






前言
本系列学习笔记基于B站up同济子豪兄视频子豪兄精讲斯坦福机器视觉
为记录学习过程诞生
L3:线性分类、损失函数、梯度下降
线性分类器是一种比较简单的分类手段,但是对于后续理解学习有一定的作用。
1.线性分类器
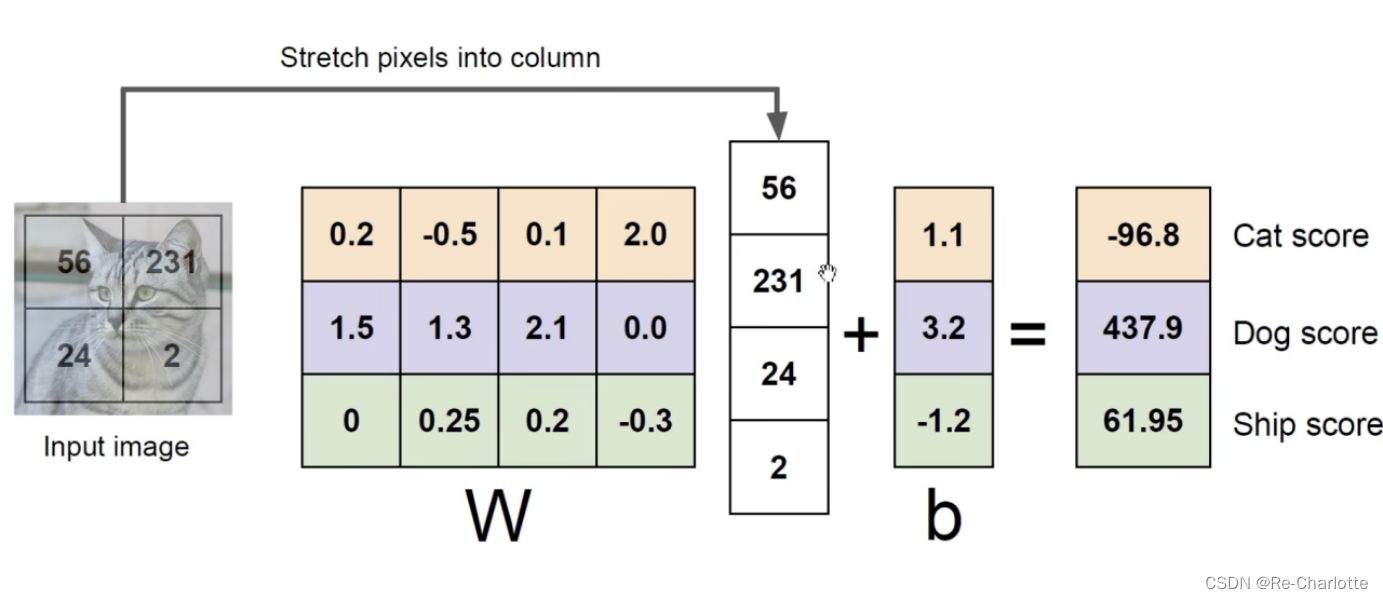
W表示每个种类的权重,该图像每个像素值乘以每个种类对应的权重,得到对应种类的分数,找出最大的分数作为该图像的预测结果(b为分类器截距)。
通过训练找出最合适的W和b。
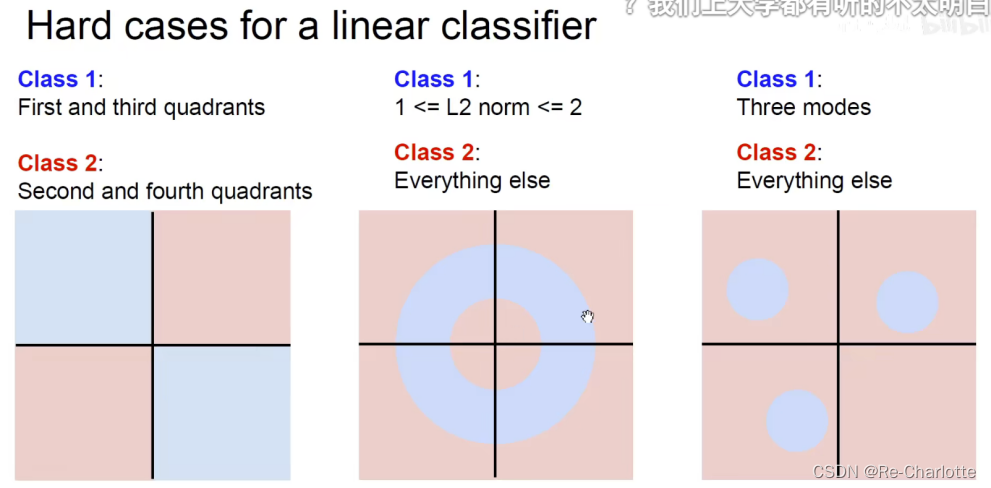
不适合的情况:
2. 线性分类损失函数
SVM 铰链损失函数:
不惩罚比真实值小1(冗余的安全度,常采用1是因为取单位1的意思)以上的铅矿,只惩罚比真实值大或相差很小(差值在1以内)的错误情况。


