







文章目录
🌟 零基础也能搞定!使用 Langchain + Ollama 构建本地知识库系统详解
🎯 应用场景
痛点场景:
某制造企业仓库管理员每天需要处理上百次物料查询请求,面对散落在多个Excel中的库存数据,每次查询都需要10分钟以上,且容易出错…
适合对象:
希望在局域网/本地环境下部署智能问答系统的人群(比如公司内部知识管理、物料库存查询等应用场景)
解决方案:
通过本地化部署的智能问答系统,实现:
- ✅ 自然语言提问秒级响应
- ✅ 数据100%本地存储
- ✅ 无需GPU等高端硬件
- ✅ 支持离线环境运行
本地大模型的优势
很多人以为做 AI 一定得上云,其实不是!在很多业务里,本地部署才是王道,比如:
- 不想数据上传云端,怕泄密 ✅
- 网络条件有限或敏感场景 ✅
- 小规模团队不想付费 API,节省成本 ✅
于是,我们有了主角 —— Langchain + Ollama + Chroma 向量数据库。
🛠️ 技术栈全景图
| 组件 | 作用 | 选型理由 |
|---|---|---|
| LangChain | AI应用开发框架 | 标准化流程,快速搭建AI链 |
| Ollama | 本地大模型引擎 | 支持多种开源模型,CPU即可运行 |
| Chroma | 向量数据库 | 轻量级,支持持久化存储 |
| BGE-M3 | 文本嵌入模型 | 中文表现优异,支持多语言 |
🧩 核心模块拆解
模块1:数据预处理
你的数据长这样吗?
["A001", "螺钉", "M5*20", "12345678", "PLM001", 100, "仓库A"],
原始数据为JSON格式
...
]
这是典型的结构化物料数据。我们希望把它变成 LLM 能理解的文本。
来看下关键函数:
```python
class Chatollama_base3:
def create_documents_from_txt(self, file_path):
"""
将原始物料数据转化为LangChain文档对象
:param file_path: 数据文件路径
:return: Document对象列表
处理逻辑:
1. 读取JSON格式的物料数据
2. 结构化拼接字段(编码+名称+规格+...)
3. 生成带元数据的文档对象
"""
# 示例数据转换
["M001", "螺钉", "M6", "TW001", 1000]
→
"编码:M001, 名称:螺钉, 规格:M6, 库存:1000"
documents = []
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
data_list = json.loads(content)
for item in data_list:
if isinstance(item, list) and len(item) >= 2:
material_name = item[0]
page_content = (
f"编码:{item[0]},"
f"名称:{item[1]},"
f"规格:{item[2] if len(item) > 2 else ''},"
f"图文号:{item[3] if len(item) > 3 else ''},"
f"PLM码:{item[4] if len(item) > 4 else ''},"
f"数量:{item[5] if len(item) > 5 else ''},"
f"仓库:{item[-1] if item else ''}"
)
metadata = {"source": material_name}
doc_id = str(uuid.uuid4()) # 生成唯一的 UUID 作为 id
document = Document(page_content=page_content, metadata=metadata, id=doc_id)
documents.append(document)
else:
print(f"跳过无效数据项: {item}")
except FileNotFoundError:
print(f"错误: 文件未找到: {file_path}")
except json.JSONDecodeError:
print(f"错误: 文件内容不是有效的 JSON 格式。请检查文件格式是否正确。")
return documents
技术细节:
- 使用UUID生成唯一文档ID,避免重复
- 元数据记录物料编码,便于溯源
- 结构化拼接提升检索准确率
每条物料信息都被转换成一段规范化的文本,形如:
Document(id='0ef27170-6d73-4908-8984-6eae11af413e', metadata={'source': '01070692'}, page_content='编码:01070692,名称:内六角圆柱头螺钉,规格:M20*60 8.8镀锌 GB/T70.1,图文号:GB/T70.1,PLM码:00D01M20x60G031,数量:14.0,仓库:紧固件仓')
这一步就是知识的原始表达转换
模块2:向量化引擎
def load_embedding_model(self):
embeddings = OllamaEmbeddings(
model="bge-m3",
# base_url="http://localhost:11434" # 本地模型服务
)
return embeddings
为什么选择BGE-M3:
- 专为中文优化的嵌入模型
- 支持多向量混合检索
- 在MTEB中文榜排名前列
模块3:向量数据库
def store_chroma(self, docs, persist_directory="chroma3"):
db = Chroma.from_documents(
documents=docs,
embedding=self.embeddings,
persist_directory=persist_directory
)
return db
Chroma特性:
- 数据持久化存储(重启不丢失)
- 支持相似度阈值过滤
- 自动管理向量索引
模块4:问答系统核心
def get_qa(self):
QA_CHAIN_PROMPT = PromptTemplate.from_template("""
Human:
你是一位专业的物料管家,请根据上下文回答:
{context}
要求:
1. 以表格呈现关键字段
2. 添加库存状态分析
3. 给出管理建议
问题:{question}
Assistant:
""")
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.45}
)
return RetrievalQA.from_chain_type(
llm=self.llm,
retriever=retriever,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
为什么我们要写提示词?
