







生产者数据安全
一、数据分区
图解
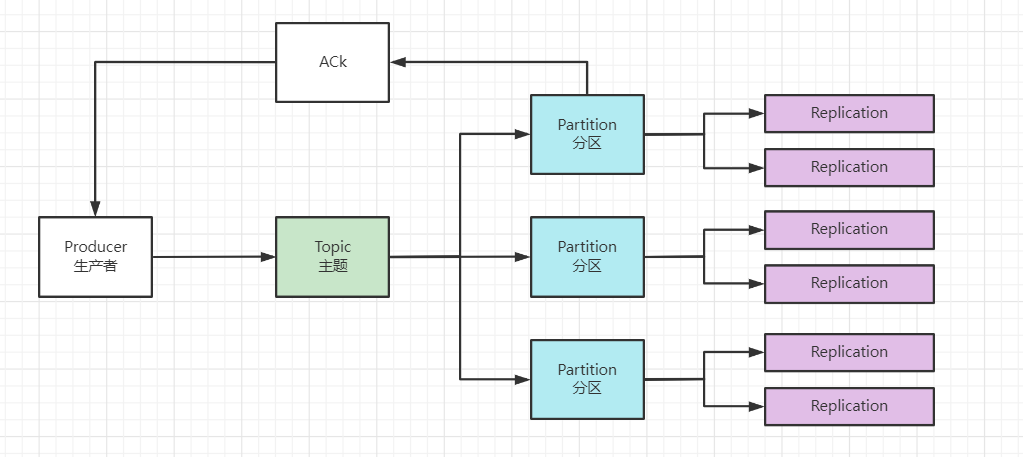
分区原因
- 1、方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器
- 2、一个 Topic 又可以有多个 Partition 组成,因此可以以 Partition 为单位读写了‘
- 3、可以提高并发,因此可以以 Partition 为单位读写
分区原则
-
将 Producer 发送的数据封装成一个 ProducerRecord 对象。对象包含:
- topic:string 类型,NotNull。
- partition:int 类型,可选。
- timestamp:long 类型,可选。
- key:string 类型,可选。
- value:string 类型,可选。
- headers:array 类型,Nullable。
二、数据可靠性保证
ACK机制
- 1、为保证 Producer 发送的数据,能可靠地发送到指定的 Topic
- 2、Topic 的每个 Partition 收到 Producer 发送的数据后,都需要向 Producer 发送ACK(ACKnowledge 确认收到)。
- 3、如果 Producer 收到 ACK,就会进行下一轮的发送,否则重新发送数据。
ACK时机
-
1、半数以上 Follower 与 Leader 同步完成,Leader 发送 ACK
-
2、全部 Follower 与 Leader 同步完成,Leader 发送 ACK。
-
3、
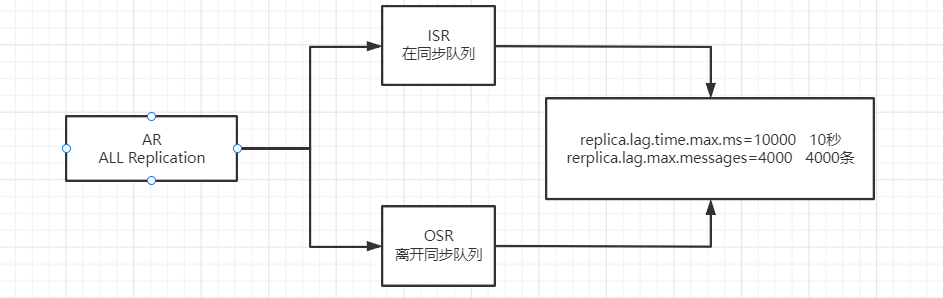
ISR(部分)-
1、关键词
- AR : Assigned Replicas 用来标识副本的全集
- OSR :out -sync Replicas 离开同步队列的副本
- ISR :in -sync Replicas 加入同步队列的副本
- ISR = Leader + 没有落后太多的副本;
- AR = OSR+ ISR。
-
2、Leader维护了一个动态的 in-sync replica set(ISR 和 Leader 保持同步的 Follower 集合)
-
3、
如果 Follower 长时间未向 Leader 同步数据,则该 Follower 将被踢出 ISR 集合,判断标准:-
超过10秒钟没有同步数据
- replica.lag.time.max.ms=10000
-
主副节点差4000条数据
- rerplica.lag.max.messages=4000
-
-
4、Leader 发生故障后,就会从 ISR 中选举出新的 Leader。
- kafka采用一种降级措施来处理:
- 选举第一个恢复的node作为leader提供服务,以它的数据为基准,这个措施被称为脏leader选举
-
-
图解
ACK应答机制
-
说明
- Kafka 为用户提供了
三种可靠性级别,用户根据可靠性和延迟的要求进行权衡
- Kafka 为用户提供了
-
注意
-
Producers可以选择是否为数据的写入接收ack,有以下几种ack的选项:request.required.acks
-
acks=0:- 这意味着
Producer无需等待来自 Leader的确认而继续发送下一批消息。 - 当 Broker 故障时有可能丢失数据。
- 这意味着
-
acks=1:- Producer 在
ISR 中的Leader 已成功收到的数据并得到确认后发送下一条 Message - 如果在 Follower 同步成功之前 Leader 故障,那么将会丢失数据。
- Producer 在
-
acks=-1:Producer 需要等待 ISR 中的所有 Follower 都确认接收到数据后才算一次发送完成,可靠性最高。- 在 Broker 发送 ACK 时,Leader 发生故障,则会造成数据重复。
-
-
-
图解

