






一、实验目的及内容
题目:进程(作业)调度算法
设计进程控制块的数据结构PCB,进程控制块可以包含如下信息:进程号、优先数、到达时间、需要运行时间、已用CPU时间、进程状态等等;进程的优先数及需要的运行时间可以事先指定(也可以由随机数产生)。进程的到达时间为进程输入的时间。进程的运行时间以时间片为单位进行计算。仿真时,每个时间片可以让cpu暂停1秒(或100ms,可自定义)。每个进程的状态可以是就绪 W(Wait)、运行R(Run)、或完成F(Finish)三种状态之一。就绪进程获得 CPU后只能运行一个时间片。
要求:对一个非抢占式多道批处理系统采用以下算法的任意两种,实现进程调度,并计算进程的开始执行时间,周转时间,带权周转时间,平均周转时间,平均带权周转时间。
1.先来先服务算法
2.短进程优先算法
*3.高响应比优先算法
开发语言:C语言
示例数据如下(也可自定义数据)
进程号 | 提交时间 | 执行时间 |
1 | 8:00 | 25分钟 |
2 | 8:20 | 10分钟 |
3 | 8:25 | 20分钟 |
4 | 8:30 | 20分钟 |
5 | 8:35 | 15分钟 |
二、实验原理及基本技术路线图(方框原理图或程序流程图)
1. 先来先服务算法
流程图:

2. 短进程优先算法

三、所用仪器、材料(设备名称、型号、规格等或使用软件)
DEV C++
四、实验方法、步骤(或:程序代码或操作过程)
- 先来先服务算法
先来先服务算法就是先来的作业先调度运行,后来的后运行。和队列的先进先出的意思是一样的。
FCFS是最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,系统将按照作业到达的先后次序来进行调度,或者说它是优先考虑在系统中等待时间最长的作业,而不管该作业所需执行时间的长短,从后备作业队列中选择几个最先进入该队列的作业,将它们调入内存,为它们分配资源和创建进程,然后把它放入就绪队列。