示例代码:

正则化(Regularization):
寻找到更加平滑的边界,防止过拟合。使得模型更加的简单,在测试集上可以更加的泛化。大部分分类器都会加一个正则化的项。

Softmax Classifier:
把分数(score)变为概率,不需要任何权重,就是数学运算。

使用指数函数将所有数都变为整数

通过归一化使其变成概率:保留大小关系,使所有种类相加为1.
Maximum Likelihood Estimation(极大似然概率):让正确时间发生的概率最大(使用联合概率,P是正确类别的概率,使用对数,把乘积变为加法。

Softmax vs. SVM
Cross-entropy loss:交叉熵损失函数
Hinge loss:铰链损失函数
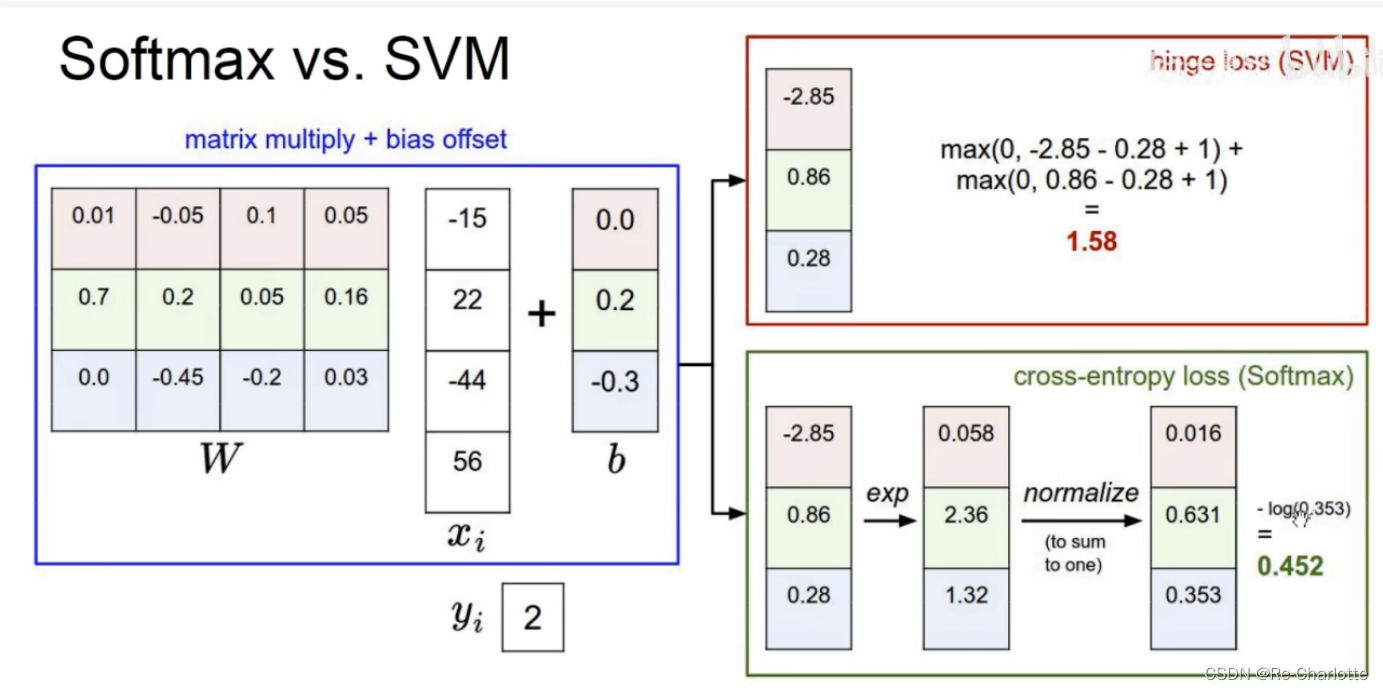

