







利用pandas.read_html()直接读取网页中的表格数据
read_html() 函数是最简单的爬虫,可以爬取静态网页表格数据。
但只适合于爬取 table 表格型数据
- 首先分析pandas.read_html() 函数的参数
import pandas as pd
df=pd.read_html()
# 常用的参数
io:url、html文本、本地文件等
header:标题行
flavor:解析器
skiprows:跳过的行
attrs:属性,例如:attrs = {'id':'table'}
parse_dates:解析日期
# 注意:返回的结果是DataFrame组成的list
## 需要最后加上一个索引[0]
- 当网页中含有多个表格时
选取百度百科中的世界500强企业表格为例
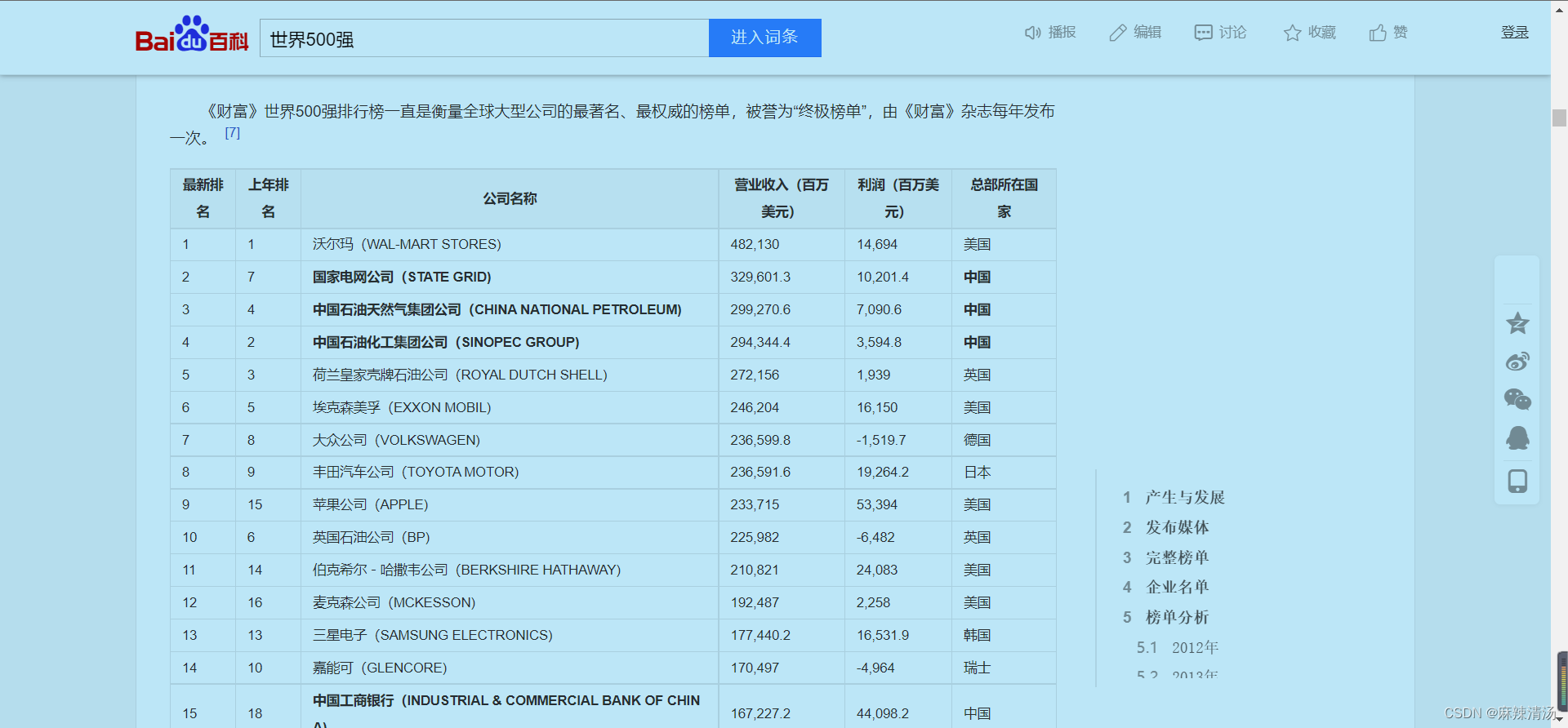
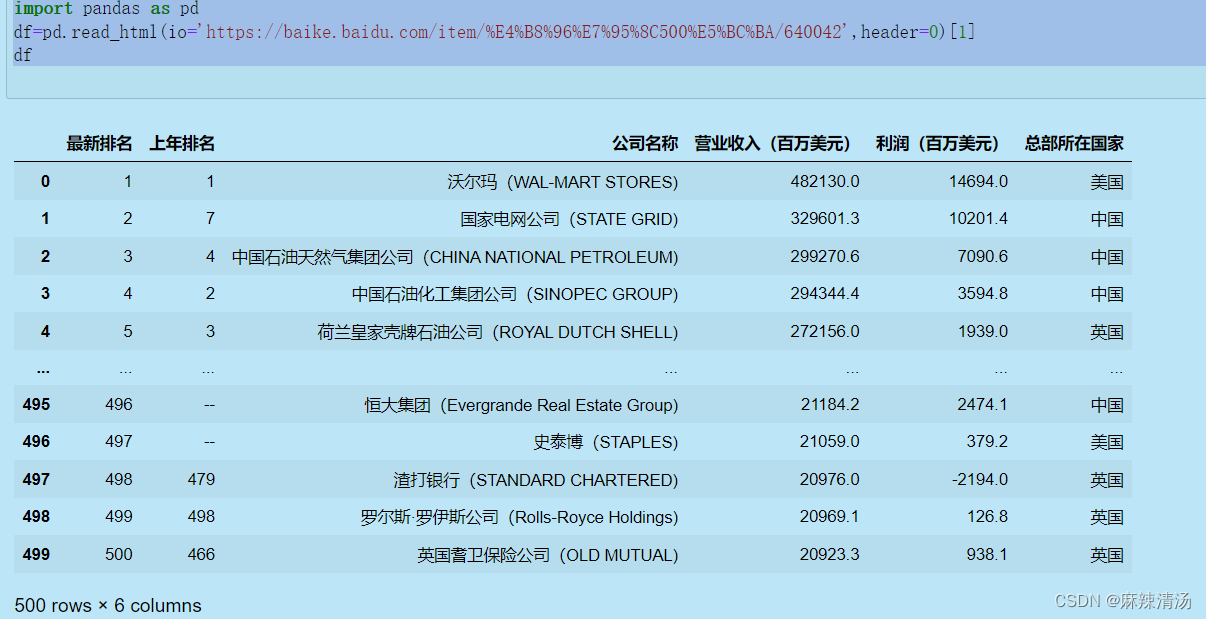
import pandas as pd
