






 该文介绍了如何使用YOLOv5进行图像识别,包括使用anconda创建环境,下载并配置yolov5,整理训练素材,进行模型训练,以及最终的效果预测。重点讲述了数据集的制作,如标签文件的创建和转换,以及训练过程中的配置和调整。
该文介绍了如何使用YOLOv5进行图像识别,包括使用anconda创建环境,下载并配置yolov5,整理训练素材,进行模型训练,以及最终的效果预测。重点讲述了数据集的制作,如标签文件的创建和转换,以及训练过程中的配置和调整。
YOLO图像训练测试
前言:本文将介绍yolov5从环境搭建到模型训练的整个过程。最后训练识别浣熊的模型。
1.anconda环境搭建 2.yolov5下载 3.素材整理 4.模型训练 5.效果预测
目录
YOLO图像训练测试1.anconda环境搭建2.yolov5下载3.素材整理4.模型训练5.效果预测
1.anconda环境搭建
提醒:所有操作都是在anconda的yolo的环境下进行的,在创建yolo环境后,之后每次进入CMD都需要切换到yolo环境中去(否则进入默认的base环境中)
Anaconda | Anaconda Distribution 下载对应版本anconda即可,这里就不介绍anconda安装过程了。
anconda安装好后,conda可以创建多个运行环境,默认是base环境。这里我们为yolo5创建一个环境。 打开CMD命令行,为yolov5创建一个环境,注意这里用的python版本是3.8,版本过低后面可能会报错
conda create -n yolo5 python=3.8
执行
conda info -e
即可看到我们刚刚创建的yolo5环境
![]()
正在上传…重新上传取消
执行
activate yolo
即可切换到我们的yolo环境下了。记住退出CMD或者切换CMD窗口之后,如果想要进入我们的yolo环境,都需要运行activate yolo指令。不然默认是在base环境下。
作者使用Pycharm进行本地多个Python环境进行管理
Pycharm安装教程链接: (99条消息) Pycharm的安装与激活(超详细)基QI学习的博客-CSDN博客pycharm激活
Pycharm——Python多环境搭建: (99条消息) Pycharm 配置多版本python环境_democwf的博客-CSDN博客
2.yolov5下载
1.下载yolo5源码
这里有两种方式进行下载: ①Yolov5 Github地址:https://github.com/ultralytics/yolov5 点击链接后,进入以下界面,可以点击Code->Download ZIP下载yolov5
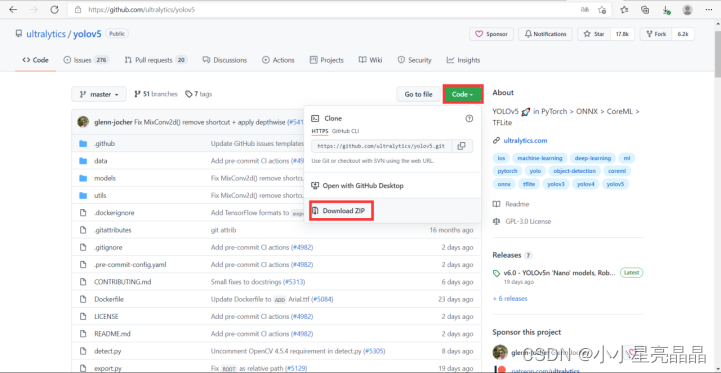
②也可以Win+R打开命令行窗口,直接git clone到本地工作目录,选择,等待下载完成:
git init git clone https://github.com/ultralytics/yolov5
下载完成后,在本地文件夹如下图
![]()
正在上传…重新上传取消
接下来用PyCharm打开yolo5本地文件夹
![]()
正在上传…重新上传取消
此处我们已经选择了刚刚建立的yolo5项目Python环境
![]()
正在上传…重新上传取消
文件夹里也包含了train.py文件,这个也是我们接下来训练yolo模型需要用到的启动文件。(大家看到的文件夹内容会和我的有点不一样,因为我的下载下来后又添加了一些文件)
requirements.txt文件里包含了yolo5所需要的第三方库,按照文件第一句提示
pip install -r requirements.txt
在命令行输入这句代码即可下载所需库
![]()
正在上传…重新上传取消
接下来我们就要开始训练yolo模型了。
3.素材整理
素材的文件夹结构有要求格式:
![]()
正在上传…重新上传取消
这是我的数据集文件夹,提供大家作为参考
接下来叫大家制作数据集
首先是照片,数量越多,训练出的模型效果越好。但也要根据自身需要,数量越多,训练时间越长。
接着是制作标签文件,作者使用的是labelImg,如果电脑上没有安装labelImg,参考教程在自己电脑安装
参教程如下:
(99条消息) labelImg使用教程G果的博客-CSDN博客labelimg使用教程
安装 labelImg
pip install labelImg #直接命令行输入
启动 labelImg
labelImg #直接命令行输入名称即可
启动界面如下:

注意:change save dir: 如果指定好图片路径后发现没有之前的标签,说明xml的路径指定错了,需要重新指定路径
注意:(因为使用cv2.imread读取图像,路径中不能有中文) 特别注意: 路径有中文也会导致图片和xml文件匹配不上,labelimg上不显示框
快捷键:W(创建方框),A(上一张),D(下一张)
可事先将训练的图片(train->images)与验证的照片(val->images)放到对应文件,文件名应有一致性,保证训练正常进行,例下图
![]()
正在上传…重新上传取消
,标签保存在对应的labels文件夹里,标签文件如下:
![]()
正在上传…重新上传取消
labelImg常规生成的是xml文件,还需要将xml文件转化成yolo5使用的txt文件,在照片文件夹目录创建一个Python文件,将以下代码放入
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["reccon"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('G:/yolov5/paper_data/Annotations/%s.xml' % (image_id), encoding='UTF-8') #修改成自己的xml文件路径
out_file = open('G:/yolov5/paper_data/labels/%s.txt' % (image_id), 'w') #修改成自己将保存txt文件的路径
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('reccon').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('G:/yolov5/paper_data/labels/'): #修改成自己的路径
os.makedirs('G:/yolov5/paper_data/labels/') #修改成自己的路径
image_ids = open('G:/yolov5/paper_data/ImageSets/Main/%s.txt' % #修改成自己的路径(image_set)).read().strip().split()
list_file = open('G:/yolov5/paper_data/%s.txt' % (image_set), 'w') #修改成自己的路径
for image_id in image_ids:
list_file.write(abs_path + '/paper_data/images/%s.jpg\n' % (image_id)) #修改成自己的路径
convert_annotation(image_id)
list_file.close()
运行程序会自动生成文件,转化后的txt标签文件保存在labels文件夹里,自己分类到对应的文件夹里
![]()
正在上传…重新上传取消
最后时配置文件 xxx.yaml(本项目是reccon.yaml)
![]()
正在上传…重新上传取消
本项目是做目标识别,故只有一个标签
train: G:\yolov5\reccon\train #对应训练集文件夹路径 根据自己的修改 val: G:\yolov5\reccon\val #对应验证集文件夹路径 根据自己的修改 nc: 1 #标签类别 根据自己的修改 name: ['reccon'] #标签名称,有几个写几个,按格式 ['a'] 根据自己的修改
如此数据集制作完成
4.模型训练
首先修改train,py文件
![]()
正在上传…重新上传取消
修改如下:
![]()
正在上传…重新上传取消
完成接下来晕运行train.py文件
开始训练!!!!!
5.效果预测
作者使用CPU版本,训练使用了接近三个小时,
在本地文件夹中生成本次识别的结果
![]()
正在上传…重新上传取消
![]()
正在上传…重新上传取消
文件夹内包含模型训练时各项数据以及曲线图,生成的模型保存在weights文件夹里
![]()
正在上传…重新上传取消
到此训练结束,我们就可以使用自己训练的模型来识别,
下来修改detect.py文件
![]()
正在上传…重新上传取消
运行detect.py文件
在本次目录生成一次测试,因为使用的是视频,所以生成的也是一个视频、
![]()
正在上传…重新上传取消


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









