







MVCC多版本并发控制
MVCC是MySQL中基于乐观锁理论实现隔离级别的方式,用于实现已提交读和可重复读隔离级别的实现。MVCC机制会生成一个数据请求时间点的一致性数据快照,并用这个快照提供一定级别的一致性读取。从用户角度看好像是数据库可以提供同一个数据多个版本
MVCC多版本控制中,读操作可以分为两类:
- 快照读:读的是记录的可见版本,不用加锁
- 当前读:读取的是记录的最新版本,并且当前读返回的记录。如insert、delete、update
已提交读:每次执行语句的时候都重新生成一个快照
可重复读:同一个事务开始的时候生成一个当前事务全局性的快照。
MVCC每一行记录实际上有多个版本,每个版本的记录除了数据本身之外,增加了其他字段
DB_TRX_ID:记录当前事务ID
DB_ROLL_PTR:指向undo log日志上数据的指针
意向共享锁和意向排它锁(跟表所锁的概念相关)
要获得一张表的共享锁S或者排它锁X,需要确定这张表没有被其他事务获得过X锁
意像锁是我们MYSQL引擎自动加的。因此在加行所之前都会自动获取表的IS或者IX锁
当要获取表的X锁时,不需要在检查表中的那些行锁被占用,只需要快速检查IX和IS锁即可
1、意向锁是由InnoDB存储引擎获取行锁之前自己获取的
2、意向锁之间都是兼容的,不会产生冲突
3、意向锁存在的意义是为了更高效的获取表锁(表格中的X和S指的是表锁,不是行锁!!!)
4、意向锁是表级锁,协调表锁和行锁的共存关系。主要目的是显示事务正在锁定某行或者试图锁定某
行。
死锁
MYISAM没有死锁,总是一次获得所需的全部锁,要么全部满足,要么等待,因此不会出现死锁。
InnoDB中,除了单个SQL组成的事务外,锁是逐步获得的,因此在innodb中发生死锁是可能的
锁的优化建议
- 尽量使用较低的隔离级别
- 选择合理的事务大小,小事务发生锁冲突的概率小
Redo log 重做日志 :用于记录事务操作的变化、确保事务的持久性。
Redo log是在事务开始后,就开始记录,不管事务是否提交都会记录下来,在异常发生时,innoDB会使用redolog恢复到掉电前的时刻,从而保证数据的完整性。
持久性:依赖于重做日志
InnoDB修改操作数据,不是直接修改磁盘上的数据,实际只是修改Buffer Pool中的数据。InnoDB总是先把Buffer Pool中的数据改变记录到redo log中,用来进行崩溃后的数据恢复。 优先记录redo log,然后再慢慢的将Buffer Pool中的脏数据刷新到磁盘上。
MySQL优化
1)SQL和索引的优化
数据量太大 :采用分页
没有用到索引。多列索引的时候,没有用到第一列,导致索引名没有用上
联合查询的时候大小表设置的不合理,导致索引没有用上
整表查询,大表才能够用索引
多表查询的时候,尽量不要用dead in 子查询:可以用外连接和内链接代理dead in子查询。应用到索引的情况下不会产生中间表
2)应用上的优化:
连接数据库(可以引入 连接池中间间,节省了clent链接的效率)
引入缓存:存储热点数据(便于查找读取,位于内存上),这是serive首先访问内存上的redis,然后在访问mysql
Redis相关准备:
缓存数据一致性问题怎么解决?
