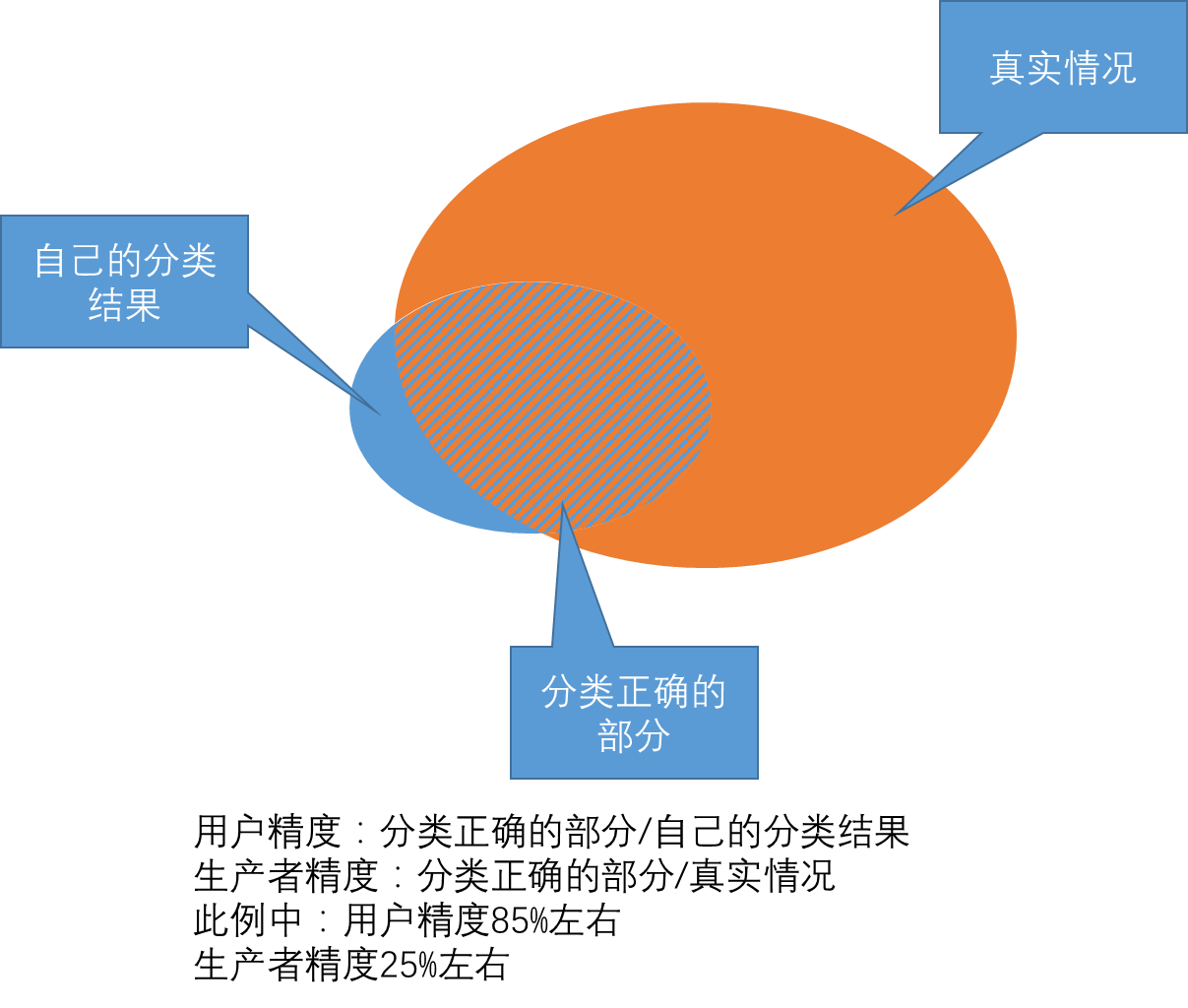
图片来源:用户精度与生产者精度_用户1737093685_新浪博客 生产者精度(1 - 漏分误差)是相对于真实值,用户精度(1 - 错分误差)相对于预测值, 也可参考以下内容 遥感影像混淆矩阵_分类模型的评估指标 | 混淆矩阵(2)_文小刚的博客-CSDN博客



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 3842
5900
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
3842
5900
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






