







首先,上URL地址:aHR0cDovL3d3dy5oaXpqLm5ldDo4MDA4L3dlYlNpdGVfcHVibGlzaC9EZWZhdWx0LmFzcHg/YWN0aW9uPUNvbnN0cnVjdGlvbkxpY2VuY2UvdWNMaXN0
首先抓包网页:
发现第一次请求是get方式并不需要携带参数
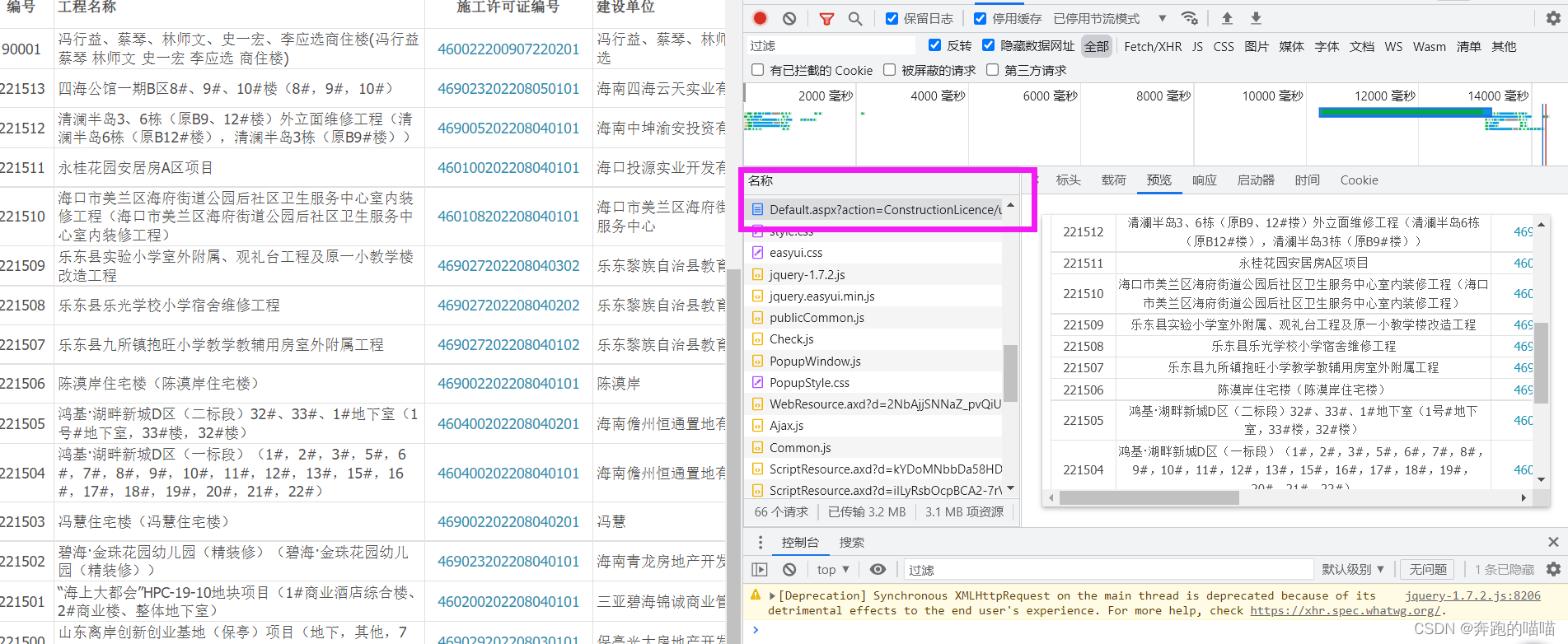
发现需要的标题数据都在这个网页上,再进一步进行翻页:
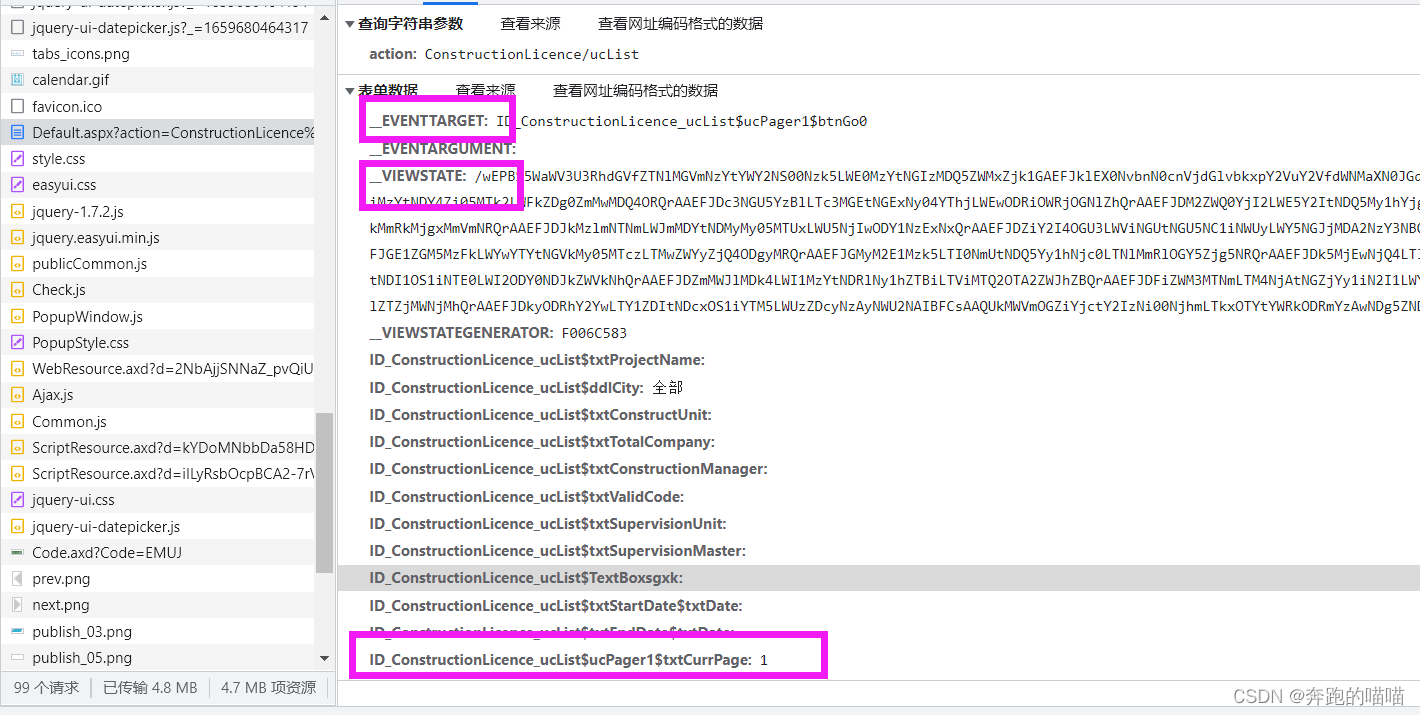
翻页请求变成了post请求,并发现这三个参数都会跟随翻页时候改变,参数对应关系分别是:
- ID_ConstructionLicence_ucList$ucPager1$txtCurrPage: 页码
- __VIEWSTATE:翻页所携带的必要参数
- __EVENTTARGET:暂时不知道有啥具体的作用
所以继续翻页,以便查看规律,当翻页到第5页__EVENTTARGET变化为 ID_ConstructionLicence_ucList$ucPager1$btnNext
直接点第1页页码时候,__EVENTTARGET变化为 ID_ConstructionLicence_ucList$ucPager1$btnFirst
