






算术运算
对除数为0的处理:
1/0 = inf 无穷大
-1/0 = -inf 负无穷大
0/0 = Nan
处理空值
方法一:将空值填充为0
import pandas as pd
path = 'C:/Users/Administrator/Desktop/playground2/计算.xlsx'
data = pd.read_excel(path)
i = data['1店'].fillna(0)+data['2店'].fillna(0) #NAN的用空值填
print(i)
0 8.0
1 1.0
2 1.0
3 0.0
4 0.0
方法二:灵活算术法
import pandas as pd
path = 'C:/Users/Administrator/Desktop/playground2/计算.xlsx'
data = pd.read_excel(path)
i = data['1店'].add(data['2店'],fill_value=0) #只是把一店和二店的nan填上0
print(i.fillna(0)) #把i为na的也填成0
0 8.0
1 1.0
2 1.0
3 0.0
4 0.0
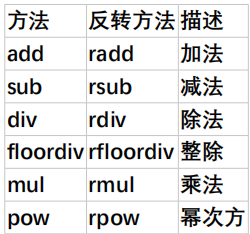
处理inf无穷大(分母为0)
加入代码 pd.options.mode.use_inf_as_na = True
import pandas as pd
path = 'C:/Users/Administrator/Desktop/playground2/计算.xlsx'
data = pd.read_excel(path)
i = data['1店'].div(data['2店'],fill_value=0)
print(i)
0 1.666667
1 0.000000
2 inf
3 NaN
4 NaN
加入代码
import pandas as pd
pd.options.mode.use_inf_as_na = True
path = 'C:/Users/Administrator/Desktop/playground2/计算.xlsx'
data = pd.read_excel(path)
i = data['1店'].div(data['2店'],fill_value=0)
print(i)
0 1.666667
1 0.000000
2 NaN
3 NaN
4 NaN
多层索引
分层索引的设置与查询
index为有序(数字和字母)
原数据
班级 学号 分数
0 1班 a 1
1 1班 b 2
2 1班 c 3
3 2班 a 4
4 2班 b 5
5 2班 c 6
6 3班 a 7
7 3班 b 8
import pandas as pd
path = 'C:/Users/Administrator/Desktop/playground2/多层索引.xlsx'
data = pd.read_excel(path,index_col=[0,1],sheet_name='有序') # index_col将第0列(班级)设为一层索引,第2列(学号)设为二层索引
print(data)
分数
班级 学号
1班 a 1
b 2
c 3
2班 a 4
b 5
c 6
3班 a 7
b 8
查询
import pandas as pd
path = 'C:/Users/Administrator/Desktop/playground2/多层索引.xlsx'
data = pd.read_excel(path,index_col=[0,1],sheet_name='有序')
data2 = data.loc[('1班',slice(None)),:] #slice(None)不能省略 不能改成,:,代表取一班任意学号,全部列
print(data2)
分数
班级 学号
1班 a 1
b 2
c 3
data2 = data.loc[('1班','a'),:]
print(data2)
分数 1
index为无序(中文)
print(数据.data.is_lexsorted()) # 检查index是否有序
False
import pandas as pd
path = 'C:/Users/Administrator/Desktop/playground2/多层索引.xlsx'
data = pd.read_excel(path,index_col=[0,1],sheet_name='无序')
data.sort_index(level = '科目') #先对第一层索引进行排序
data2 = data.loc[('语文',slice(None)),:] #再取值
print(data2)
分数
科目 得分
语文 最高 90
最低 50
多层索引的创建的方式【行】
推荐使用第三种(笛卡尔积)
多层索引 = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],names=['x','y'])
多层索引 = pd.MultiIndex.from_tuples([('a',1),('a',2),('b',1),('b',2)],names=['x','y'])
多层索引 = pd.MultiIndex.from_product([['a', 'b'], [1, 2]],names=['x','y'])
MultiIndex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
names=['x', 'y'])
都是创建第一层索引x中 对应 a,b 第二层索引y中对应1,2
注:如果不在MultiIndex中设置索引名,也可以事后设置
数据.index.names = ['x', 'y']
多层索引的创建的方式【列】
import pandas as pd
import numpy as np
data = np.random.randn(4,4)
ind = pd.MultiIndex.from_product([[2010,2016],[5,6]],names=['年','月']) #行索引
col = pd.MultiIndex.from_product([['西瓜','哈密瓜'],['黄瓜','番茄']],names=['水果','蔬菜']) #列索引
data2 = pd.DataFrame(data = data,index=ind,columns=col) #行列索引一一对应
print(data2)
分层索引计算
import pandas as pd
path = 'C:/Users/Administrator/Desktop/playground2/销售.xlsx'
data = pd.read_excel(path,header=[0,1]) #将第一行第二行设置为列索引
print(data.columns)
MultiIndex([('土豆', '销量'),
('土豆', '毛利'),
('倭瓜', '销量'),
('倭瓜', '毛利')],
)
原数据
土豆 倭瓜
销量 毛利 销量 毛利
0 10 5 20 6
1 11 4 30 5
data1 = data['土豆','销量']+data['倭瓜','销量'] #土豆和倭瓜的销量
print(data1)
0 30
1 41
data1 = data['土豆']+data['倭瓜'] #第二层索引下一一相加
print(data1)
销量 毛利
0 30 11
1 41 9
data1 = data['土豆']+data['倭瓜']
print(data1.columns) #此时索引是销量和毛利 需要加上第一层索引
Index(['销量', '毛利'], dtype='object')
data1 = data['土豆']+data['倭瓜']
data1.columns = pd.MultiIndex.from_product([['总计'],data1.columns]) #重新设置索引 总计为一层索引,原有的为二层索引
print(data1)
总计
销量 毛利
0 30 11
1 41 9
data1 = data['土豆']+data['倭瓜']
data1.columns = pd.MultiIndex.from_product([['总计'],data1.columns]) #重新设置索引 总计为一层索引,原有的为二层索引
data3 = pd.concat([data,data1],axis=1) #横向拼接
print(data3)
土豆 倭瓜 总计
销量 毛利 销量 毛利 销量 毛利
0 10 5 20 6 30 11
1 11 4 30 5 41 9















 4333
4333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









