







BOSS直聘岗位python爬取(完整代码+详细介绍)
- 本文仅介绍关键思路,后续对字段的爬取文章到链接:
- 爬取字段:详情链接、岗位名、岗位年限、岗位薪资范围、职位描述、岗位关键字、岗位地区、岗位地址
- 爬取工具:Python
- 所需第三方库:selenium,BeautifulSoup,json
- !! 注意selenium必须要提前安装和浏览器版本一样的驱动器(本人在这步卡了好久,具体请看链接:)
- 思路:(这样分段有利于中途报错不需要所有都重新跑)
- 先利用selenium获取每个岗位的链接
- 再遍历页面的链接获取每个岗位招聘信息的源代码
- 再利用beautifulSoup对每个岗位的源代码进行分析获取字段。
- 爬取内容:boss直聘对岗位最多只开放10页,所以我们最多只能爬取10页的岗位,如有其他解决办法欢迎在下方留言
需要源码的关注公众号: 一个不是小白的数据小白
后续对字段的爬取代码进入
博文:https://blog.csdn.net/weixin_52001949/article/details/135480669

一、 首先安装指定库文件
- windows按win键直接输入anaconda Prompt
- 然后打开直接复制以下代码,安装库文件
pip install selenium
pip install BeautifulSoup
pip install json
pip install time
二、 获得cookie文件
利用selenium获取指定cookie
- 在进入网页之后手动扫码登录(这样最快),设置了time.sleep(15),意思是等待15s
from selenium import webdriver
import time
import json
def 获取cookie(url,cookie文件名):
#1. 打开浏览器
driver = webdriver.Chrome()
#2. 进入网页
driver.get(url)
#3. 进入网页之后,手动点击登录页码快速登录进去
time.sleep(15)
#4.在15s之内登录,获取所有cookie信息(返回是字典)
dictCookies = driver.get_cookies()
#5.是将dict转化成str格式
jsonCookies = json.dumps(dictCookies)
# 登录完成后,自动创建一个boss直聘.json的文件,将cookies保存到该环境根目录下
with open(cookie文件名, "w") as fp:
