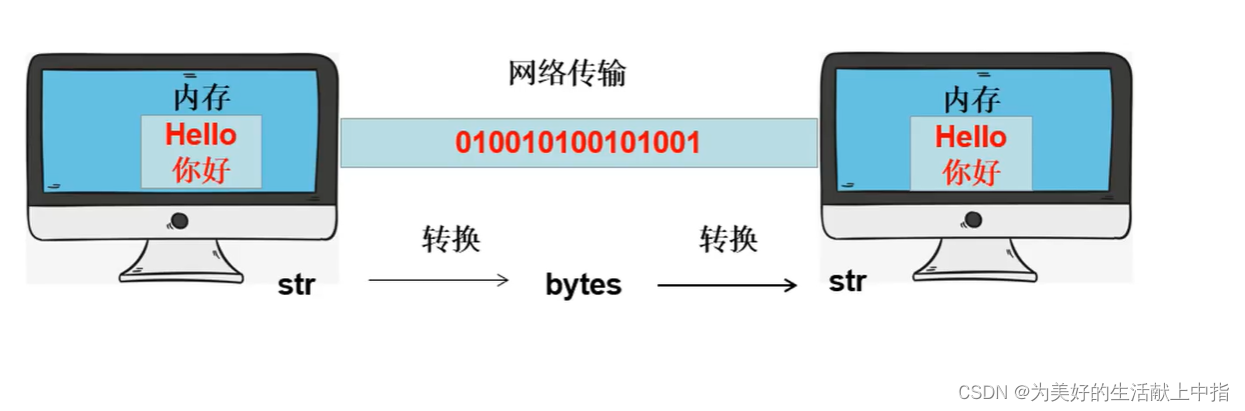

注:编码解码需要对应,默认utf-8;
数据验证

isnumerice()可识别数字,汉字,罗马形式的数字;二进制不行;
数据的处理

s1='[1,2,3,4,5,6,7,8,9]'
s2='[1,2,3,4,5,6,7,8,9]'
print(''.join([s1,s2]))
print('*'.join(['123','456','789','asd','sdgs']))

#使用格式化字符串拼接
s1='askjnfa'
s2='laisjidlas'
print('%s %s %s'%(s1,s2,s1))
print('{0} {1} {2}'.format(s1,s2,s1))
print(f'{s2}{s1}')

字符串去重



正则表达式
用于判断一个字符串是否符合某种模式;



match
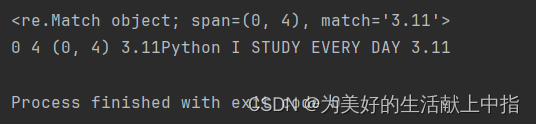
import re pattern='\d\.\d+'#找几.几几几几几 s='I study Python 3.11 every day' math=re.match(pattern,s,re.I) print(math) s2='3.11Python I STUDY EVERY DAY' match2=re.match(pattern,s2,re.I) print(match2) print(match2.start(),match2.end(),match2.span(),match2.string,match2.group())

search、findall
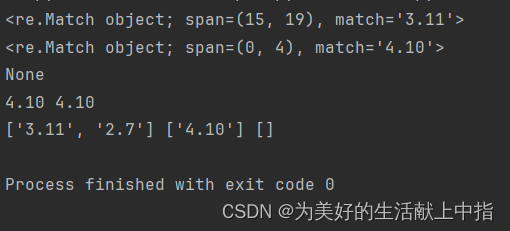
import re pattern='\d\.\d+'#找几.几几几几几 s='I study Python 3.11 every day Python2.7 i love you' math=re.search(pattern,s) print(math) s2='4.10Python I STUDY EVERY DAY' match2=re.search(pattern,s2,re.I) print(match2) s3='aslkdnaslkf' match3=re.search(pattern,s3) print(match3) print(match2.group(),match2.group()) lst=re.findall(pattern,s) lst1=re.findall(pattern,s2) lst2=re.findall(pattern,s3) print(lst,lst1,lst2)
sub、split
import re pattern='黑客|破解|反扒' sr='我想学python,破解vip视频,能否实现无底线反扒' new_s=re.sub(pattern,repl='***',sr) print(new_s)

总结


实战
1.
lst=['京A8888','津B6666','豫C123456']
for i in lst:
area=i[0:1]
print('归属地为',area)

2.
s='helloPython,helloJava,helloC++'
word=input('search:')
print('{0}在{1}中出现了{2}次'.format(word,s,s.upper().count(word)))
3.

4.用正则表达式找出需要的图片网址















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









