







- Dataset 加载数据集-使之支持索引
- DataLoader方便使用的时候拿出一个Mini-Batch来使用
1.为什么是Mini-Batch
-
罗翔老师喜欢说“正说反说折中说”,这里也是类似,我们使用一个样本的随机性来帮我们跨越鞍点(但速度太慢),使用Batch得到向量计算的优势,最大的提高计算速度(但准确率有差)。
-
而Mini-Batch就是每次既不是取一个,也不是取全部。而是把全部的分成几组,取其中的一个,这样就能很好的均衡这两种的优势,达到效果和效率的均衡点。
2.与Mini-Batch相关的概念
- Epoch训练的周期(即对全部的样本都参与了训练(前馈、反馈和更新))
- Batchsize进行一次训练需要的样本数量
- Iterations就是迭代次数、(iterable对象需要使用yield)
- iterations=epoch/batchsize
3.dataloader
- 参数
- batch_size
- 可以选择shuffle
- Dataset需要支持索引+提供长度
- 使Dataloader能访问每一个内容
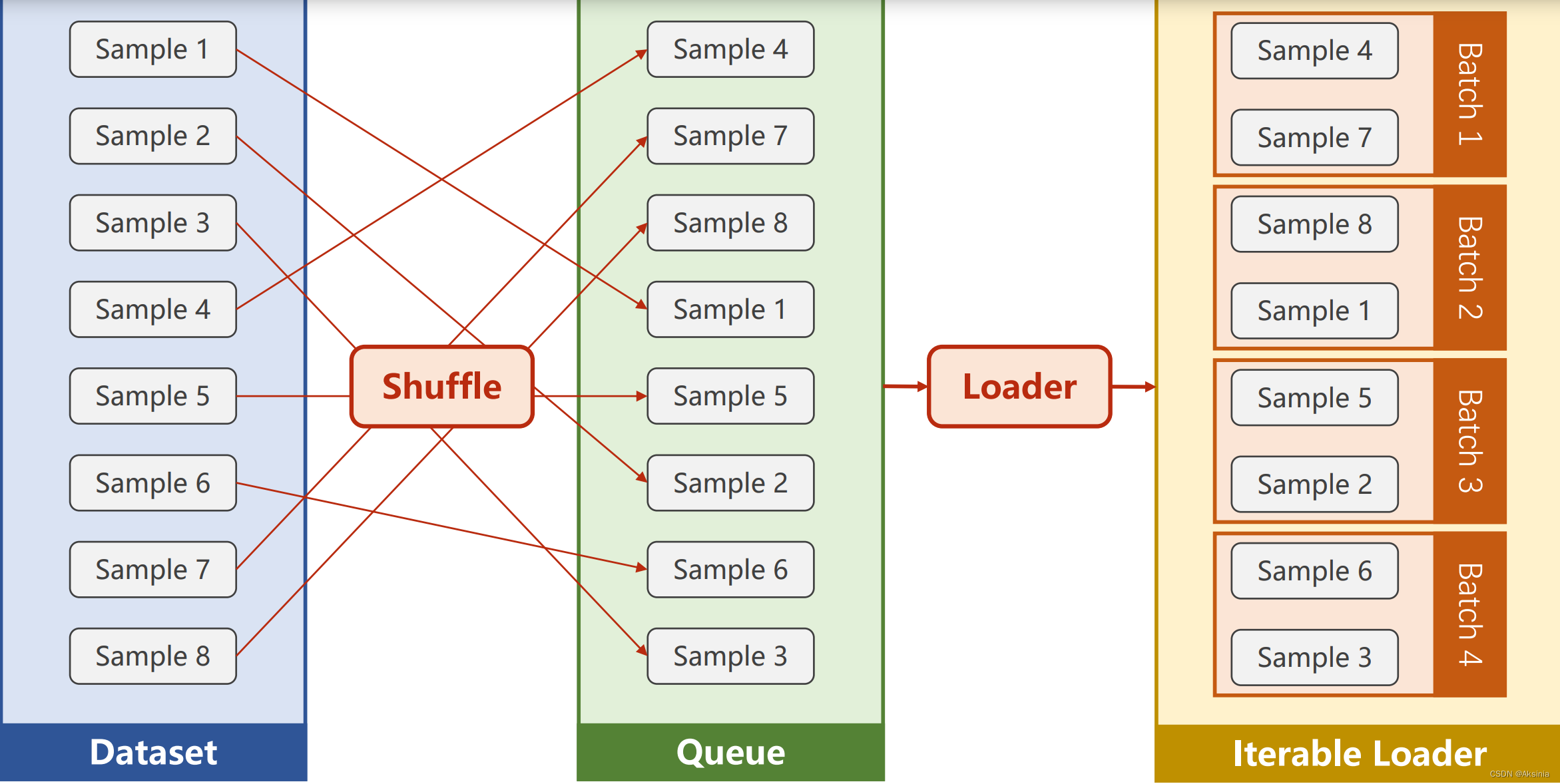
来自b站刘二大人的pytorch实践课程
- 使Dataloader能访问每一个内容
4.code
import torch
from torch.utils.data import Dataset
#Dataset是一个抽象类,抽象类不能实例化
#我们需要定义自己的类从这里继承,再构建自己实例化的类
from torch.utils.data import DataLoader
#处理数据处