当在进程调度中采用FCFS算法时,每次调度是从就绪的进程队列中选择一个最先进入该队列的进程,为之分配处理机,使之投入运行。
- 短进程优先算法
短作业调度算法的核心在于,运行时间越短的作业就先执行。
这里有两个需要注意的地方:
1.首先,第一到达的作业一定先运行,因为经常题目中是给出所有的作业,很多初学者以为直接从中选取短作业。
2.要注意,在后续比较作业长短的时候,要看作业是否到达,就是上图的到达时间,没有到达的作业是不能比较的。
3. 短作业优先具有最短的平均周转时间
先来先服务算法代码:
#include <stdio.h>
int zhouzhuan(int ch[],int sh[],int num);
int main()
{
int ch[3]={0,2,3}; //到达时间的实参数组,可自己给出
int sh[3]={8,5,1}; //运行时间的实参数组,可自己给出
int num=sizeof(ch)/sizeof(ch[0]); //求出数组中的元素个数,即作业个数
zhouzhuan(ch,sh,num);
}
int zhouzhuan(int ch[] ,int sh[],int num)
{
int i;
int rt[100]; //运行时间
int at[100]; //到达时间
int et[100]; //结束时间
int ct[100]; //周转时间
float dq[100]; //带权周转时间=作业周转时间/作业执行时间
float totaltime; //周转时间
float avgtime; //平均周转时间
float totaldaiquan;//所有作业的带权周转时间累计和
float avgdaiquan; //平均带权周转时间
for(i=0;i<num;i++)
{
at[i]=ch[i]; //初始化到达时间数组
rt[i]=sh[i]; //初始化运行时间数组
printf("p%d:rt=%d,at=%d\n",i+1,rt[i],at[i]);
}
printf("FCFS:\n");
for(i=0;i<num;i++)
{
if(i==0) //i=0时是第一个到达
{
et[i]=rt[i]+at[i]; //第一个到达的,其结束时间就等于运行时间+到达时间
}
else if(at[i]<=et[i-1]) //当目前到达的作业在上一个作业结束前或刚好结束的时候就到达了,此时上一个作业的结束时间就是目前这个作业的开始时间
{
et[i]=et[i-1]+rt[i]; //结束时间=开始时间+运行时间 ,又因为这里的开始时间是上一个作业的结束时间,所以 结束时间=上一个作业的结束时间+这个作业的运行时间
}
//可能前一个已经运行结束,但是后一个还没有到达(也可能)
else
{
et[i]=at[i]+rt[i]; //结束时间=开始时间+运行时间。因为这个作业,在它上一个作业完成之后都没有到达,所以她的开始时间就是自己的开始时间
}
ct[i]=et[i]-at[i]; //周转时间=结束时间-到达时间
dq[i]=(float)ct[i]/(float)rt[i]; //带权周转时间=作业周转时间/作业执行时间
printf("p%d:到达时间=%d,运行时间=%d,结束时间=%d,周转时间=%d,带权周转时间=%.2f \n",i+1,at[i],rt[i],et[i],ct[i],dq[i]);
}
totaltime=0; //先设置一个初始值,不然计算会出错,赋垃圾值
totaldaiquan=0; //先设置一个初始值,不然计算会出错,赋垃圾值
for(i=0;i<num;i++)
{
totaltime+=(float)ct[i]; //累计周转时间
totaldaiquan+=(float)dq[i]; //累计带权周转时间
}
avgtime=totaltime/num; //平均周转时间
avgdaiquan=totaldaiquan/num; //累计平均周转时间
printf("累计周转时间为:%.2f\n",totaltime);
printf("平均周转时间为:%.2f.\n",avgtime);
printf("累计带权周转时间为:%.2f\n",totaldaiquan);
printf("平均带权周转时间:%.2f\n",avgdaiquan);
return 0;
}
短进程优先代码:
#include <stdio.h>
#include <stdlib.h>
#define INF 1000000.0
struct PCB {
char id[10]; // 进程ID
double reachTime; // 进程到达的时间
double needTime; // 进程完成需要的时间
double startTime; // 进程开始的时刻
double finishTime; // 进程完成的时刻
double cTime; // 进程周转时间
double wcTime; // 进程带权周转时间
char state; // 进程的状态( 设每个进程处于就绪R(ready),完成F(finish)两种状态之一 )
};
/* 两种情况:
1.在lastTime时刻,选择已经到达且拥有最短运行时间的进程
2.在lastTime时刻,没有进程到达,此时选择拥有最早到达时间的进程
*/
int findNext( struct PCB arr[], int length, double lastTime ) {
// p是已经到达且拥有最短运行时间的进程的下标
// q是没有到达的进程中拥有最早到达时间的进程的下标
int i, p, q;
double minNeedTime, minReachTime;
p = q = -1; minNeedTime = minReachTime = INF;
for( i = 0; i < length; i++ ) {
if( arr[i].state=='R' ) { // 进程处就绪状态
// 第一情况
if( arr[i].reachTime<=lastTime && arr[i].needTime<minNeedTime )
{ p = i; minNeedTime = arr[i].needTime; }
// 第二种情况
if( arr[i].reachTime>lastTime && arr[i].reachTime<minReachTime )
{ q = i; minReachTime = arr[i].reachTime; }}}
// p为-1时,代表在lastTime时刻还没进程到达,此时选择下一个最早到达的进程q
if( p != -1 ) return p;
return q;
}
int main() {
int num, i;
double lastTime; // 为上一个进程的完成时间,用来确定当前进程的开始时间
struct PCB *arr;
printf( "请输入进程数:" );
scanf( "%d", &num );
arr = (struct PCB*)malloc(num*sizeof(struct PCB));
lastTime = INF; // 最开始lastTime的为第一个作业的reachTime(到达时间)
printf( "请依次输入进程ID,进程到达时间,进程运行时间:\n" );
for( i = 0; i < num; i++ ) {
scanf( "%s%lf%lf", arr[i].id, &arr[i].reachTime, &arr[i].needTime );
arr[i].state = 'R';
if( lastTime>arr[i].reachTime ) lastTime = arr[i].reachTime;
}
// sum1为所有进程周转时间之和,sum2为所有进程带权周转时间之和
double sum1=0.0, sum2=0.0;
for( i = 0; i < num; i++ ) {
int p = findNext( arr, num, lastTime ); // 找到下一个将要执行的进程
// 两种情况:将要执行的进程可能已经到达,或者还没到达
if( arr[p].reachTime<=lastTime ) arr[p].startTime = lastTime;
else arr[p].startTime = arr[p].reachTime;
// 确定进程的完成时间,周转时间,带权周转时间
arr[p].finishTime = arr[p].startTime + arr[p].needTime;
arr[p].cTime = arr[p].finishTime - arr[p].reachTime;
arr[p].wcTime = arr[p].cTime/arr[p].needTime;
arr[p].state = 'F';
sum1 += arr[p].cTime;
sum2 += arr[p].wcTime;
lastTime = arr[p].finishTime; // 更新lastTime}
printf( "\n进程 到达时间 运行时间 开始时间 完成时间 周转时间 带权周转时间\n" );
for( i = 0; i < num; i++ ) {
printf( "%4s %8.2lf %8.2lf ", arr[i].id, arr[i].reachTime, arr[i].needTime );
printf( "%8.2lf %8.2lf ", arr[i].startTime, arr[i].finishTime );
printf( "%8.2lf %12.2lf\n", arr[i].cTime, arr[i].wcTime );
}
printf( "平均周转时间: %.3lf\n", sum1/num );
printf( "平均带权周转时间: %.3lf\n", sum2/num );
return 0;
} 五、实验过程原始记录( 测试数据、图表、计算等)
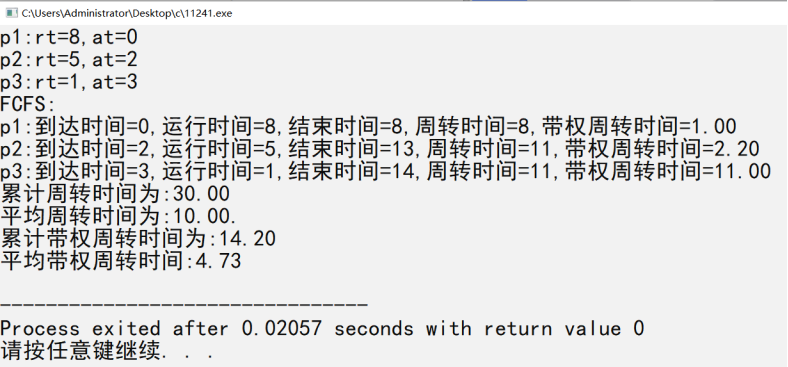