fp.write(jsonCookies)
print('cookies保存成功!')
url='https://www.zhipin.com/web/geek/job-recommend'
获取cookie(url,cookie文件名='boss直聘.json')
三、获取每个岗位详情的链接
- 查看每个页面的链接
https://www.zhipin.com/web/geek/job?query=bi&city=101210100&page=1
https://www.zhipin.com/web/geek/job?query=bi&city=101210100&page=2
依次类推遍历每个链接
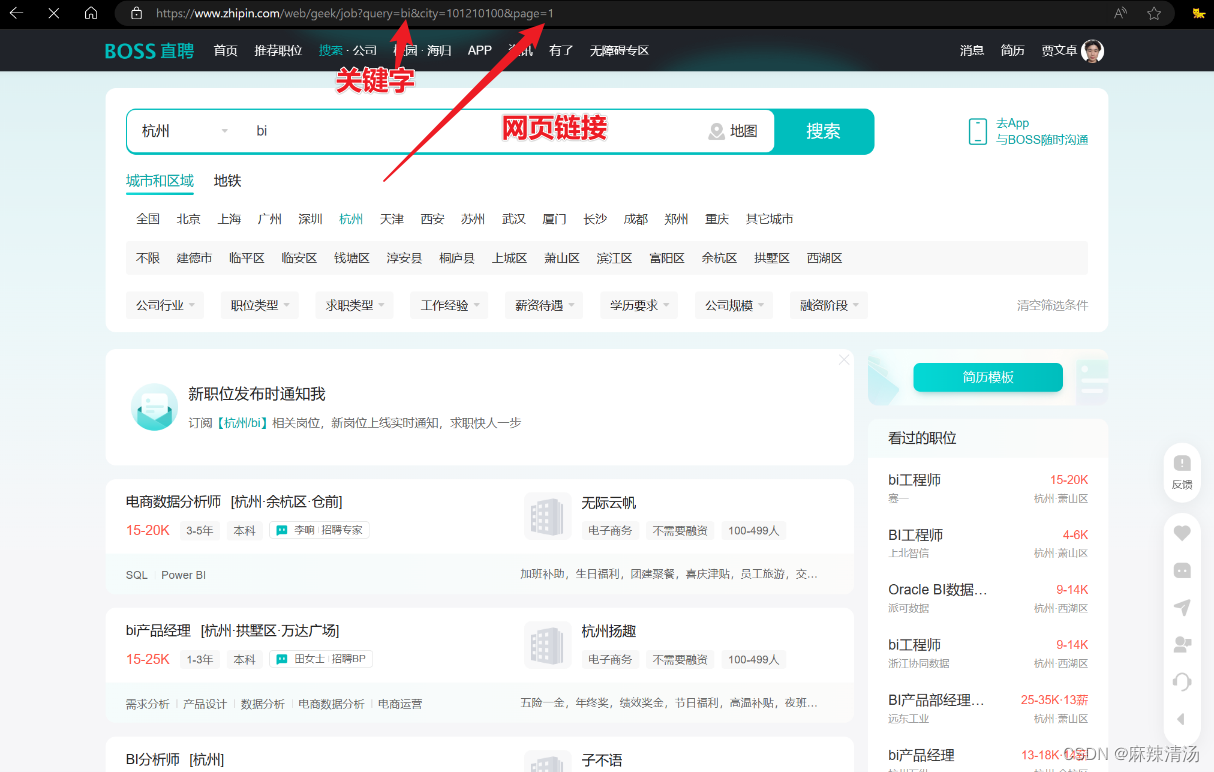
- 获取每个岗位的链接
-
- 找到链接在源代码里的位置,看到每个链接:
-href= “job_detail/fc617e27bdeb1f581Hd729–FlZR.html?lid=aThHvPnPLRe.search.1&securityId=qB9QmXRG637rI-C1O4eOujVwuJyQAFng5ryLPqak83VjpKskQM0S_BvMqHfwzTk3913NcAIyPJdop63oDcung_hoNkHrnZizG-3kgAvSvFHZo7MioJIkk4pCazN-oH1XO2sJXNpP29g~&sessionId=”
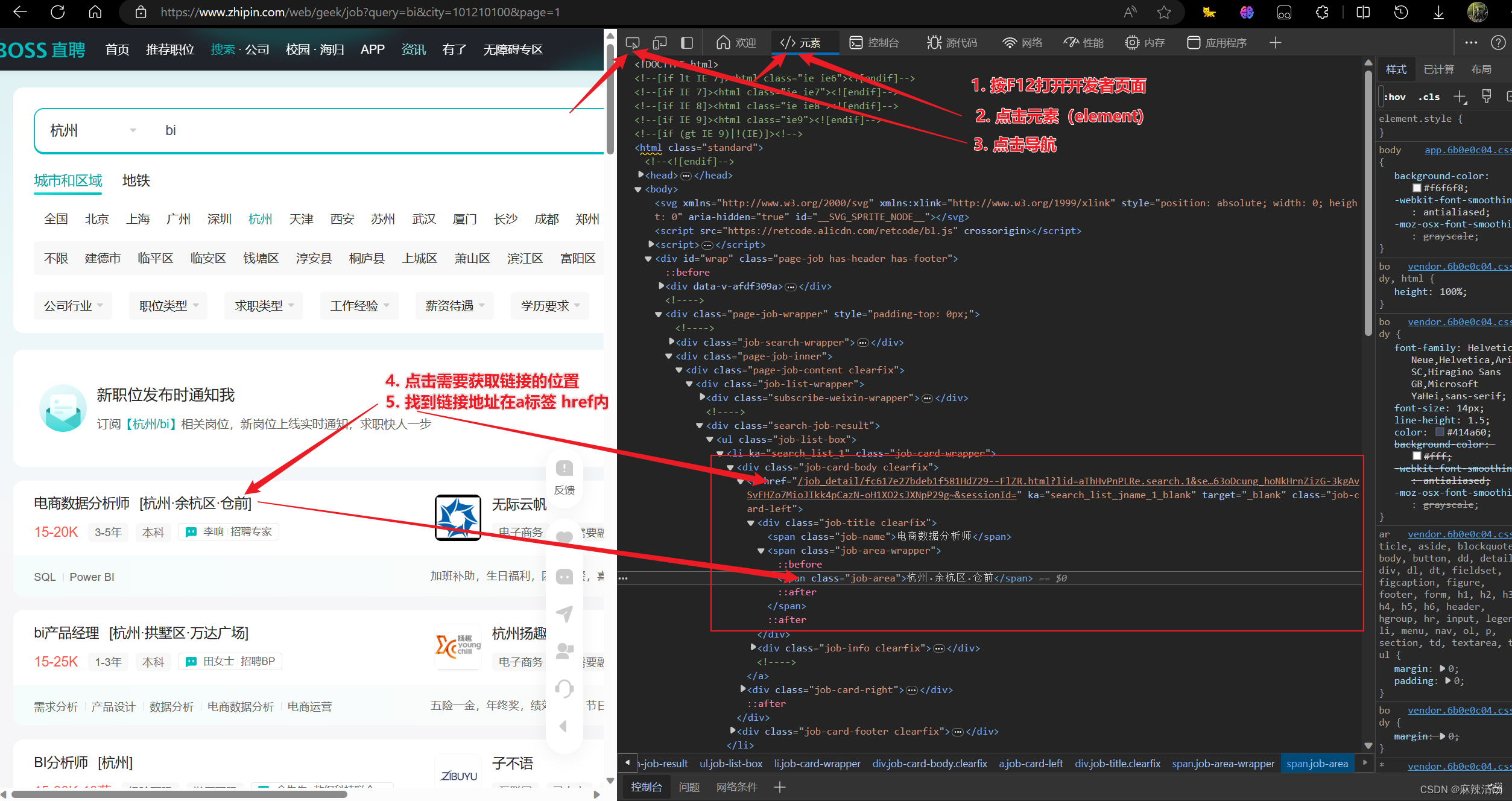
- 找到链接在源代码里的位置,看到每个链接:
-
- 分析链接所在位置,发现链接所在a标签下的class=‘job-card-left’,ctrl+f查找下该页面存在多少个这个class的a标签,一共有30个这种链接,说明页面一共有30个岗位信息链接,且一个标签里就有一个链接。
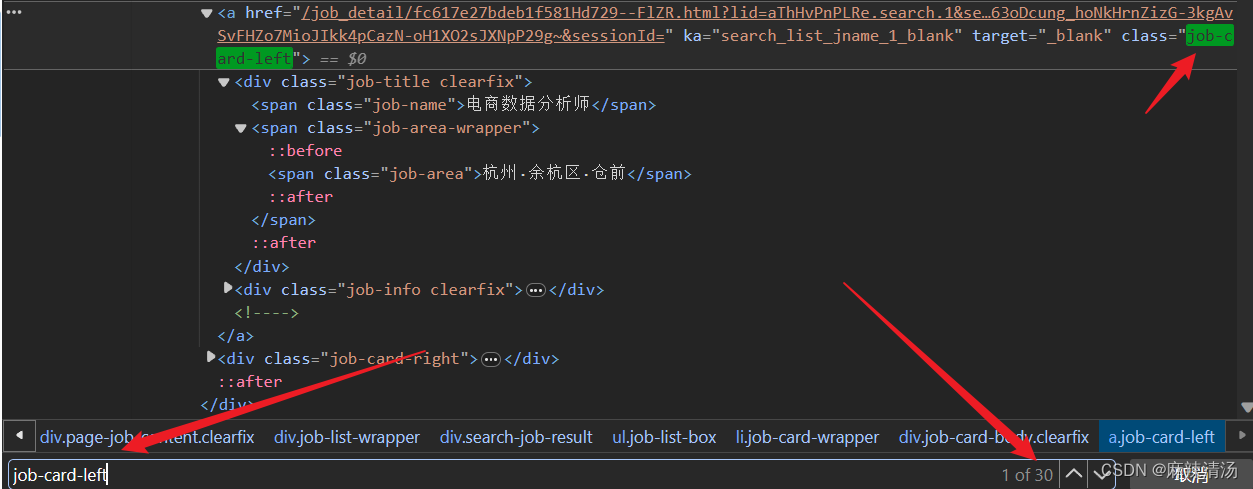
- 分析链接所在位置,发现链接所在a标签下的class=‘job-card-left’,ctrl+f查找下该页面存在多少个这个class的a标签,一共有30个这种链接,说明页面一共有30个岗位信息链接,且一个标签里就有一个链接。
-
- 利用beatifulsoup对源代码进行链接的爬取
soup.find_all(class_='job-card-left')
#获取所有class=job_card_left_elements'的标签