Optimistic(优化)
求可以使得损失函数下降最快的方向。
数值解:取一个很小的数算斜率求相反数(无法到极限)
解析解:求极限,使用导数公式(计算量很大)

minibatch:把数据分成比较小的数据集,得出每组的损失函数,分别同时计算。可以增快收敛速度,同时节约计算内存。

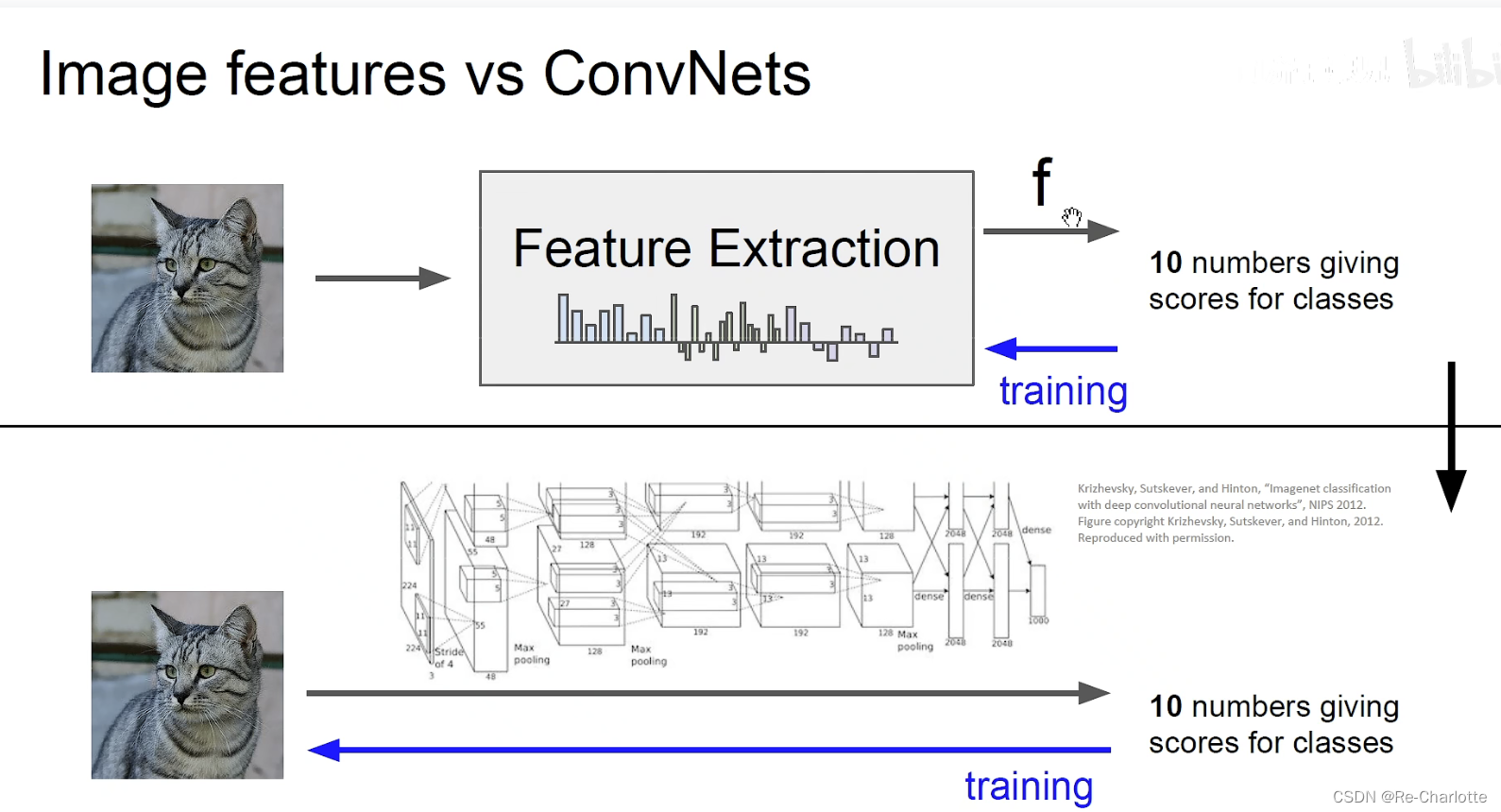
特征工程:
如何构建特征:
旧:人工构建特征。
新:使用数据驱动的方法(end to end)。卷积神经网络完成,用大量的数据,让卷积核自动训练,使得损失函数最小化。
















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









