







Flume 基础概述

概述
概念
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统- Flume 官网
作用
- 1、
支持在系统中定制各类数据发送方,用于收集数据 - 2、同时,Flume提供对数据进行简单处理,并写到
各种数据接受方(可定制)的能力。
应用场景
- 1、线上数据一般主要是
落地(存储到磁盘)或者通过socket传输给另外一个系统 - 2、这种情况下,你很难推动线上应用或服务去修改接口,
实现直接向kafka里写数据 - 3、这时候你可能就需要flume这样的系统帮你去做传输。
Flume的体系架构
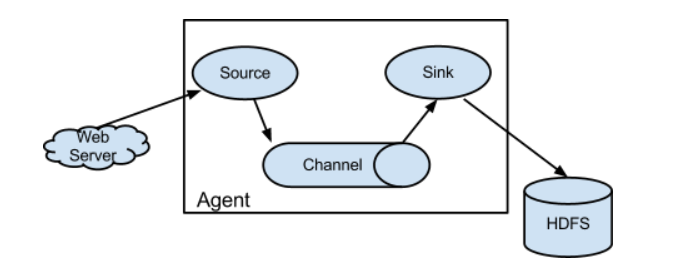
核心组件
-
1、
Client(客户端)- 1、Client 生产数据,运行在一个独立的线程
-
2、
Event(事件)- 1、一个
数据单元,由 消息头和消息体组成 - 2、Events 可以是日志记录、 avro 对象等
- 1、一个
-
3、
Flow(流)- 1、 Event 从源点到达目的点的迁移的抽象
-
4、
Agent(代理)- 1、 一个独立的Flume进程,包含组件Source、 Channel、 Sink
- 2、
每台机器运行一个agent,但是可以在一个agent中包含多个sources和 sinks - 3、Agent使用 JVM 运 行Flume
-
5、
Source(源)- 1、source从Client收集数据,传递给Channel
- 2、 数据收集组件
-
6、
Channel(通道)- 1、负责
接收 source 端的数据,并将其推送到持久系统或者是 sink 端 - 2、 中转Event的一个
临时存储,保存由Source组件传递过来的 Event - 3、Channel
连接sources 和 sinks ,这个有点像一个消息队列
- 1、负责
-
7、
Sink(存储)- 1、从Channel中
读取并移除Event, 将 Event 传递到 FlowPipeline 中的下一个 Agent - 2、如果有的话,Sink从Channel收集数据,运行在一个独立线程
- 1、从Channel中
-
8、
selector(选择器)- 1、作用于 source 端,然后
决定数据发往哪个目标
- 1、作用于 source 端,然后
-
9、
interceptor(拦截器)- 1、flume
允许使用拦截器拦截数据 - 2、
允许使用拦截器链,作用于 source 和 sink 阶段
- 1、flume
Flume优点
-
1、峰值处理
- 当收集数据的
速度超过将写入数据的时候,也就是当收集信息遇到峰值时, - 这时候收集的信息非常大,甚至超过了系统的写入数据能力,