df=pd.read_html(io='https://baike.baidu.com/item/%E4%B8%96%E7%95%8C500%E5%BC%BA/640042',header=0)[1]
#因为该网页有多个表格,pd.read_html()生成的该网页内所有表格的list属性
#需要用索引来确定需要提取的表格
df
成果图展现:
- 网页内需要翻页的表格
- 比如:http://eid.csrc.gov.cn/ipo/1017/index.html
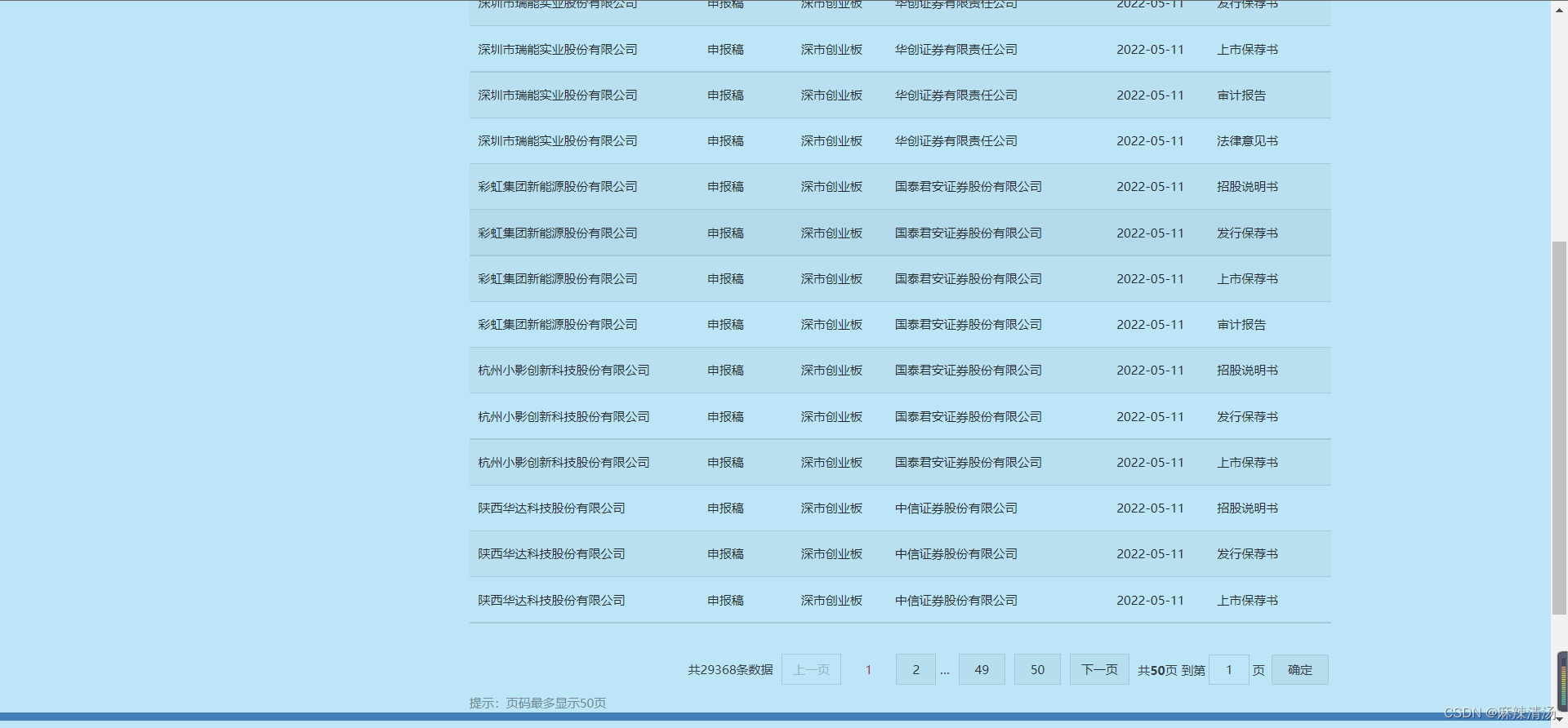
# 导入所需要用到的库
df = pd.DataFrame()
for i in range(1,5):
url3 =f"http://eid.csrc.gov.cn/ipo/1017/index_{i}.html"
print(url3)
#可加utf-8,如果乱码
#数据合并
df = pd.concat([df, pd.read_html(url3,header=0)[0]]) # 爬取+合并DataFrame



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