- 强调 AI 的角色(物料管理助手)
- 限定回答格式(表格 + 数据解读 + 提醒)
- 避免模型瞎猜,提升可控性
📌 建议:
写 Prompt 时,不要只告诉模型你是谁,还要告诉它怎么做(输出格式、用不用单位、是否给总结建议)
Prompt设计精髓:
- 角色定位 → 专业物料管家
- 格式规范 → 强制表格输出
- 业务规则 → 库存分析+建议
- 安全边际 → 限定回答范围
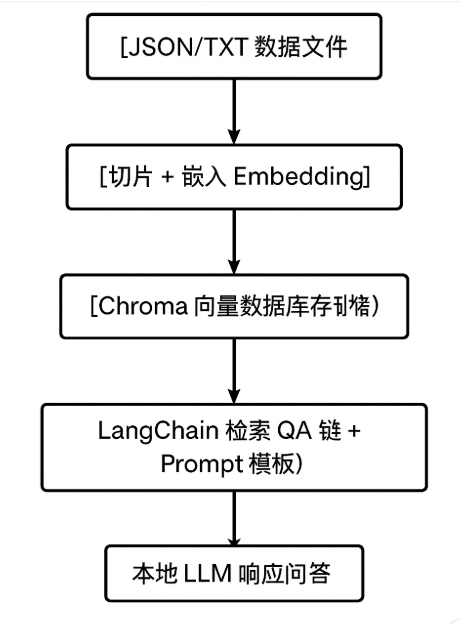
🧱 系统架构
[JSON/TXT 数据文件]
↓
[切片 + 嵌入 Embedding]
↓
[Chroma 向量数据库存储]
↓
[LangChain 检索 QA链 + Prompt模板]
↓
[本地 LLM 响应问答]

🚀 完整工作流程
- 数据初始化阶段
- 查询响应阶段
💻 实战演示
场景:查询特定物料库存
# 初始化系统
manager = Chatollama_base3()
# 自然语言提问
question = "请列出A仓库所有规格为M6的螺钉类物料,并按库存量降序排列"
# 获取智能回复
result = manager.query_material(question)
输出结果示例
【智能回复】
根据A仓库库存数据,规格为M6的螺钉物料如下:
| 物料编码 | 名称 | 规格 | 库存量 | 最低库存 |
|----------|------------|------|--------|----------|
| M006 | 内六角螺钉 | M6 | 1500 | 500 |
| M012 | 平头螺钉 | M6 | 800 | 300 |
库存分析:
1. 内六角螺钉库存充足(300%安全库存)
2. 平头螺钉接近安全库存线,建议15日内补货
【数据溯源】
- 物料编码:M006
- 物料编码:M012
🛠 调优技巧
检索优化
retriever = db.as_retriever(
search_kwargs={
'k': 5, # 返回Top5结果
'score_threshold': 0.4, # 相似度阈值
'filter': {'仓库': 'A仓'} # 元数据过滤
}
)
模型参数配置
ChatOllama(
model="qwen2.5:latest",
temperature=0.1, # 降低随机性
num_predict=1024, # 响应长度限制
top_p=0.9 # 聚焦高概率token
)
⚠️ 常见问题排查
-
中文乱码问题
- 确保所有文件操作指定编码:
open(..., encoding='utf-8') - 检查系统默认编码:
import sys; print(sys.getdefaultencoding())
- 确保所有文件操作指定编码:
-
Ollama服务异常
# 启动服务命令 ollama serve # 常用模型列表 ollama list # 安装中文模型 ollama pull qwen:7b -
向量检索不准确
- 检查字段拼接逻辑是否丢失关键信息
- 调整相似度阈值(0.3-0.6范围调试)
- 尝试混合检索模式(MMR)
📈 拓展应用
本方案稍作修改即可应用于:
- 企业内部知识库(HR政策、技术文档等)
- 生产质检标准查询系统
- 客户服务智能问答
- 个人知识管理(论文/笔记检索)
结语:让AI在本地生根发芽
通过本文,我们完成了从原始数据到智能问答系统的蜕变。这个本地化方案不仅解决了数据隐私的担忧,更展现了开源生态的强大能力。当最后一个代码块运行成功时,您已经为传统仓库管理装上了AI引擎。
技术发展的真谛,不在于追求最前沿,而在于用合适的技术解决实际问题。 希望这个方案能成为您AI应用开发的起跑线,期待看到更多精彩的本地化AI实践!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