class MyDataset(Dataset):
def __init__(self,filepath):#filepath文件在哪
#直接这里读数据没有必要,常常图片数据集都很大,不能都读到内存中
pass
def __getitem__(self,index):#getitem(for dataset[index])
pass
def __len__(self):
pass
dataset=MyDataset("mytest.xyz")#具体自己写
trainloader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
#在训练时
for epoch in range(100):
for i,data in emumerate(train_loader,0):
...
注意在window直接运行dataloader可能会报错,常常我们把它封装到if语句中如下:
if __name__ == '__main__':
5.pytorch
pytorch的datasets给我们提供了很多实例
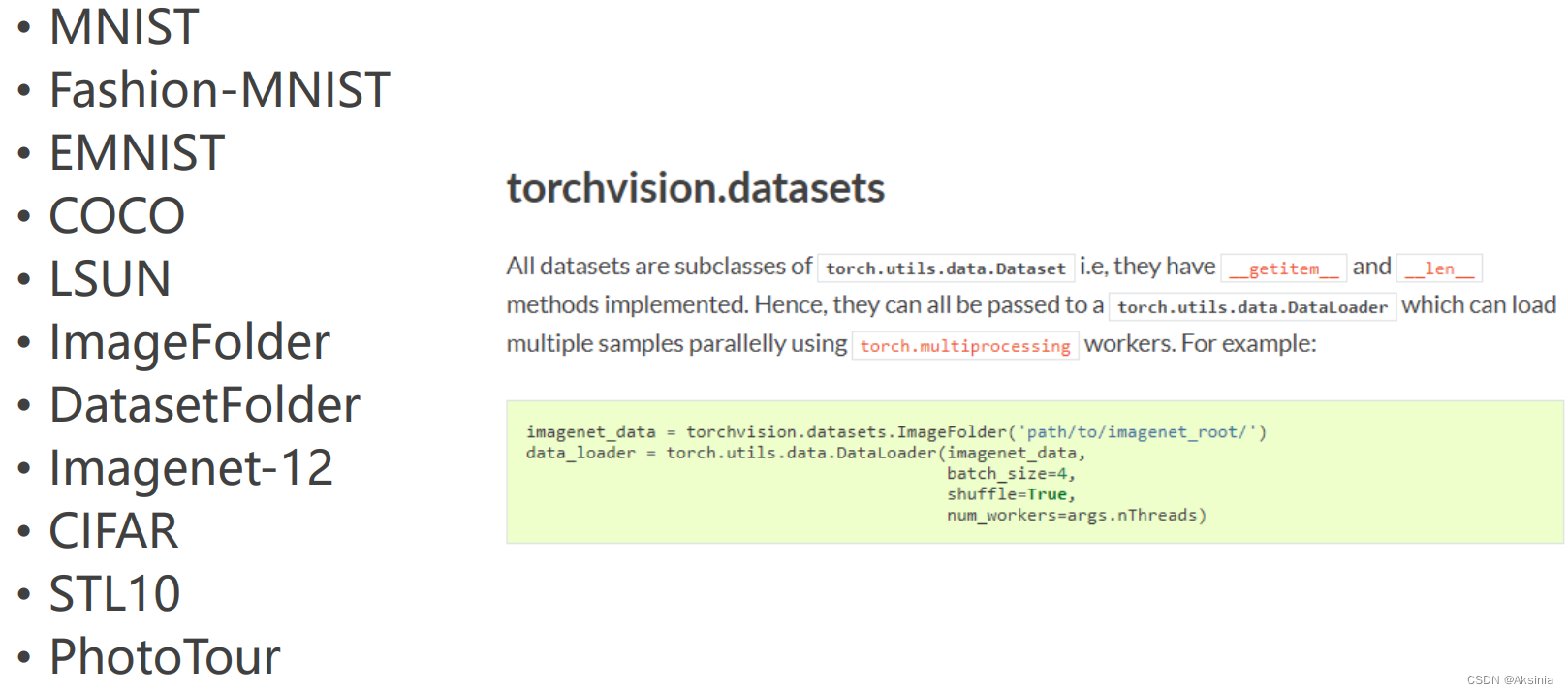
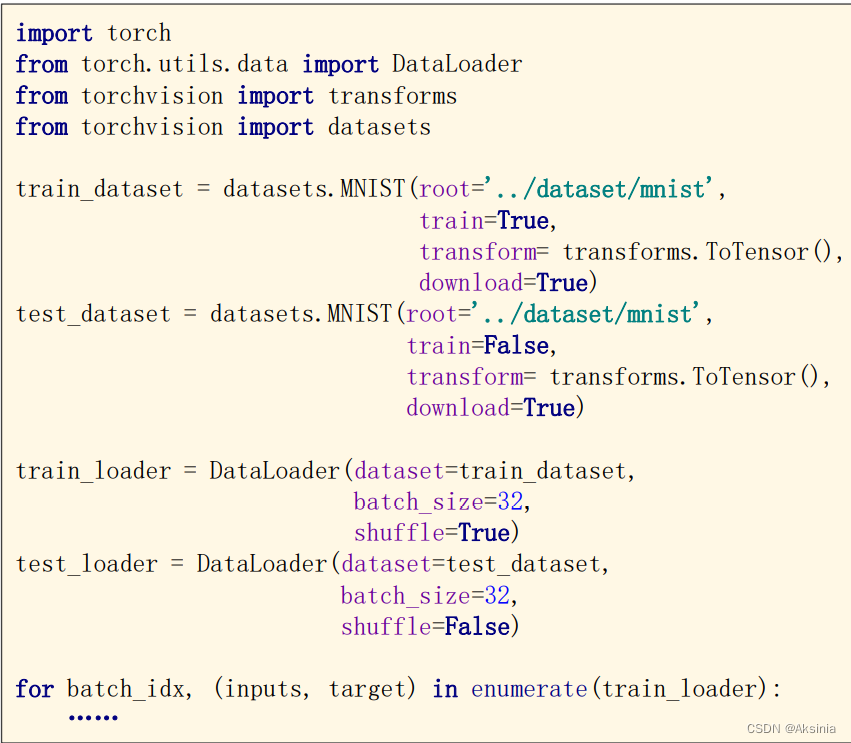
6.实战读取图片
具体的数据读取的时候可以使用OpenCV或者PIL两种方法,他们在具体的数据处理上也是不一样的,我更喜欢用PIL的方式。
使用(点击链接下载)UIEBD dataset数据集的raw-890为例()
import numpy as np
import torch
from torch.utils.data.dataset import Dataset