-遍历每个元素,取出href链接
for element in job_card_left_elements:
href = element['href']
full_link = 'https://www.zhipin.com' + href
'将每个链接放到一个空列表里'
详情列表.append(full_link)
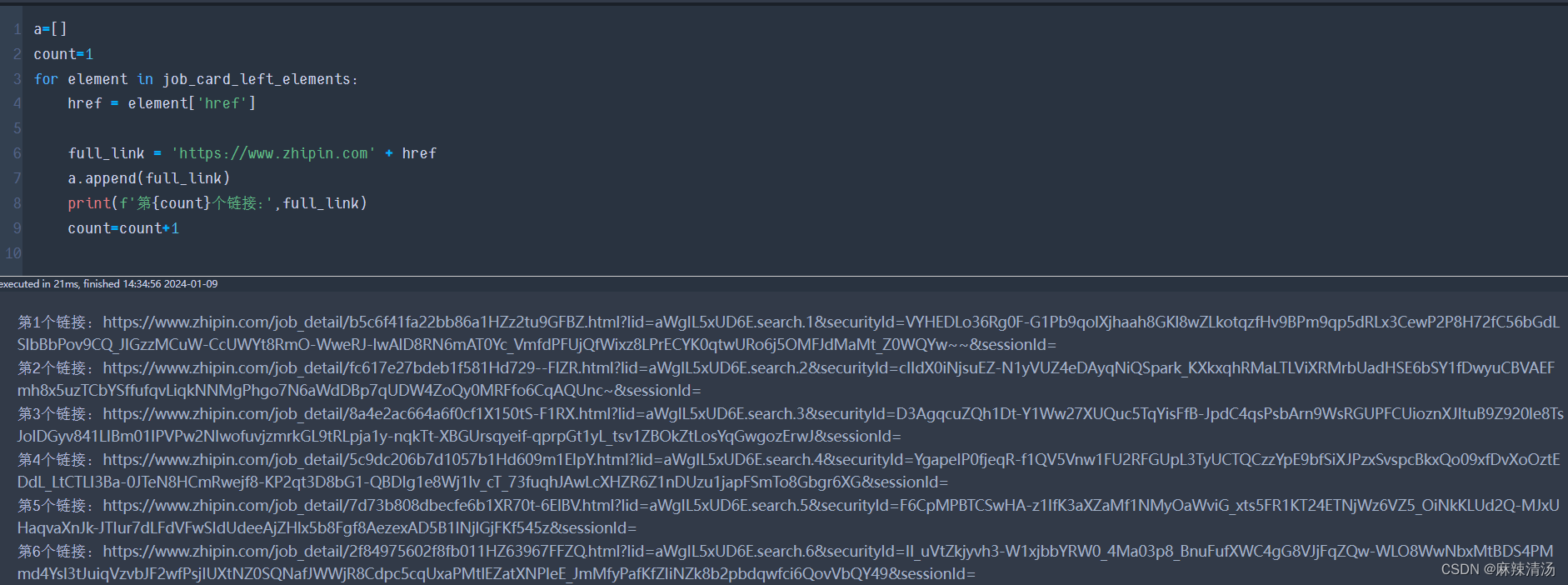
该部分完整代码
代码解释:
```python
from selenium import webdriver
import time
import json
from bs4 import BeautifulSoup
'1. 建立一个空列表存储链接'
详情列表=[]
'2. 遍历每个页面,获取页面的源代码'
for i in range (1,11):
print(i)
boss = webdriver.Chrome()
# 1.打开网页
url =f'https://www.zhipin.com/web/geek/job?query=bi&city=101210100&page={i}'
boss.get(url)
#2.注入cookie
with open(r"E:\Anacada__\工作项目\爬虫\boss直聘.json", "r") as fp:
jsonCookies = fp.read()
#3. 将 JSON 格式的 Cookie 转换为字典
cookies = json.loads(jsonCookies)
#4.添加 Cookie 到 WebDriver 对象
for cookie in cookies:
boss.add_cookie(cookie)
#5.进入网页等待6s加载,然后获取源代码
boss.get(url)
time.sleep(6)
boss_text = boss.page_source
'3. 根据页面源代码,获取每个页面的岗位链接'
#1.将源代码加载进beatifulsoup
soup = BeautifulSoup(boss_text, 'html.parser')
#2.查找所有 class="job-card-left" 的元素
job_card_left_elements = soup.find_all(class_='job-card-left')
# 遍历每个元素,获取 <a> 标签的 href 链接
for element in job_card_left_elements:
href = element['href']
full_link = 'https://www.zhipin.com' + href
详情列表.append(full_link)
四、获取每个详情链接的源代码
- 获取了每个页面的链接了之后,就可以遍历访问每个链接了
- 这里先获取每个链接的源代码是为了避免中途出错,selenium访问浏览器速度有限,10个页面300个链接需要访问300次,源代码获取了之后再获取字段信息会很快。
- selenium获取源代码
count=0
源代码=[]
for i in 详情列表:
count=count+1
boss = webdriver.Chrome()
# 打开网页
url =f'{i}'
boss.get(url)
#2.注入cookie
with open(r"E:\Anacada__\工作项目\爬虫\boss直聘.json", "r") as fp:
jsonCookies = fp.read()
'1. 将 JSON 格式的 Cookie 转换为字典'
cookies = json.loads(jsonCookies)
' # 添加 Cookie 到 WebDriver 对象'
for cookie in cookies:
boss.add_cookie(cookie)
boss.get(url)
time.sleep(5)
boss_text = boss.page_source
源代码.append(boss_text)
五、获取网页源代码的完整代码:
from selenium import webdriver
import time
import json
import random
from bs4 import BeautifulSoup
import pandas as pd
def 获取cookie(url,cookie文件名):
driver = webdriver.Chrome()
driver.get(url)
time.sleep(15)
dictCookies = driver.get_cookies() #获得所有cookie信息(返回是字典)
jsonCookies = json.dumps(dictCookies) #dumps是将dict转化成str格式
# 登录完成后,将cookies保存到本地文件
with open(cookie文件名, "w") as fp:
fp.write(jsonCookies)
print('cookies保存成功!')