六、实验结果、分析和结论(误差分析与数据处理、成果总结等。其中,绘制曲线图时必须用计算纸或程序运行结果、改进、收获)
通过这次的上机操作也使我更加清楚的知道了先来先服务算法以及短进程优先算法的区别与实质。
FCFS,它只考虑进程进入就绪队列的先后,而不考虑它的下一个CPU周期的长短及其他因素。FCFS算法简单易行,是一种非抢占式策略,但性能却不大好。
SJF,不但要考虑进程的到达时间,还要考虑进程需要运行的时间。当一个进程正在运行时,假如有其他的进程到达,那么这些到达的进程就需要按照其需要运行的时间长短排序,运行时间短的在前,运行时间长的在后。
| 优点 | 缺点 |
先来先服务调度算法 | 公平,实现简单,有利于长进程调度 有利与CPU繁忙型进程,用于批处理系统 | 不考虑等待时间和执行时间,会产生饥饿现象,不利于处理短进程调度。 不利于I/O繁忙型进程,不适于分时系统。 |
短进程优先调度算法 | 有利于短进程调度 对预计执行时间短的进程有限分配处理机,通常后来的短进程不会抢先正在执行的进程
| 完全未考虑作业(进程)的紧迫程度,因而不能保证紧迫性作业(进程)会被及时处理。 不利于长进程调度
|
















 1371
1371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