当你以为__EVENTTARGET参数用来控制翻页的时候,那你就踩到了坑里,这里正确的做法应该是直接使用跳转页码,在跳转输入需要跳转的页码时,发现每次回车都会是第一页,并不能成功跳转页面,这里我的具体操作是,要用鼠标点击确定后才能正确跳转页码

这里注意,一定要点确定,才会发现真正实现翻页的具体参数:
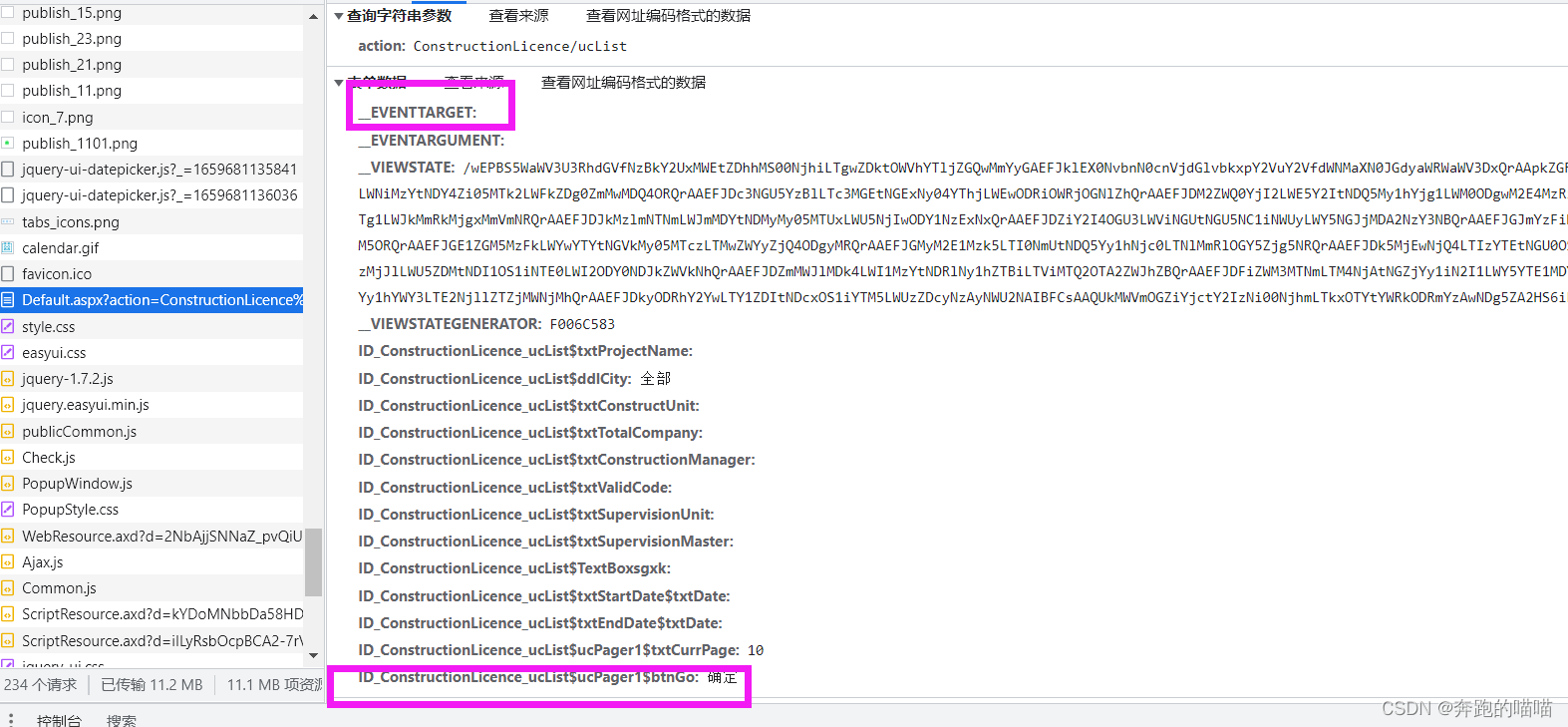
此时可以发现,from_data里面多了参数: ID_ConstructionLicence_ucList$ucPager1$btnGo: 确定
这个参数才是实现随意翻页的重要参数。
然后,需要解决参数__VIEWSTATE,看起来一长串的参数像是加密数据,可是并不是,经过对比发现,这个参数其实是在第一次get请求的时候网页源码所携带的参数数据,然后翻页的时候是上一页里面携带的参数数据
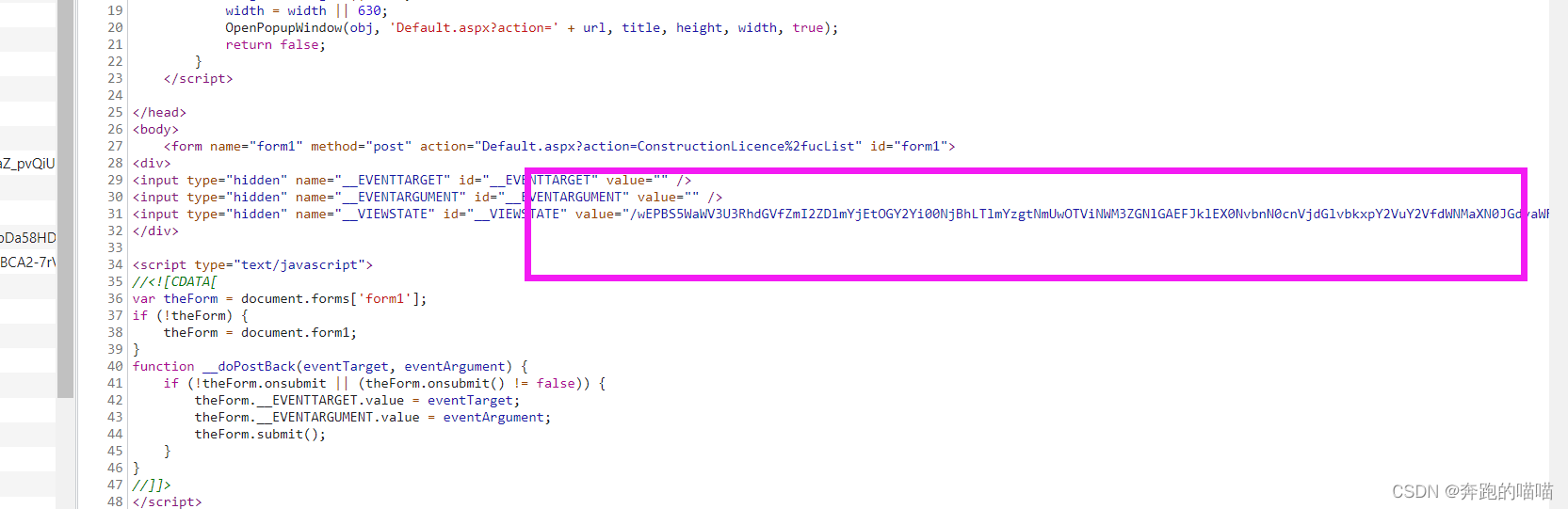
所以大致思路是:
第一次get请求,拿到__VIEWSTATE参数数据
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
session = requests.session()