缓存穿透
缓存雪崩
Redis还了解什么功能?(发布订阅等)
Mysql server上的优化:
关闭自适应哈希索引:如果hash索引使用频率不高,可以关闭,因为维护hash索引消耗过高
设置合理的innoDB_log_buffer 和 InnoDB_buffer_pool_size来减少磁盘IO

各种参数的配置:主要指MYSql server端的优化:主要指Mysql server启动时加载的配置文件的配置内容的优化(就是my.ini或者my.cnf)。可以对查询缓存进行调整。比如:如果查询频繁,则可以开启查询缓存,如果缓存数据过多,可以增加缓存容量
并发链接数和超时时间:在配置文件my.cnf和my.ini最下面可以修改最大链接数和超市时间
MySQl日志有四种:
1)慢查询日志:用来记录MySQL中响应时间超过阈值的语句,即指运行时间超过long_query_time值。开启慢查询日志在性能上会有一定的影响
2)错误日志:mysql服务运行过程中出现的cordump 、error、exception
3) 查询日志:记录所有的sql
4)二进制日志(BInLOG):记录了所有的DDL(数据定义语句)和DML(数据操纵语句),不包括数据查询语句。两个重要的应用场景:主从复制、数据恢复
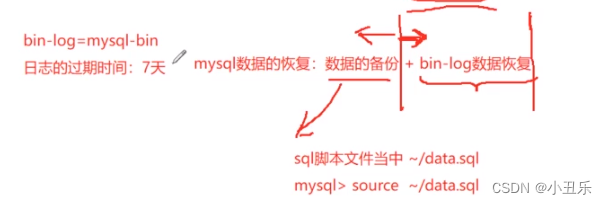
数据备份相关命令
Mysqlbinlog
Mysqldump
比如:mysqldump –u root –p mytest user > ~/user.sql(把pytest下的user备份到根目录下的user.sql)
如果要恢复数据,只需要执行命令: source ~/user.sql
以数据本身的形式导出数据:mysql –u root –p D school –e “select * from user where age>18” > ~/user.txt

一次SQL完整处理流程
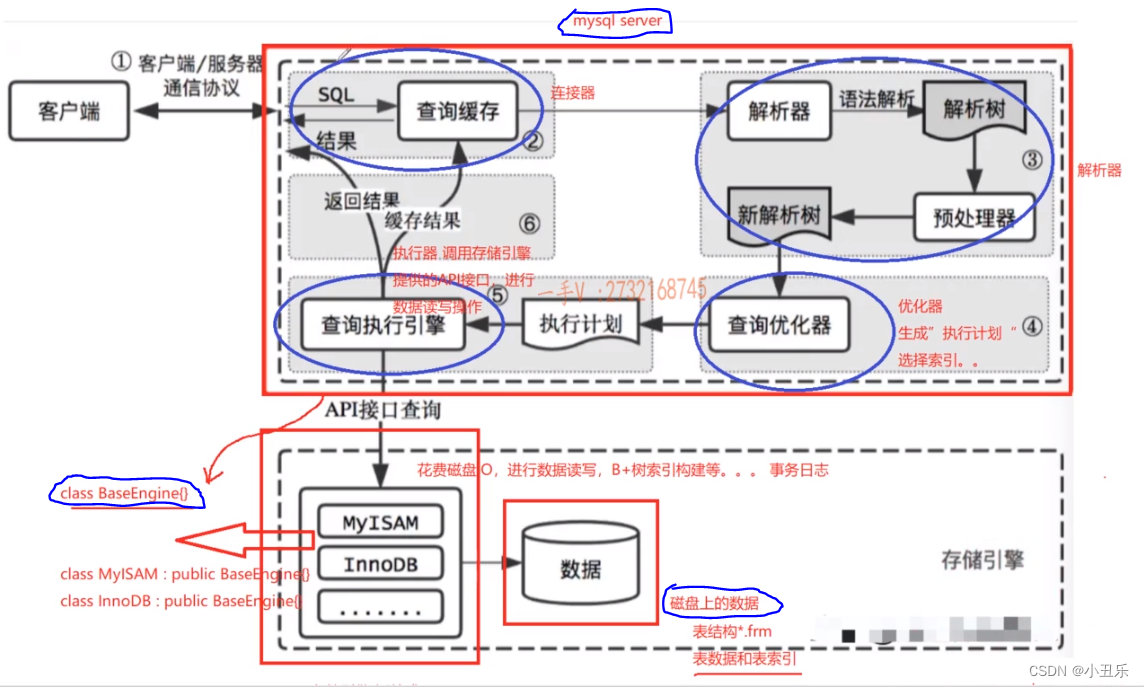
