







目录
第1关 使用Flask进行数据库开发
ORM基础概念
ORM 全称Object Relational Mapping,中文意为对象-关系映射。其实它就是模型对象的概念把数据库的信息映射称一个个对象来操作。而不需要写 SQL 语句,简单来说就是面向对象编程。
Flask 中的 SQLAlchemy 就是一个 ORM 框架,它依赖于 pymysql,使用关系对象映射对数据库进行操作。
Flask数据库开发
安装依赖库
当我们使用 Flask 进行数据开发时,需要安装一些相应的依赖库,如果在自己电脑上测试的小伙伴一定不要忘记了(●'◡'●):
mysqlclient;flask_sqlalchemy;pymysql。
安装依赖库示例:pip install flask_sqlalchemy。
创建模型与表的映射
还是参照之前的数据库表,接下来我们进行模型的创建与表的映射。方便我们后续的开发学习。
连接数据库:
app = Flask(__name__)# 设置数据库连接app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:root@127.0.0.1:3306/flask_table'db = SQLAlchemy(app)
- 其中
SQLALCHEMY_DATABASE_URI表示数据库的连接地址,接下来是数据库引擎采用的格式:mysql://用户:密码@数据库地址:端口/数据库名; db对象是 SQLAlchemy 类的实例,表示程序使用的数据库,同时还获得了 Flask-SQLAlchemy 提供的所有功能。
创建模型与表的映射:
# 定义模型class user_Table(db.Model):# 表模型ID = db.Column(db.Integer,primary_key=True,autoincrement=True) # autoincrement 参数表示设置自动增量(自增长)User = db.Column(db.String(255))Email = db.Column(db.String(255))Password = db.Column(db.Integer)
__tablename__表示定义在数据库中使用的表名。如果没有定义,Flask-SQLAlchemy会使用一个默认名字;db.Column类构造函数的第一个参数是数据库列和模型属性的类型,具体如下所示。
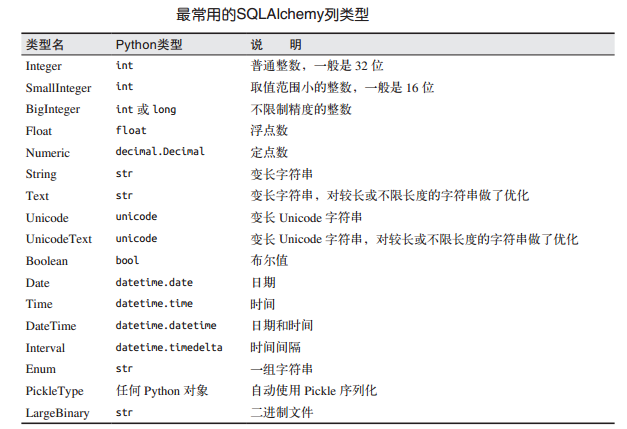
db.Column中其余的参数指定属性的可选项:

简单的数据库操作:
还没创建数据库的小伙伴一定要记得先创建相应的数据库,再进行接下来的操作!(●'◡'●)
db.create_all() # 根据模型类型创建表db.drop_all() # 删除之前创建过的表
如果数据库表已经存在,则db.create_all()不会重新创建或更新这个表。如果修改模型后要把改动应用到现有的数据库中,这一特性会带来不便。更新现有数据库表的粗暴方式是先删除旧表再重新创建。
编程要求
本关的编程任务是补全 begin-end 中的代码,要求实现在数据库中创建相应的表。具体要求如下:
- 数据库中已经存在不同模型创建的同名表,需要先进行删除;
- 根据以下表格字段格式,在 MySQL 数据库中创建相应的表(表名: entry_form);
| 字段名 | 字段类型 | 选项参数 |
|---|---|---|
| ID | Integer | 设置为主键、自动增量 |
| company_name (公司) | String | 不允许使用空值 |
| eduLevel_name (学历) | String | |
| Entry_time (入职时间) | Date | 默认值: 2019-01-01 |
| jobName (职位名称) | String | |
| salary (薪资) | Integer |
- 具体要求请参见后续测试样例。
请仔细阅读右侧代码编辑区内给出的代码框架,再开始你的编程工作!
