






贪心算法基本思想是由局部最优策略解决全局最优问题。贪心算法适用于解决的通常是那些解法结构可以分解为子问题最优结构的问题。
在学习贪心算法时,我主要在下面两道题时卡壳了。下面和大家分享一下这两道题。共勉!!!
1.区间选点问题
给定𝑛个闭区间,问最少需要确定多少个点,才能使每个闭区间中都至少存在一个点。
这道题我犯的错误主要是核心逻辑写错了,改了很久还未完全正确的代码如下:
#include <cstdio>
#include <algorithm>
using namespace std;
int n;
const int MAXNUM = 10005;
struct Area{
int x;
int y;
bool havePoint;
Area(){}
Area(int _x, int _y){
x = _x;
y = _y;
}
}a[MAXNUM];
bool cmp(Area a,Area b){
//正确 if(a.x != b.x) return a.x > b.x;
//正确 else return a.y > b.y;
if(a.y != b.y) return a.y > b.y; //错误
else return a.x > b.x; //错误
}
int count1 = 1;
int idx;
int pre = 0;
bool isComplete = false;
int main(){
scanf("%d",&n);
for(int i=0; i<n; i++){
scanf("%d%d",&a[i].x,&a[i].y);
a[i].havePoint = false;
}
sort(&a[0],&a[n],cmp);
//暴力化的无用功(下)
while(true){
for(idx = 1; idx < n; idx++){
if(!a[idx].havePoint && a[idx].x <= a[pre].x && a[idx].y >= a[pre].x){
a[idx].havePoint =true;
}
}
isComplete = true;
for(int idx1=1; idx1<n; idx1++){
if(!a[idx1].havePoint){
pre = idx1;
a[idx1].havePoint = true;
count1++;
isComplete = false;
break;
}
}
if(isComplete) break;
}
//暴力化的无用功(上)
printf("%d",count1);
return 0;
}其中代码的核心逻辑是排序策略,是先由左端点值由大到小排序,再由右端点由小到大,(这里不知道为什么我试了一下再由右端点由大到小排序也能完美通过,我先把这个问题放在这里思考一下,可能也可以,也可能是数据不全面),而不是先由右端点值排序(虽然只是简单的两行代码写错,但写对了就是满分,写错了可能就是0分或碰巧对几组数据20分左右,差距挺大的)。我没有清楚地认识到这一点以至于去怀疑其他局部推导全局的过程逻辑出错了。方向错了当然导致最终失败。结果:答案错误(20%数据通过测试)
2.拼接最小数
题目:给定𝑛个可能含有前导0的数字串,将它们按任意顺序拼接,使生成的整数最小。
输入:
第一行为一个正整数𝑛(1≤𝑛≤104),表示数字串的个数。
第二行给出𝑛个数字串(1≤每个串的长度≤9),用空格隔开。
输出:
输出一个整数,表示能生成的最小整数(需要去掉前导0)。
下面是我写的答案错误(20%数据通过测试)的代码:
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
int n;
// const int MAXNUM = 10005;
vector<vector<char>> a;
char temp;
// char a[MAXNUM][9];
bool findFirst = false;
int main(){
scanf("%d",&n);
for(int i=0; i<n; i++){
int j = 0;
vector<char> tran;
while(scanf("%c",&temp),temp != ' ' && temp != '\n'){
tran.push_back(temp);
}
a.push_back(tran);
}
sort(a.begin(),a.end());
for(int k=0; k<n; k++){
for(int t=0; t<(int)a[k].size(); t++){
if(a[k][t] != '0') findFirst = true;
if(findFirst){
printf("%c",a[k][t]);
}
}
}
if(!findFirst) printf("0");
return 0;
}下面是运行结果:
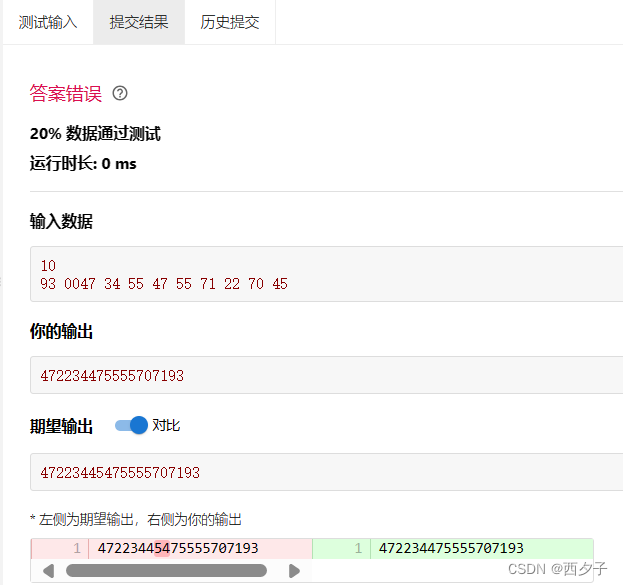
好吧,到现在我还没看出来我哪里错了,先放在这里,以后再回过头来研究。但是我知道题解的逻辑为什么是对的。在这里,我想提炼一下精华。题解代码如下:
#include <cstdio>
#include <algorithm>
using namespace std;
const int MAXN = 10000;
struct Interval { // 区间结构体定义
int l, r;
} interval[MAXN]; // 区间数组
bool cmp(Interval a, Interval b) { // 区间的比较函数
if (a.l != b.l) { // 如果左端点不同,那么按左端点从大到小
return a.l > b.l;
} else { // 否则,按右端点从小到大
return a.r < b.r;
}
}
int main() {
int n;
scanf("%d", &n);
for (int i = 0; i < n; i++) { // 输入n个区间的左右端点
scanf("%d%d", &interval[i].l, &interval[i].r);
}
sort(interval, interval + n, cmp); // 将区间数组进行排序
int num = 1, lastL = interval[0].l; // 排序后的第一个区间的左端点总是被选中
for (int i = 1; i < n; i++) { // 遍历剩余的区间
if (interval[i].r < lastL) { // 如果和上一个选中的区间不相交(注意此处是闭区间,所以不能取到等号)
lastL = interval[i].l; // 那么选中当前区间的左端点
num++; // 并令选中的点的数量加1
}
}
printf("%d", num); // 输出选中的点数量
return 0;
}积累:
1.字符串处理工具: 数据结构:C++的string容器; 输入输出: C++的<iostream>头文件中的cin和cout; 排序(数字串也可以用字典序比数值大小):string直接比较大小,如string1 < string2; 拼接:string直接相加,如string1 + string2。
总之关于字符串的处理使用上面一套极为方便,比我先用定长二维数组然后发现不方便排序又改用vector容器结果结果还是不对要好多了。
(题解来源网站:晴问算法)
最后总结一下:
1.答案错误,很少数据通过测试,很可能的原因是核心逻辑错误,一定要重新考虑一下整体逻辑问题。
2.字符串处理用string,cin,cout工具处理很方便。
3.闭区间选点的排序顺序是先左端点从大到小再右端点从小到大。
保留的思考问题:
1.我的第二题代码错在哪里?是什么地方理解不到位?
2.先左端点从大到小再右端点从大到小是对的吗?















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