故障处理
-
图解
-
注意
-
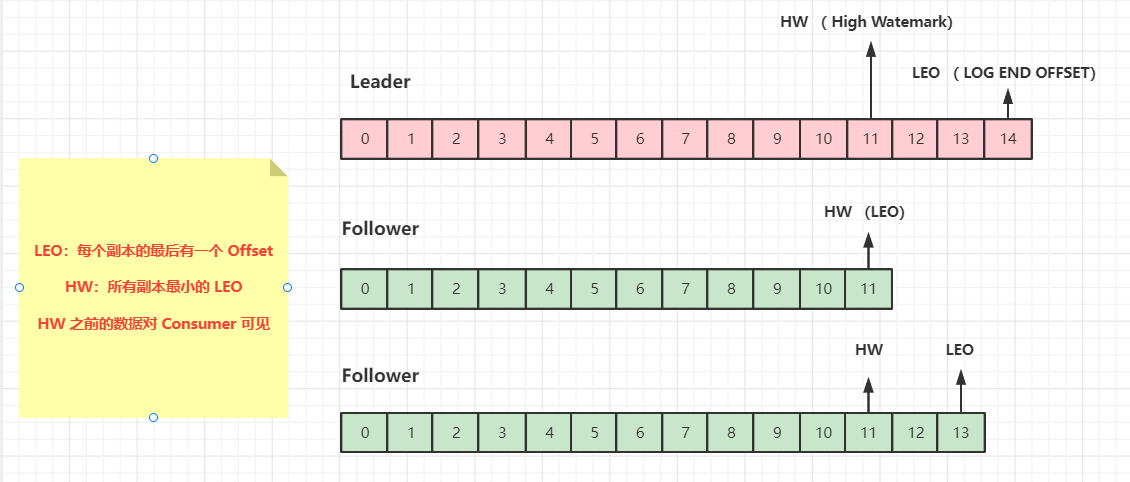
1、
LEO:每个副本最大的 Offset。 -
2、
Follower 故障:- 1、Follower 发生故障后会被临时踢出 ISR 集合,待该 Follower 恢复后,Follower 会 读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 Leader 进行同步数据操作。
- 2、等该 Follower 的 LEO 大于等于该 Partition 的 HW,即 Follower 追上 Leader 后,就可以重新加入 ISR 了。
-
3、
Leader 故障:- 1、Leader 发生故障后,会从 ISR 中选出一个新的 Leader,之后,为保证多个副本之间的数据一致性,其余的 Follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 Leader 同步数据。
- 2、
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
-
Exactly Once 语义
-
说明
-
1、将服务器的
ACK 级别设置为 -1,可以保证 Producer 到 Server 之间不会丢失数据,即 At LeastOnce 语义 -
2、将服务器
ACK 级别设置为 0,可以保证生产者每条消息只会被发送一次,即 At Most Once 语义。- At Least Once 可以保证数据不丢失,但是不能保证数据不重复;
- At Most Once 可以保证数据不重复,但是不能保证数据不丢失。
-
-
注意
-
Exactly Once- 1、重要数据既不重复也不丢失
- 2、0.11 版本的 Kafka,引入了
幂等性:Producer 不论向 Server 发送多少重复数据,Server 端都只会持久化一条。 - 3、At Least Once + 幂等性 = Exactly Once
- 4、要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。
- 5、开启幂等性的 Producer 在初始化时会被分配一个 PID,发往同一 Partition 的消息会附带Sequence Number
- 6、而 Borker 端会对 <PID,Partition,SeqNumber> 做缓存,当具有相同主键的消息提交时,Broker 只会持久化一条。
- 7、但是 PID 重启后就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区会话的 Exactly Once。
-
我是底线。。。

















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