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import datetime
import warnings
warnings.filterwarnings("ignore")
app = Flask(__name__)
# 请在此处添加代码,设置数据库连接
# 用户:root
# 密码:123123
# 连接地址:127.0.0.1
# 数据库:flask_table
#********** Begin *********#
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:123123@127.0.0.1:3306/flask_table'
db = SQLAlchemy(app)
#********** End **********#
# 定义模型
class entry_Form(db.Model):
# 请根据左侧表格字段格式完成模型的编写
# ********** Begin *********#
__tablename__='entry_form'
ID = db.Column(db.Integer,primary_key=True,autoincrement=True)
company_name = db.Column(db.String(255),nullable=False)
eduLevel_name = db.Column(db.String(255))
Entry_time = db.Column(db.Date,default=datetime.date(2019,1,1))
jobName = db.Column(db.String(255))
salary = db.Column(db.Integer)
# ********** End **********#
# 根据题目要求,请在此处此函数中添加代码,完成函数的编写
def createTable(self):
# ********** Begin *********#
# 删除原有数据库表
db.drop_all()
#根据模型类型创建表
db.create_all()
# ********** End **********#
第2关 查询操作
常用的查询操作
本关卡我们一起讨论如何使用 Flask 进行查询操作。Flask-SQLAlchemy 为每个模型提供了query对象。最基本的模型查询是取回对应表中的所有记录:
date.query.all()结果如下:[[1, '百度', '硕士', '2019-01-21', 'Java开发工程师', 10000], [2, '阿里', '硕士', '2019-05-21', 'Python开发工程师', 10000]]
使用过滤器可以配置query对象进行更精确的数据库查询
参考如下:
# filter接受的参数是一个类似于SQL表达式的值app.query.filter(entry_Form.ID>=2).all() # 使用符号进行进行过滤 > < <= >=结果如下:[[2, '阿里', '硕士', '2019-06-15', 'Java工程师', 10000], [3, '阿里', '博士', '2019-06-20', 'Java工程师', 100000]]# filter_by接受的参数是关键字参数app.query.filter_by(ID =2).all()结果如下:[[2, '阿里', '硕士', '2019-05-21', 'Python开发工程师', 10000]]相较于filter的表达式参数,filter_by里的关键词参数写起来更加简洁,但是它不能用>或者<这样的比较操作符了。
如下想查看 SQLAlchemy 为查询生成原生 SQL 查询语句,只需要把query对象转换成字符串:
str(app.query.filter_by(ID =2)结果如下:SELECT `entry_Form`.`ID` AS `entry_Form_ID`, `entry_Form`.company_name AS `entry_Form_company_name`, `entry_Form`.`eduLevel_name` AS `entry_Form_eduLevel_name`, `entry_Form`.`Entry_time` AS `entry_Form_Entry_time`, `entry_Form`.`jobName` AS `entry_Form_jobName`, `entry_Form`.salary AS `entry_Form_salary`FROM `entry_Form`WHERE `entry_Form`.`ID` = %s
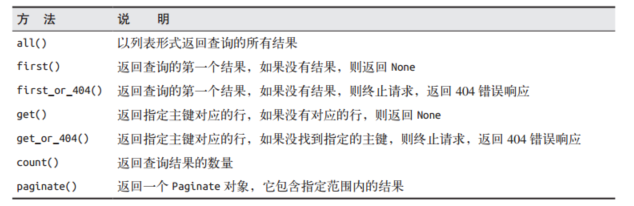
常用的 SQLAlchemy 查询过滤器:

在查询上指定过滤器后,通过调用all()执行查询,以列表的形式返回结果。除了all()之外,还有其他方法能触发查询执行。
编程要求
本关的编程任务是补全代码编辑区内 Begin-End 处的代码,要求实现数据库查询的功能。具体要求如下:
- 查询的表为第一关的
entry_form表,字段信息与其一致;
| 字段名 | 字段类型 | 选项参数 |
|---|---|---|
| ID | Integer | 设置为主键、自动增量 |
| company_name (公司) | String | 不允许使用空值 |
| eduLevel_name (学历) | String | |
| Entry_time (入职时间) | Date | 默认值: 2019-01-01 |
| jobName (职位名称) | String | |
| salary (薪资) | Integer |
- 查询公司名为 阿里巴巴 、学历为 硕士 、入职时间在 2019-6 月、薪资在 20000-25000 之间的全部数据;