- 此时,Flume会在数据生产者和数据收容器间做出
调整,保证其能够在两者之间提供平稳的数据
- 当收集数据的
-
2、Flume的
管道是基于事务,保证了数据在传送和接收时的一致性 -
3、 Flume是
可靠的,容错性高的,可升级的,易管理的,并且可定制的- 可以根据生产需要
自行定义一个数据来源端或者终点端
- 可以根据生产需要
-
4、
支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
Flume 执行流程
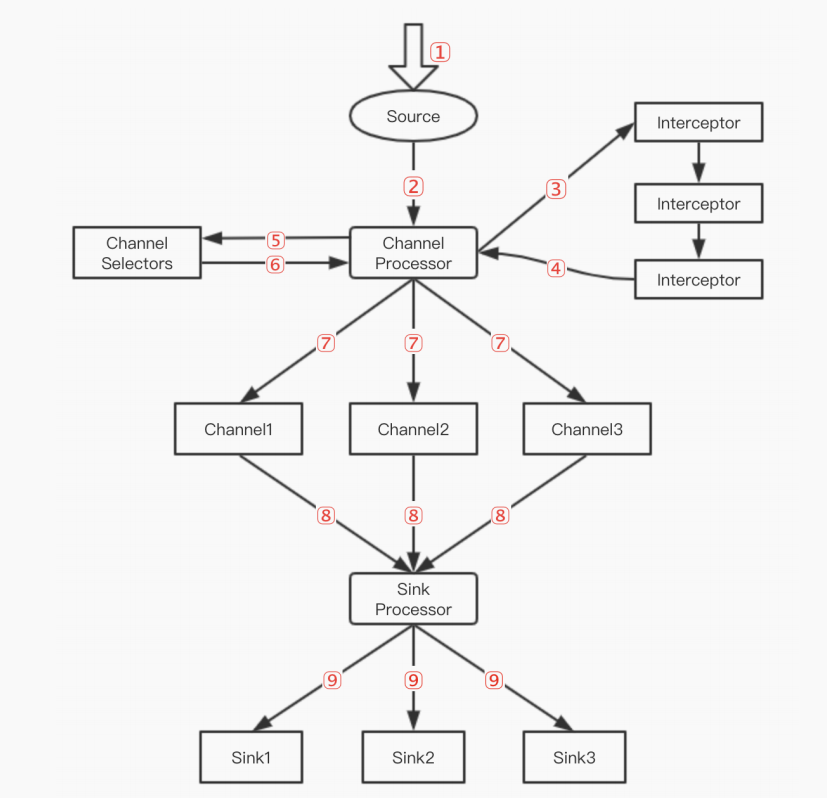
执行流程
- 1、Source
接受数据 - 2、Channel Processor
处理Event - 3、 Channel Processor 将 Event
传递给 interceptor 链对 Event进行过滤操作 - 4、过滤完之后再把 Event
发送回Channel Prodessor - 5、Channel Processor把 Event
发送给 Channel selectors - 6、Channel selector
返回 Event 属于哪个Channel - 7、根据第6步返回的结果,将Event
发送到指定的 Channel - 8、SinkProcessor 从 Channel 中
拉取数据 - 9、最后把数据
Sink出去
Flume 事务
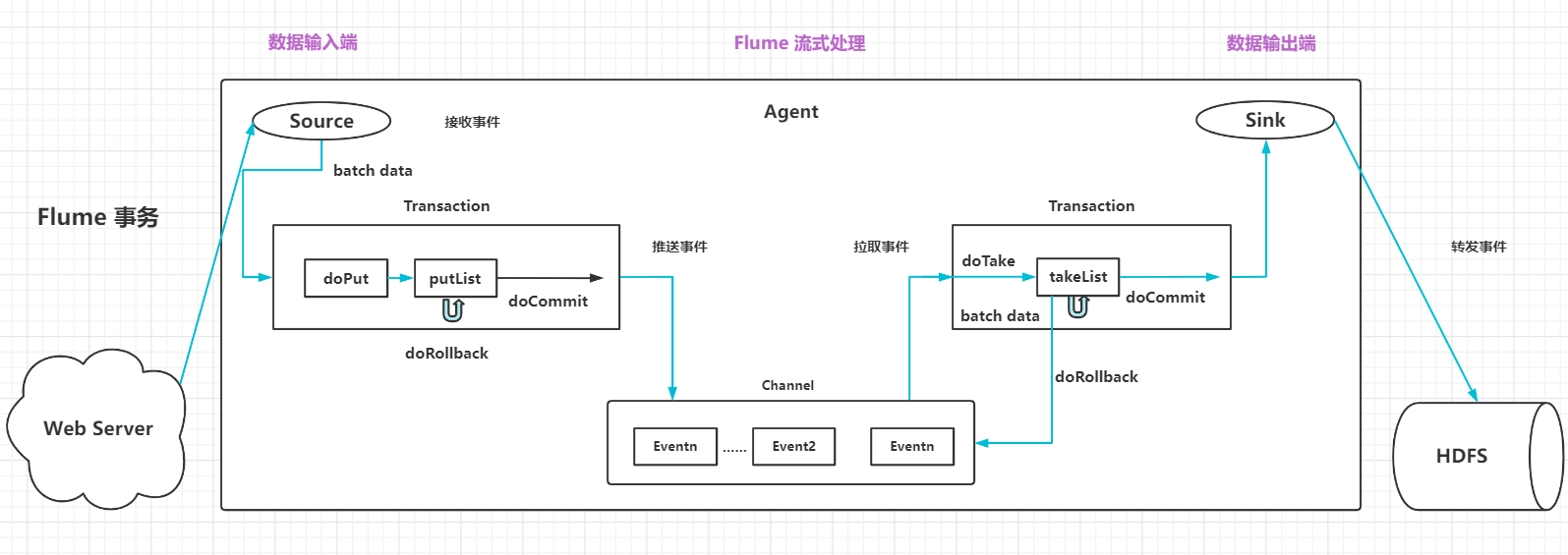
推送事务流程
- 1、
doPut: 把批数据写入到临时缓冲区putList - 2、
doCommit: 检查Channel容量是否足够,如果容量足够则把 putList 里的数据发送到 Channel - 3、
doRollBack: 如果Channel容量不够,则把数据回滚到 putList
拉取事务流程
- 1、
doTake: 把数据读取到临时缓冲区 takeList - 2、
doCommit: 检查数据是否发送成功,成功的话,则把event从takeList中移除 - 3、
doRollBack: 如果发送失败,则把 takeList的数据回滚数据到 Channel
可靠性
- 1、
只有当sink接收到,数据落地完成的信息之后,才会将数据从通道中删除 - 2、数据传输的方式
不是byte,而是一个个的 event
可恢复
- 1、当
数据丢失了,只有从存储在磁盘的方式,才能将数据找回
















 2429
2429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











