






文章目录
《从JSON到知识库:用Python自动化拆分TXT格式JSON为LangChain可用的结构化DOCX文档》
第一部分:代码整体架构
该代码主要实现三大功能:
- 读取TXT格式的JSON数据
- 结构化数据转换
- 批量生成标准DOCX文档
采用模块化设计,包含:
- 数据读取模块(read_json_data)
- 文档生成模块(create_word_document)
- 主控流程(main)
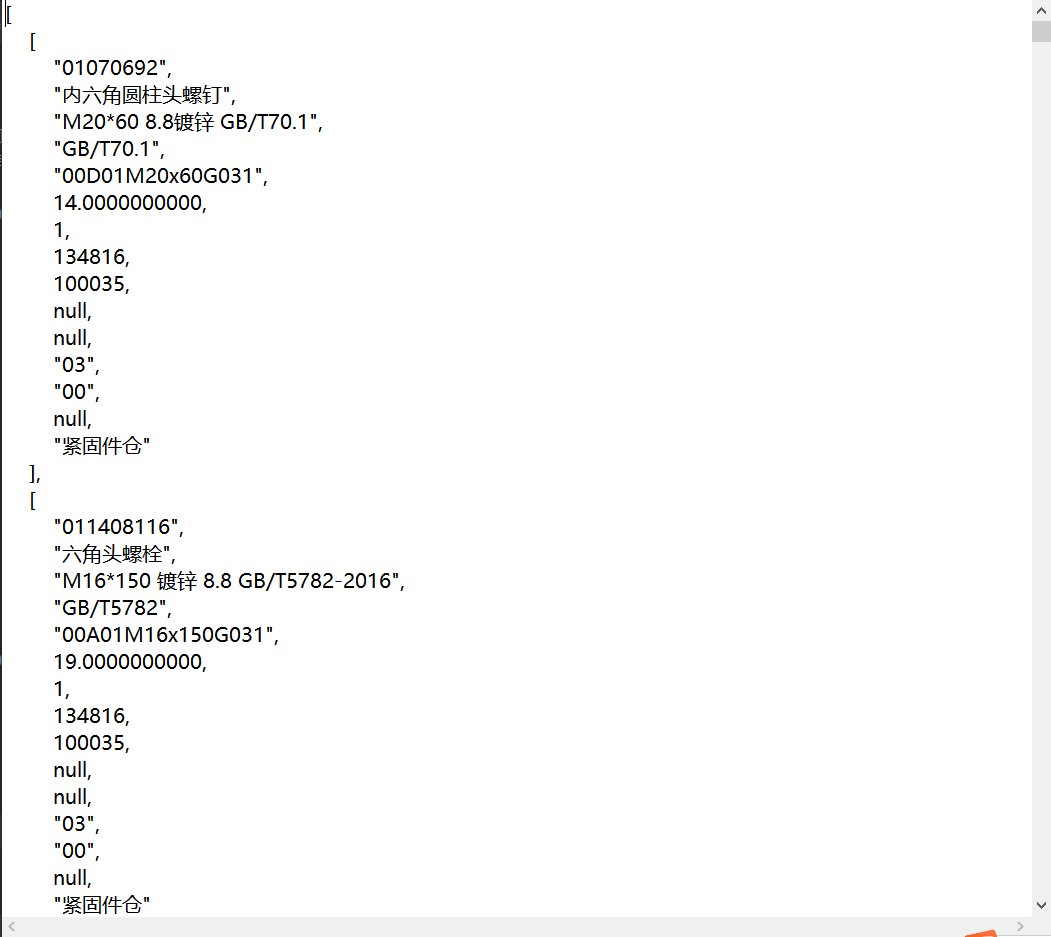
原始数据(JOSN格式):
第二部分:核心代码详解
1. 数据读取模块
def read_json_data(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
try:
return json.loads(content)
except json.JSONDecodeError:
print("JSON解析错误,请检查文件格式是否正确")
return None
- 关键点解析:
- 使用
utf-8编码应对中文内容 json.loads()直接解析字符串内容- 异常捕获机制避免程序崩溃
- 使用
2. 文档生成模块
def create_word_document(item, output_folder):
# 数据校验与默认值处理
code = item[0] or "未知编码"
name = item[1] if len(item) > 1 and item[1] else "未知名称"
# 文件名生成策略
file_name = f"编码:{code},名称:{name},规格:{spec}..." # 完整参数拼接
file_name = file_name.replace('/', '_').replace('\\', '_')[:180] # 安全处理
# 文档格式设置
doc = Document()
content = doc.add_paragraph()
content_run = content.add_run(content_text)
content_run.font.size = Pt(12) # 标准字号
- 核心设计:
- 防御性编程处理数据缺失
- Windows系统文件名规范处理
- 固定字号保证文档一致性
3. 主控流程
def main():
current_dir = os.path.dirname(os.path.abspath(__file__))
output_folder = os.path.join(current_dir, "生成的Word文档_1")
# 创建带序号的新目录
counter = 1
while os.path.exists(output_folder):
output_folder = f"生成的Word文档_{counter}"
counter += 1
- 亮点改进:
- 自动检测并创建带版本号的输出目录
- 进度显示功能(处理第X/Y条数据)
- 相对路径处理保证跨平台兼容性
生成的Word文档:
第三部分:LangChain集成建议
最佳实践方案:
-
文档预处理:
from langchain.document_loaders import Docx2txtLoader loader = Docx2txtLoader("生成的Word文档_1/编码XXX.docx") documents = loader.load() -
知识库构建:
from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import FAISS embeddings = HuggingFaceEmbeddings() knowledge_base = FAISS.from_documents(documents, embeddings) -
检索优化技巧:
- 在文件名中加入关键字段(如编码、规格等)
- 保持单个文档内容简洁(当前实现刚好满足)
- 添加元数据字段(可扩展代码实现)
第四部分:潜在问题与改进
当前版本注意事项:
-
数据校验:
- 建议添加
if len(item) < 6:的详细错误日志 - 可增加字段类型验证(如quantity应为数值型)
- 建议添加
-
性能优化:
# 批量处理时可添加 if i % 100 == 0: print(f"已完成 {i}/{total_items} 条处理") -
扩展建议:
# 可添加的元数据字段 metadata = { "source": file_name, "create_time": datetime.now().isoformat() }
总结
通过本方案生成的标准化DOCX文档,配合LangChain的文档加载器,可以快速构建出包含丰富元数据的本地知识库。这种结构化处理方式相比直接使用原始JSON数据,在检索准确率和可解释性上都有显著提升。后续可结合自动化流水线,实现从数据更新到知识库重建的全流程无人化运维。
配套资源推荐:
-
安装依赖清单:
pip install python-docx langchain faiss-cpu huggingface_hub -
示例文件结构:
├── json.txt ├── split_json_to_docx.py └── 生成的Word文档/ ├── A.docx └── B.docx -
测试数据集建议:
- 包含200-500条数据的样本集
- 故意设置缺失字段的测试用例
- 包含特殊字符的边界用例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