- 具体要求请参见后续测试样例。
from task import entry_Form
class Test():
def select_Table(self):
# 请在此处填写代码,并根据左侧编程要求完成本关考核
# ********** Begin *********#
ap = entry_Form()
pro = ap.query.filter(entry_Form.company_name == "阿里", entry_Form.eduLevel_name == "硕士",
entry_Form.salary >= 20000, entry_Form.salary <= 25000,
entry_Form.Entry_time >= "2019-06").all()
return pro
# ********** End **********#
第3关 添加操作
任务描述
本关任务:学习本关卡的相关知识,掌握如何使用 SQLAlchemy,实现将文本文件中的数据插入到数据库相应的表格中。
相关知识
为了完成本关任务,你需要掌握:如何使用 SQLAlchemy 实现单条数据、多条数据的添加方式。
添加数据操作
在 Flask-SQLAlchemy 中,会话由db.session表示。准备把对象写入数据库之前,先要将其添加到会话中(参照第一关User表);
单条数据添加方式:
data1 = user_info(ID=1,name = "张三",Email='zhangsan@163.com',Password=123456)data2 = user_info(ID=2,name = "李四",Email='lisi@163.com',Password=654321)# 添加单条数据db.session.add(data1)db.session.add(data2)
或者也可以采用多条数据添加方式:
# 添加多条数据db.session.add_all([data1,data2])
为了把对象写入数据库,我们需要调用commit()方法提交会话:
db.session.commit()
会话提交完成后,将得到如下所示数据库表格:(表格已经创建,未提交任何数据后的结果)
ID | User | Email | Password |
|---|---|---|---|
1 | 张三 | zhangsan@163.com | 123456 |
2 | 李四 | lisi@163.com | 654321 |
补充知识:数据库会话能保证数据库的一致性,提交操作使用原子方式把会话中的对象全部写入数据库。如果在写入会话的过程中发生了错误, 整个会话都会失效。如果你始终把相关改动放在会话中提交,就能避免因部分更新导致的数据库不一致性。
数据库会话也可回滚。调用db.session.rollback()后,添加到数据库会话中的所有对象都会还原到它们在数据库时的状态。
编程要求
本关的编程任务是补全代码编辑区内给出的代码框架,要求实现将文本文件中的数据插入到数据库相应的表格中,在Begin-End区域内进行代码补充,具体要求如下:
- 将
csv文本文件中的数据插入到表名为entry_Form数据库表格中; - 读取
csv文件路径为data.csv; - 插入的数据库表为第一关的
entry_form表,字段信息与其一致,具体如下:
| 字段名 | 字段类型 | 选项参数 |
|---|---|---|
| ID | Integer | 设置为主键、自动增量 |
| company_name (公司) | String | 不允许使用空值 |
| eduLevel_name (学历) | String | |
| Entry_time (入职时间) | Date | 默认值: 2019-01-01 |
| jobName (职位名称) | String | |
| salary (薪资) | Integer |
- 具体要求请参见后续测试样例。
请仔细阅读代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关:
测试输入:无测试输入
预期输出(插入后查询的数据结果):
[1, '百度', '硕士', datetime.date(2019, 6, 20), 'Java工程师', 20000][2, '阿里', '博士', datetime.date(2019, 7, 4), 'Java工程师', 20000][3, '华为', '硕士', datetime.date(2019, 7, 5), 'Python工程师', 30000][4, '百度', '硕士', datetime.date(2019, 7, 24), 'Python工程师', 30000][5, '阿里', '硕士', datetime.date(2019, 6, 20), 'Python工程师', 30000][6, '阿里', '硕士', datetime.date(2019, 6, 20), 'Python工程师', 19000][7, '华为', '硕士', datetime.date(2019, 6, 20), 'Python工程师', 18000][8, '阿里', '硕士', datetime.date(2019, 6, 20), 'Java工程师', 25000][9, '阿里', '硕士', datetime.date(2019, 6, 5), 'Java工程师', 30000][10, '阿里', '硕士', datetime.date(2019, 6, 6), 'Java工程师', 22000][11, '阿里', '博士', datetime.date(2019, 6, 5), 'Java工程师', 30000][12, '阿里', '硕士', datetime.date(2019, 6, 6), 'Java工程师', 22000]
开始你的任务吧,祝你成功!