MySQL集群
如果一台mysql数据库的读写都在一台数据库服务器中操作,一般需要通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力
- 数据备份
- 读写分离、支持更大的并发
MySQL中间件:mycat
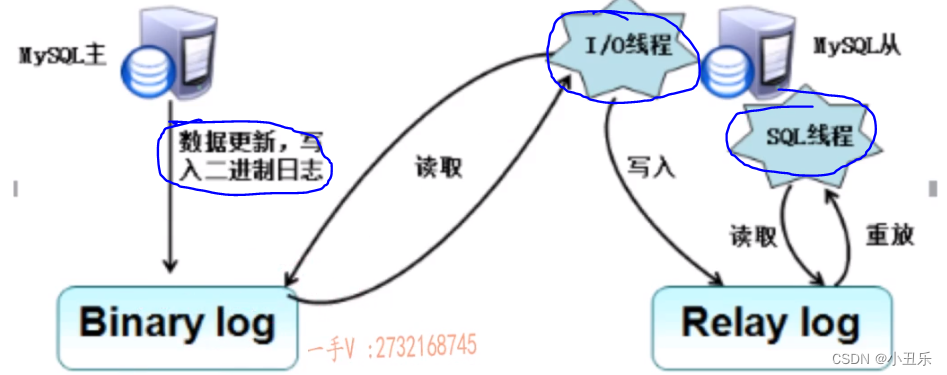
主从复制原理介绍: 同步、容灾
主从复制流程:两个日志(binlog二进制日志和relaylog日志)和三个线程(master的一个线程和slave的两个线程)
- 主库的跟新操作写入binlog二进制日志中
- Master服务器创建一个binlog转储线程,将二进制日志内容发送到从服务器
- 从服务器执行START SLAVE命令会在从服务器创建一个IO线程,接收master 的binlog复制到中继日志(Relay log)。
首先从服务器开一个工作线程(IO线程),IO线程在master上打开一个普通链接,然后开始binlog dump process,binlog dump process从master的二进制日志中读取事件。如果已经跟上master的写入二进制文件的速度,就会睡眠等待master产生新的事件,然后这个从服务器的IO线程把读取的事件写入到中继日志中
- SQL从线程从中继日志中读取事件,并重放其中的事件而更新slave服务器的数据,使得其与master的数据一致。中继日志位于OS缓存中。
读写分离
只有主库和从库保持数据同步,了在从库读段才能实现多个从库,进而实现高并发(一般主库为写,从库为读,通常数据读的操作要很多)
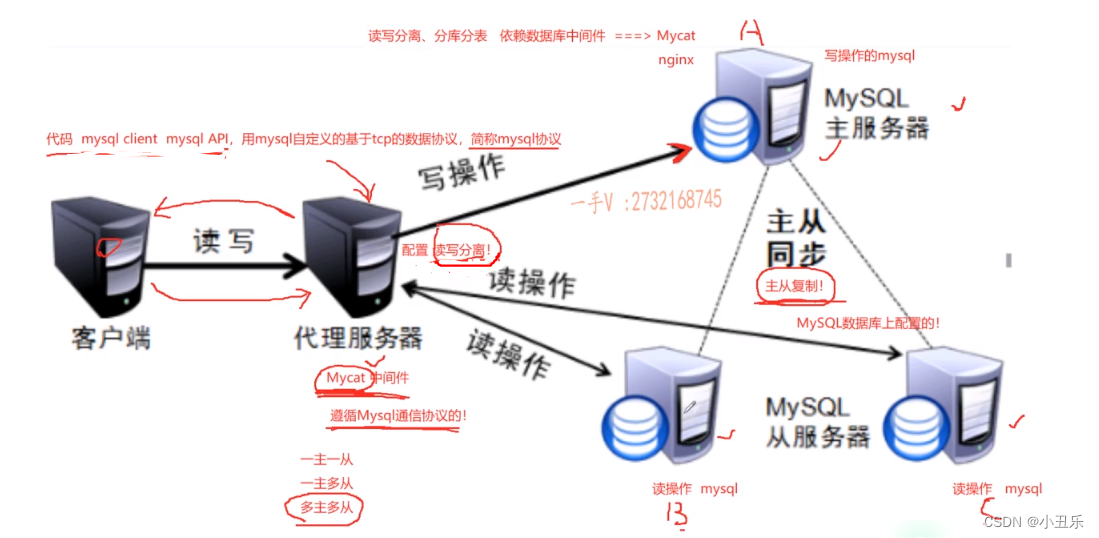
通过中间件mycat。默认端口是8066
GUI图形界面化工具:
SQLyog和Navicat
















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