获取cookie('https://www.zhipin.com/web/geek/job-recommend',cookie文件名='boss直聘.json')
详情列表=[]
for i in range (1,11):
print(i)
boss = webdriver.Chrome()
# 打开网页
url =f'https://www.zhipin.com/web/geek/job?query=bi&city=101210100&page={i}'
boss.get(url)
#2.注入cookie
with open(r"E:\Anacada__\工作项目\爬虫\boss直聘.json", "r") as fp:
jsonCookies = fp.read()
# 将 JSON 格式的 Cookie 转换为字典
cookies = json.loads(jsonCookies)
# 添加 Cookie 到 WebDriver 对象
for cookie in cookies:
boss.add_cookie(cookie)
boss.get(url)
time.sleep(6)
boss_text = boss.page_source
# print("2. 获取页面源代码")
from bs4 import BeautifulSoup
soup = BeautifulSoup(boss_text, 'html.parser')
# 查找所有 class="job-card-left" 的元素
job_card_left_elements = soup.find_all(class_='job-card-left')
# 遍历每个元素,获取 <a> 标签的 href 链接
for element in job_card_left_elements:
href = element['href']
full_link = 'https://www.zhipin.com' + href
详情列表.append(full_link)
count=0
源代码=[]
for i in 详情列表:
count=count+1