import pandas as pd
from task import db,entry_Form
class Message:
def update_table(self):
# 请根据左侧编程要求完成相应的代码填写
# 文件路径为"data.csv" 模型类 (已实现):entry_Form
# 数据库表已创建 只需要完成添加操作即可
# ********** Begin *********#
data = pd.read_csv(r"data.csv", encoding="utf8", sep="\t")
list = []
for index, row in data.iterrows():
user_info = entry_Form(ID = row['ID'],company_name=row['company_name'], eduLevel_name=row['eduLevel_name'],
Entry_time=row['Entry_time'], jobName=row['jobName'],
salary=row['salary'])
list.append(user_info)
# 添加多条数据
db.session.add_all(list)
# # db.session.add(data2)
db.session.commit()
#********** End **********#
第4关 删除操作
删除数据操作
数据库会话还有个delete()方法,下面例子把ID = 1的用户信息从数据库中删除:
# 取出需要删除的数据user_info = entry_Form()de = user_info.query.filter(entry_Form.ID ==2).first()# 删除数据db.session.delete(de)# 提交事务db.session.commit()
first()表示从过滤器中查询第一个用户信息(过滤器过滤后返回一个列表,但delete传入参数只能支持单个对象删除)。
那么,我们想删除多个对象如何实现呢?我们可以借助过滤器实现,具体实现方式如下:
# 通过过滤器实现多行删除user_info.query.filter(entry_Form.ID >1,entry_Form.ID<10).delete()db.session.commit()
如果我们突然有一天表数据需要清空,但表结构保留。实际删除中并不需要使用到过滤器,我们该怎么做呢?我们可以采用如下方式:
user_info.query.delete()db.session.commit()
编程要求
本关的编程任务是补全代码编辑区内给出的代码框架,要求实现删除功能,在Begin-End区域内进行代码填写,具体要求如下:
- 因华为公司研发部需要更加实现精细化管理,将研发部门一分为二,现数据库中数据已经实现迁移,需要将原表中职位为 Java 工程师和 Python 工程师实现批量删除;
- 参照以下表格字段格式,根据相关要求实现数据的批量删除(表名:
entry_form);
| 字段名 | 字段类型 | 选项参数 |
|---|---|---|
| ID | Integer | 设置为主键、自动增量 |
| company_name (公司) | String | 不允许使用空值 |
| eduLevel_name (学历) | String | |
| Entry_time (入职时间) | Date | 默认值: 2019-01-01 |
| jobName (职位名称) | String | |
| salary (薪资) | Integer |
- 具体要求请参见后续测试样例。
请仔细阅读代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关:
测试输入:无测试输入
预期输出(删除后表中查询的数据):
[1, '百度', '硕士', datetime.date(2019, 6, 20), 'Java工程师', 20000][2, '阿里', '博士', datetime.date(2019, 7, 4), 'Java工程师', 20000][4, '百度', '硕士', datetime.date(2019, 7, 24), 'Python工程师', 30000][5, '阿里', '硕士', datetime.date(2019, 6, 20), 'Python工程师', 30000][6, '阿里', '硕士', datetime.date(2019, 6, 20), 'Python工程师', 19000][8, '阿里', '硕士', datetime.date(2019, 6, 20), 'Java工程师', 25000][9, '阿里', '硕士', datetime.date(2019, 6, 5), 'Java工程师', 30000][10, '阿里', '硕士', datetime.date(2019, 6, 6), 'Java工程师', 22000][11, '阿里', '博士', datetime.date(2019, 6, 5), 'Java工程师', 30000][12, '阿里', '硕士', datetime.date(2019, 6, 6), 'Java工程师', 22000]
开始你的任务吧,祝你成功!
