






一、链表
1.顺序存储和链式存储
- 1. 再谈数组—顺序存储
- 数组作为一个顺序储存方式数据结构为我们的程序设计带来了大量的便利,几乎任何的高级程序设计,算法设计都离不开数组的灵活使用,但是,数组最大的缺点就是我们的插入和删除时需要移动大量的元素,显然这需要消耗大量的时间。
- 以C语言数组插入一个元素为例,当我们需要在一个数组{1,2,3,4,5,6,7}的第1个元素后(即第2个元素)的位置插入一个’A’时
- 我们需要做的有,将第1个元素后的整体元素后移,形成新的数组{1,2,2,3,4,5,6,7},再将第2个元素位置的元素替换为我们所需要的元素’A’,最终形成我们的预期,一个简单的插入操作要进行那么多的步骤,显然不是很核算。
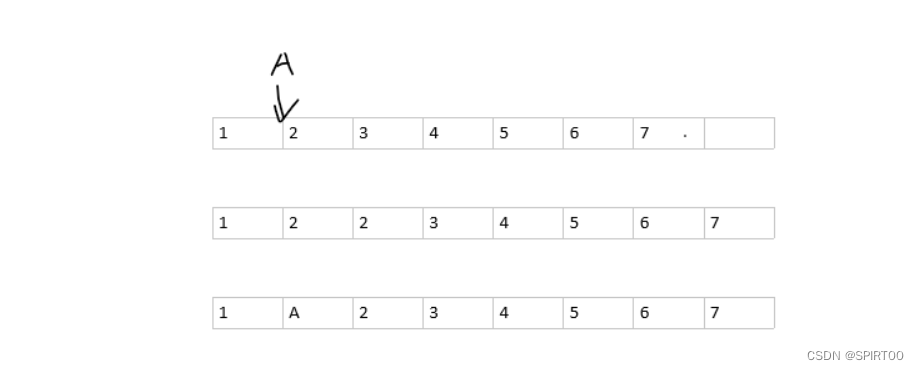
- 由示意图的操作,我们可以看出这样做的弊端有二
其一:所需要移动的元素很多,浪费算力。
其二:必须为数组开足够多的空间,否则有溢出风险。
- 2. 链表—链式存储
- 语言使用中,由于以上出现的这些问题,我们链表的概念就应运而生,链表通过不连续的储存方式,以及指针的灵活使用,巧妙的简化了上诉的内容,同时链表是自适应内存大小的,也就是说无论我们设多大的数据,理论上都可以实现(当然不能超过你的机器承载),注意,有许多较晚的语言通过底层的方式解决了数组插入和删除时的时间浪费,如PYTHON。
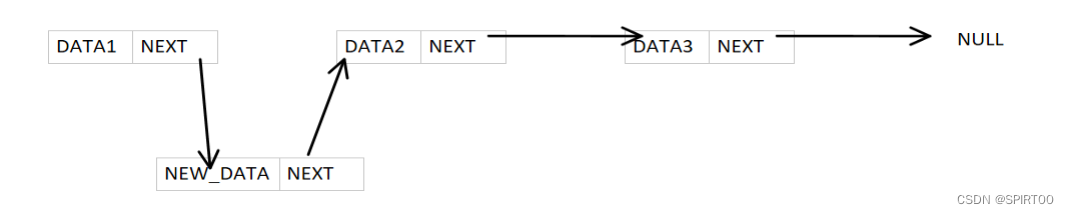
- 链表的基本思维是,利用结构体的设置,额外开辟出一份内存空间去作指针,它总是指向下一个结点,一个个结点通过NEXT指针相互练习,串联,这就形成了我们的链表

-
其中DATA为自定义的数据类型,可以是简单的int型,也可以是复杂的struct结构体类型,而NEXT为指向下一个链表结点的指针,通过访问NEXT,可以引导我们去访问链表的下一个结点。
-
对于一连串的结点而言,就形成了我们的链表