from torch.utils.data.dataloader import DataLoader
from torchvision.transforms import transforms
from pathlib import Path
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
transform = transforms.Compose([
transforms.Resize(350), #缩放图片保持长宽比不变,最短边为350像素
transforms.CenterCrop(320), #从图片中间切出320*320的图片
transforms.ToTensor(), #将图片(Image)转成Tensor,归一化至(0,1)
#需要对OpenCV读取的图像进行归一化处理才能与PIL读取的图像一致
#transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
#常用标准化
])
class MyDataset(Dataset):
def __init__(self,path,transform =None):
images_pth = Path(path)
image_list = list(images_pth.glob('*.png'))
image_list_str = [str(x) for x in image_list]
self.images = image_list_str
def __getitem__(self, index):
image_path = self.images[index]
image = Image.open(image_path)
image = transform(image)
return image
def __len__(self):
return len(self.images)
dataset = MyDataset(path = "你的路径\\raw-890",transform=transforms)
dataloader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=0)#128迭代少一点,一定要先使用transform转换成tensor对象
writer = SummaryWriter("你的名字")
step = 0
# 从test_loader中选取数据集data,其中data数据集是由dataloader加载器生成的以batch_size=128为单位的数据集
for data in dataloader:
imgs = data
writer.add_images("dataloader", imgs, step)
step = step + 1
writer.close()
输入tensorboard --logdir == " your name"就能显示出我们设置的dataloader了
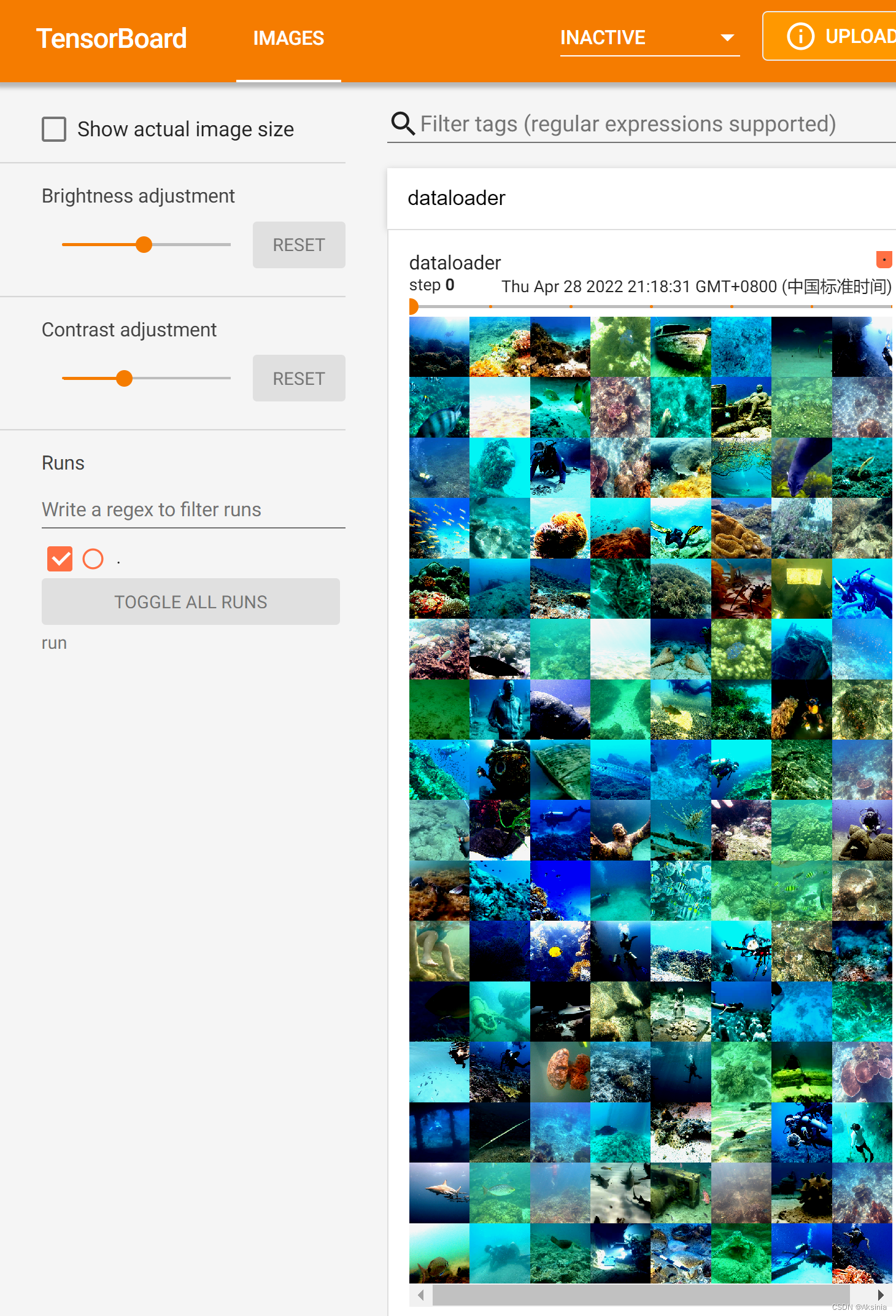

当然最后一个batch_size如果不够的话,肯定是真的读到结尾而没有一个batch_size的大小了。😃















 5131
5131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