from operator import or_
from task import db,entry_Form
class Demo:
def del_col(self):
# 请在此处填写代码,根据左侧编程要求完成数据的批量删除
# ********** Begin *********#
user_info = entry_Form()
user_info.query.filter(entry_Form.company_name =="华为",or_(entry_Form.jobName =="Java工程师",entry_Form.jobName=="Python工程师")).delete()
db.session.commit()
# ********** End **********#
第5关 修改操作
修改数据操作
前面我们已经了解过什么是数据库会话了,其实在数据库会话上调用add()方法可以更新模型。我们继续之前会话进行操作,示例如下:
修改前表中数据:
| ID | User | Password | |
|---|---|---|---|
| 1 | 张三 | zhangsan@163.com | 123456 |
| 2 | 李四 | lisi@163.com | 654321 |
更新模型中数据:
# 首先查询到ID为1的这个用户>user1 = user_Table.query.filter_by(ID=1).first()# 赋值/修改 数据user1.Password = 789456# 提交db.session.commit()
修改后表中数据:
| ID | User | Password | |
|---|---|---|---|
| 1 | 张三 | zhangsan@163.com | 123456 |
| 2 | 李四 | lisi@163.com | 789456 |
注意:删除与插入和更新一样,提交数据库会话后才会执行。
编程要求
本关的编程任务是补全代码编辑区内给出的代码框架,要求实现在数据库中修改相应的表中的数据,请在Begin-End区域内进行代码填写,具体要哦求如下:
- 小张在华为公司表现优异,经相关部门审核批准,决定将小张的薪资调整至 30000 元,现已知其 ID 号为 10,作为数据管理员的你需要对小张的数据进行修改;
- 参照以下表格字段格式,根据相关要求实现表中数据的修改(表名:
entry_form);
| 字段名 | 字段类型 | 选项参数 |
|---|---|---|
ID | Integer | 设置为主键、自动增量 |
company_name(公司) | String | 不允许使用空值 |
eduLevel_name(学历) | String | |
Entry_time(入职时间) | Date | 默认值:2019-01-01 |
jobName(职位名称) | String | |
salary(薪资) | Integer |
- 具体要求请参见后续测试样例。
请仔细阅读代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关:
测试输入(数据库表中原始数据):
[1, '百度', '硕士', '2019-06-20', 'Java工程师', 20000][2, '阿里', '博士', '2019-07-04', 'Java工程师', 20000][4, '百度', '硕士', '2019-07-24', 'Python工程师', 30000][5, '阿里', '硕士', '2019-06-20', 'Python工程师', 30000][6, '阿里', '硕士', '2019-06-20', 'Python工程师', 19000][8, '阿里', '硕士', '2019-06-20', 'Java工程师', 25000][9, '阿里', '硕士', '2019-06-05', 'Java工程师', 30000][10, '阿里', '硕士', '2019-06-06', 'Java工程师', 25000][11, '阿里', '博士', '2019-06-05', 'Java工程师', 30000][12, '阿里', '硕士', '2019-06-06', 'Java工程师', 22000]
预期输出(更新数据后查询的数据):
[1, '百度', '硕士', '2019-06-20', 'Java工程师', 20000][2, '阿里', '博士', '2019-07-04', 'Java工程师', 20000][4, '百度', '硕士', '2019-07-24', 'Python工程师', 30000][5, '阿里', '硕士', '2019-06-20', 'Python工程师', 30000][6, '阿里', '硕士', '2019-06-20', 'Python工程师', 19000][8, '阿里', '硕士', '2019-06-20', 'Java工程师', 25000][9, '阿里', '硕士', '2019-06-05', 'Java工程师', 30000][10, '阿里', '硕士', '2019-06-06', 'Java工程师', 30000][11, '阿里', '博士', '2019-06-05', 'Java工程师', 30000][12, '阿里', '硕士', '2019-06-06', 'Java工程师', 22000]
开始你的任务吧,祝你成功!
from task import db,entry_Form
class Demo:
# 更新数据函数
def update_Date(self):
# 根据左侧相关知识,完成相关代码实现
# ********* Begin *********#
user = entry_Form.query.filter_by(ID=10).first()
user.salary = 30000
db.session.commit()
# ********* End *********#
















 4917
4917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