-
我们要进行上文所说的插入删除操作也就相当简单,只需要修改指针所指向的区域就可以了,不需要进行大量的数据移动操作。
-
相比起数组,链表解决了数组不方便移动,插入,删除元素的弊端,但相应的,链表付出了更加大的内存牺牲换来的这些功能的实现。
-
上文介绍的是单链表,接下来的本章节会依次给各位介绍:单链表,双链表,循环单链表,其功能不同但实现方式均大同小异。
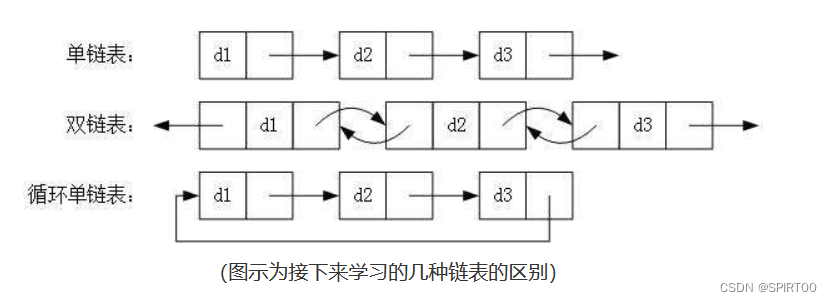
2.单链表的基本设计(C语言代码实现)
- 1. 单链表概念&设计
- 单链表是一种链式存取的数据结构,,链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。以“结点的序列”表示的线性表称作线性链表(单链表),单链表是链式存取的结构。
- 对于链表的每一个结点,我们使用结构体(struct)进行设计,其主要内容有:

- 其中,DATA数据元素,可以为你想要储存的任何数据格式,可以是数组,可以是int,甚至可以是结构体(这就是传说中的结构体套结构体)
- NEXT为一个指针,其代表了一个可以指向的区域,通常是用来指向下一个结点,链表的尾部NEXT指向NULL(空),因为尾部没有任何可以指向的空间了
- 故,对于一个单链表的结点定义,可以代码描述成:
//定义结点类型
typedef struct Node {
int data; //数据类型,你可以把int型的data换成任意数据类型,包括结构体struct等复合类型
struct Node *next; //单链表的指针域
} Node,*LinkedList;
//Node表示结点的类型,LinkedList表示指向Node结点类型的指针类型
- 2. 单链表的初始化
- 同任何的结构,类型一样,链表也需要初始化操作,初始化是创建一个单链表的前置节点并向后逐步添加节点,一般来说,我们所谓的初始化单链表一般指的是申请结点的空间,同时对一个结点辅以空值(NULL),其代码可以表示为:
LinkedList listinit(){
Node *L;
L=(Node*)malloc(sizeof(Node)); //开辟空间
if(L==NULL){ //判断是否开辟空间失败,这一步很有必要
printf("申请空间失败");
//exit(0); //开辟空间失败可以考虑直接结束程序
}
L->next=NULL; //指针指向空
}
- 在这里我们有一个注意点,就是一定要记住判断是否开辟空间失败,虽然在很多试题中以及常用的环境提供的环境非常安全,几乎没有开辟失败的存在,但是也一定要养成判断是否开辟失败并且判断失败后执行代码,但在生产中由于未知的情况造成一旦空间开辟失败任然在继续执行代码,后果将不堪设想,因此养成这样的判断是很有必要的,在C++中可以使用try-catch这样的语句进行优化。
- 3.创建单链表(头插入法)
- 在初始化之后,就可以着手开始创建单链表了,单链表的创建分为头插入法和尾插入法两种,两者并无本质上的不同,都是利用指针指向下一个结点元素的方式进行逐个创建,只不过使用头插入法最终得到的结果是逆序的。
如图,为头插法的创建过程:
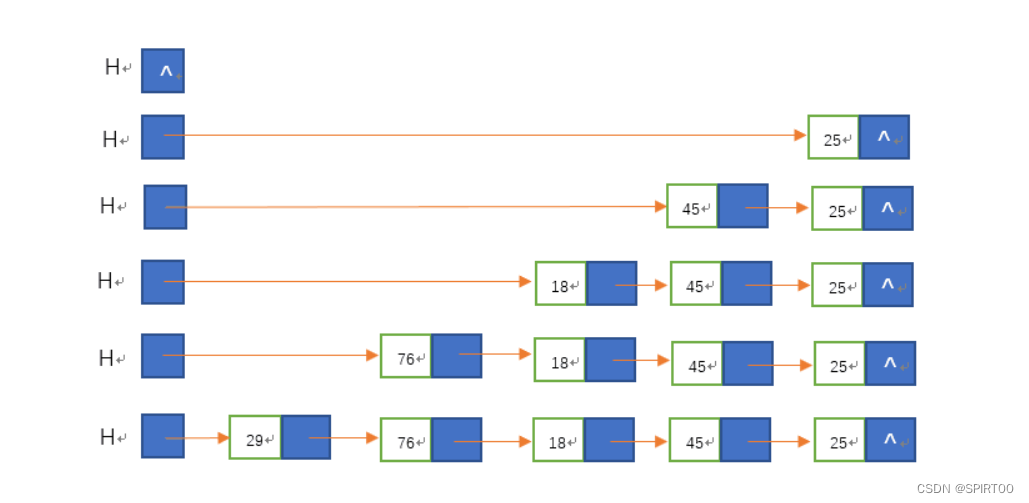
- 该方法从一个空表开始,生成新结点,并将读取到的数据存放到新结点的数据域中,然后将新结点插入到当前链表的表头,即头结点之后。
//单链表的建立1,头插法建立单链表
LinkedList LinkedListCreatH() {
Node *L;
L = (Node *)malloc(sizeof(Node)); //申请头结点空间
L->next = NULL; //初始化一个空链表
int x; //x为链表数据域中的数据
while(scanf("%d",&x) != EOF) {
Node *p;
p = (Node *)malloc(sizeof(Node)); //申请新的结点
p->data = x; //结点数据域赋值
p->next = L->next; //将结点插入到表头L-->|2|-->|1|-->NULL
L->next = p;
}
return L;
-
4. 创建单链表(尾插入法)
-
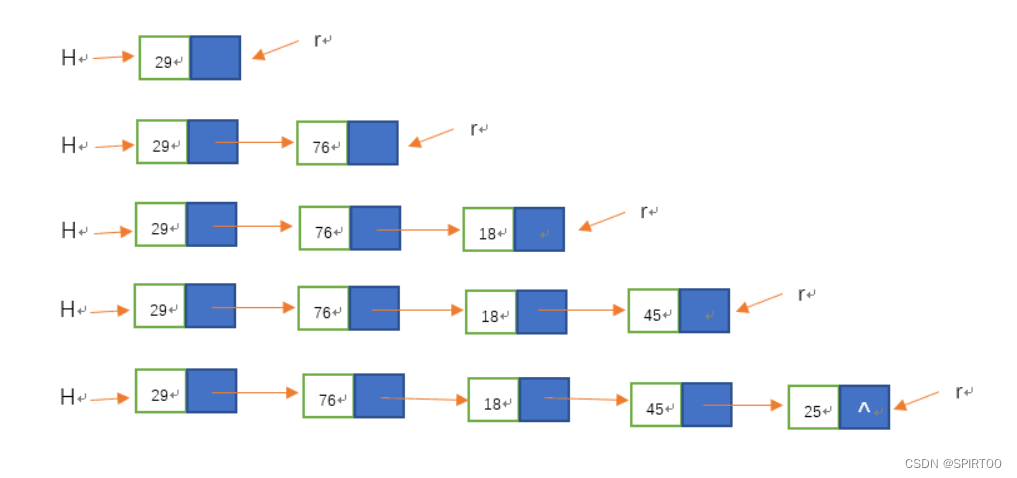
如图,为尾插入法的创建过程。
-
头插法建立单链表的算法虽然简单,但生成的链表中结点的次序和输入数据的顺序不一致。若希望两者次序一致,可采用尾插法。
-
该方法是将新结点逐个插入到当前链表的表尾上,为此必须增加一个尾指针 r, 使其始终指向当前链表的尾结点,否则就无法正确的表达链表。
//单链表的建立2,尾插法建立单链表
LinkedList LinkedListCreatT() {
Node *L;
L = (Node *)malloc(sizeof(Node)); //申请头结点空间
L->next = NULL; //初始化一个空链表
Node *r;
r = L; //r始终指向终端结点,开始时指向头结点
int x; //x为链表数据域中的数据
while(scanf("%d",&x) != EOF) {
Node *p;
p = (Node *)malloc(sizeof(Node)); //申请新的结点
p->data = x; //结点数据域赋值
r->next = p; //将结点插入到表头L-->|1|-->|2|-->NULL
r = p;
}
r->next = NULL;
return L;
}
总结
不忘初心,方能始终。
来自“https://www.dotcpp.com/course/96”















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