boss = webdriver.Chrome()
# 打开网页
url =f'{i}'
boss.get(url)
#2.注入cookie
with open(r"E:\Anacada__\工作项目\爬虫\boss直聘.json", "r") as fp:
jsonCookies = fp.read()
'1. 将 JSON 格式的 Cookie 转换为字典'
cookies = json.loads(jsonCookies)
' # 添加 Cookie 到 WebDriver 对象'
for cookie in cookies:
boss.add_cookie(cookie)
boss.get(url)
time.sleep(random.uniform(5,15))
boss_text = boss.page_source
源代码.append(boss_text)
六、分析页面详情,获取对应字段
- 需要获取的字段
岗位名、岗位薪资、地区、工作地址、要求年限、学历、职位描述、岗位职责
公司名、公司规模、公司介绍、公司成立日期、行业
后续对字段的爬取代码进入
博文:https://blog.csdn.net/weixin_52001949/article/details/135480669
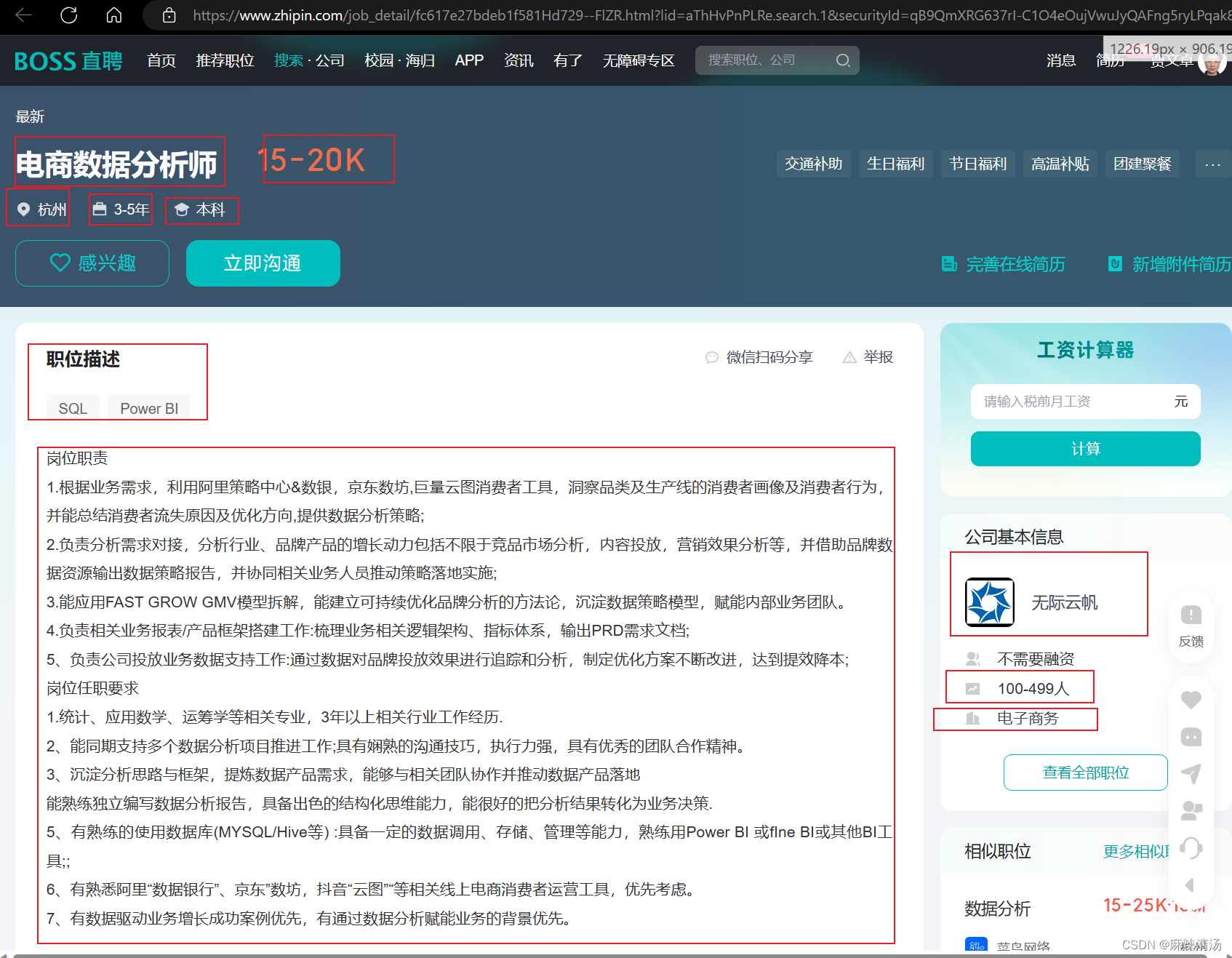
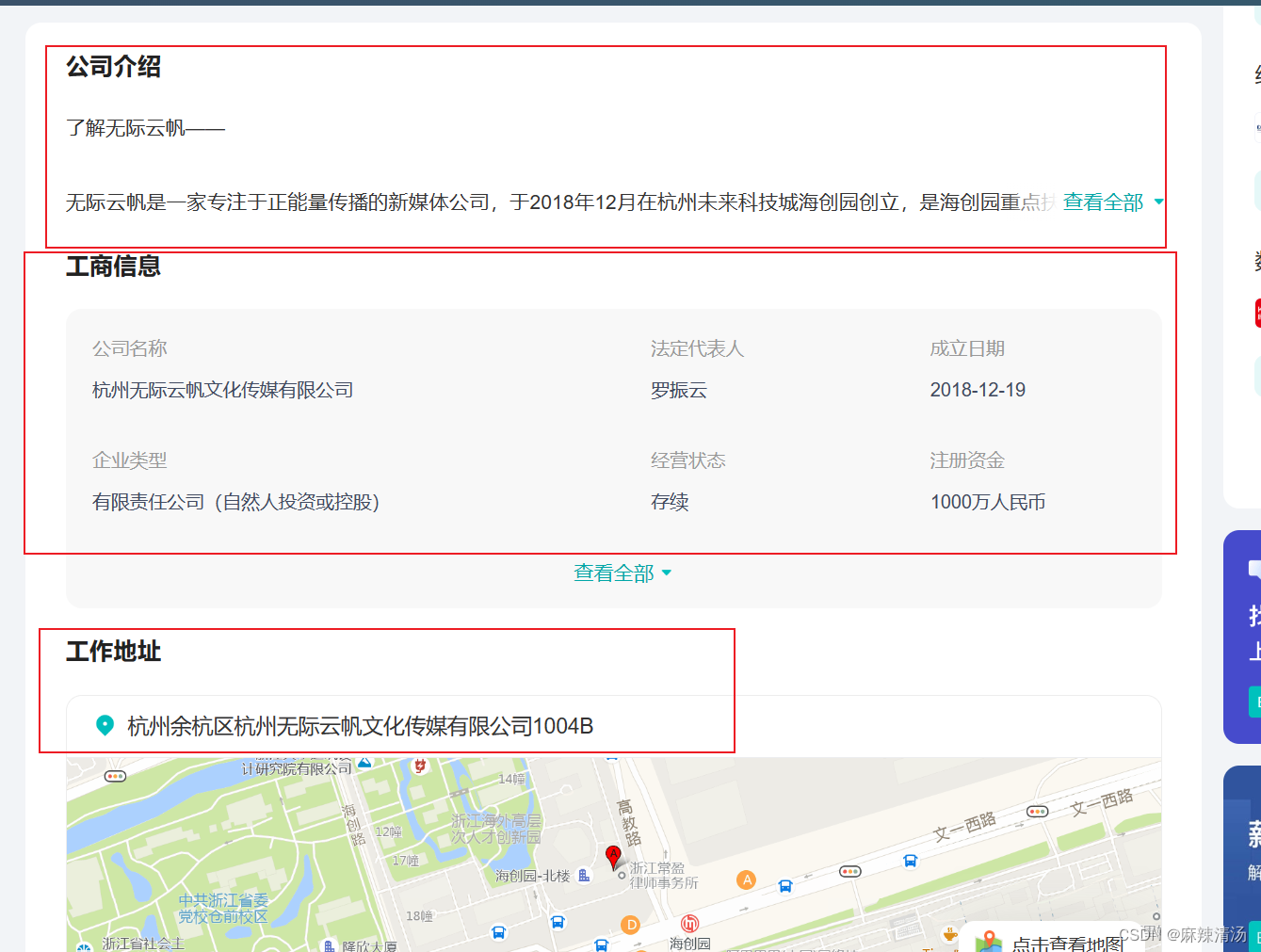
代码架构说明
- 配置好招聘的要求之后
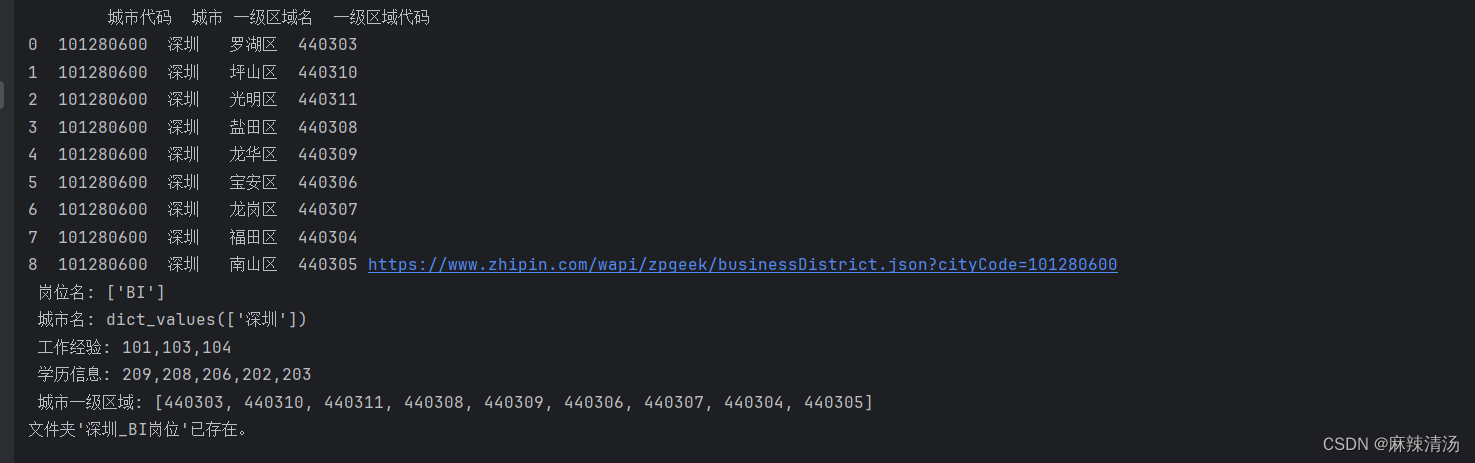
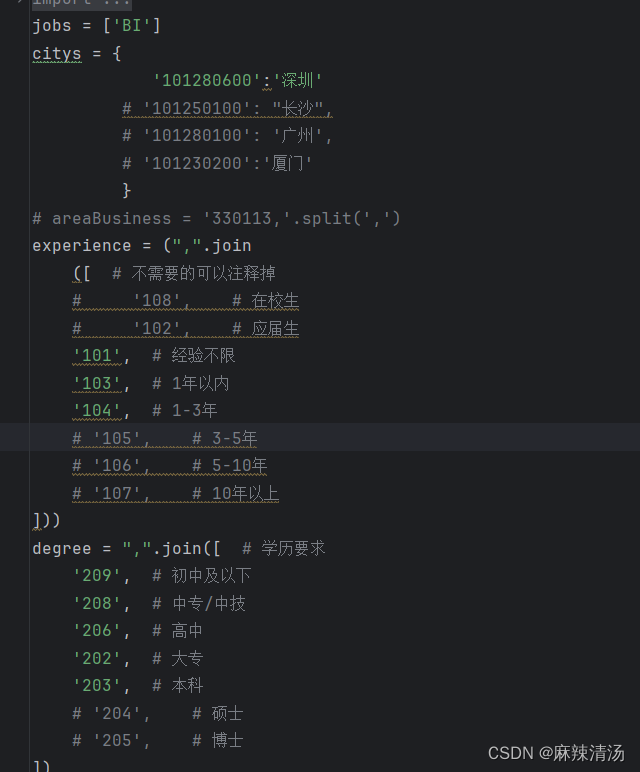
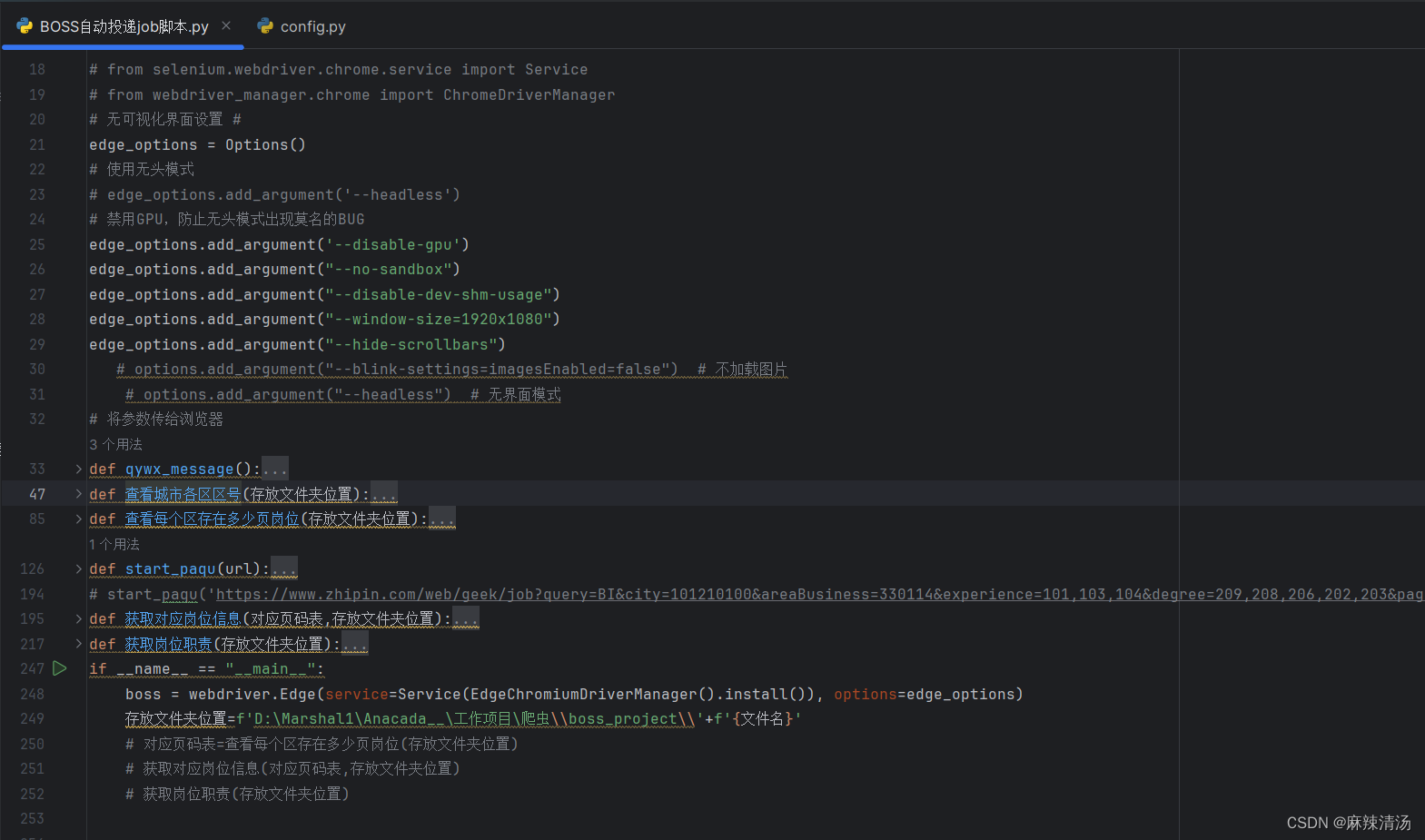
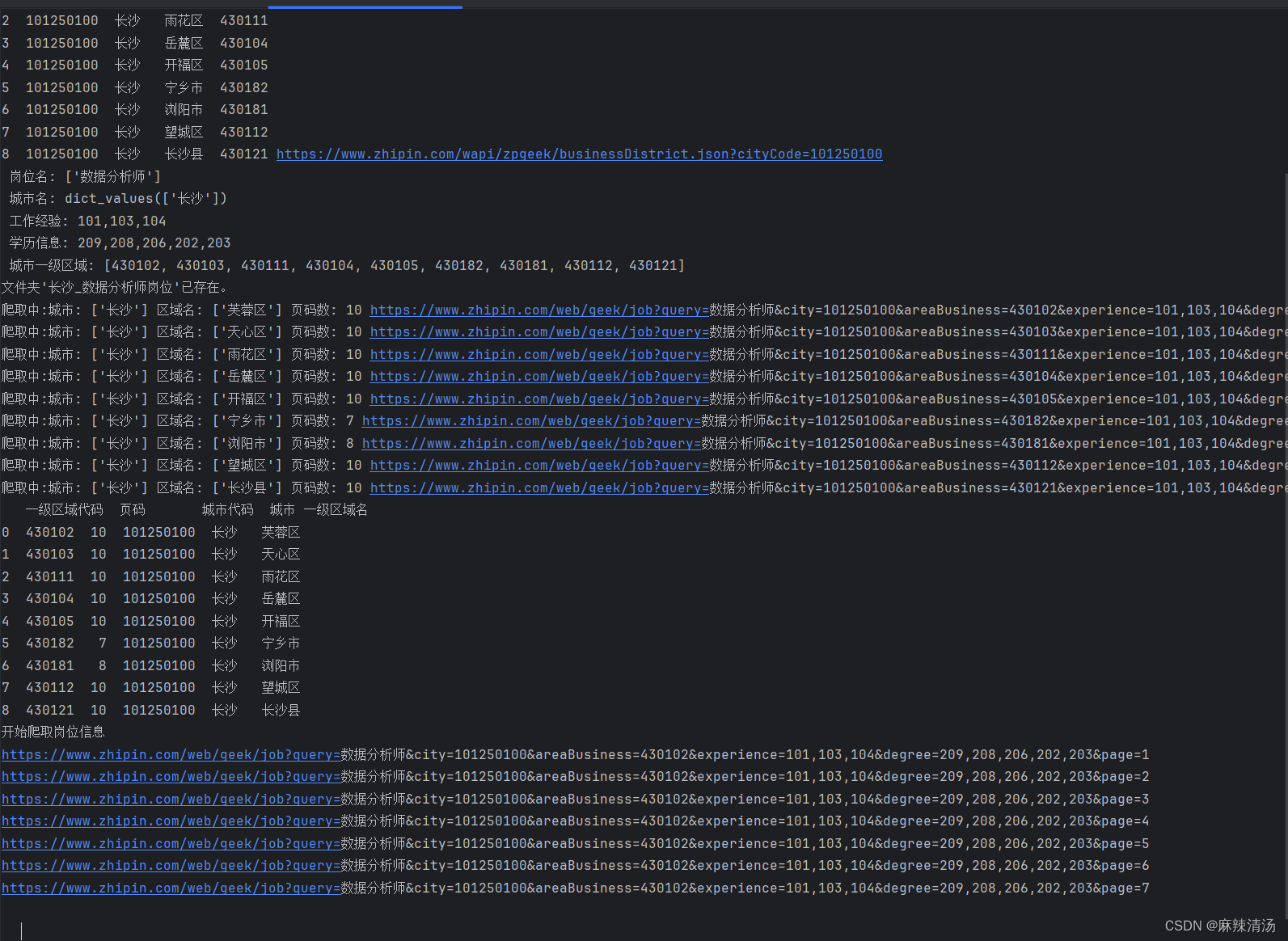
- 选定不同功能来爬取数据


















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