event_data = get_event(headers, session)
get_page(headers, event_data, session)
def get_event(headers, session):
start_url = 'xxxxxx'
start_1 = session.get(start_url, headers=headers).text
event_data = \
re.findall(r'<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="(.*?)" />', start_1, re.S)[0]
print(event_data)
return event_data返回数据,并传参给下一个函数调用实现翻页:
def get_page(headers, event_data, session):
start_url = 'xxxxx'
page_1 = 17 # 起始页码
end_page = 50 # 结束页码
for i in range(page_1, end_page+1):
from_data = {
'__VIEWSTATE': event_data,
'__VIEWSTATEGENERATOR': 'F006C583',
'ID_ConstructionLicence_ucList$ddlCity': '全部',
'ID_ConstructionLicence_ucList$ucPager1$txtCurrPage': str(i),
'ID_ConstructionLicence_ucList$ucPager1$btnGo':'确定'
}
print('开始爬取第{}页'.format(i))
# print(from_data['__VIEWSTATE'])
page_req = session.post(start_url, data=from_data, headers=headers).text
event_data = re.findall(r'<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="(.*?)" />', page_req, re.S)[0]
guid_list = re.findall(r'ActDatumBase_Guid=(.*?)\',\'.*?\',\d+,\d+\);', page_req, re.S)
print(guid_list)
name_list = re.findall(r'<span id="ID_ConstructionLicence_ucList_gridView_ctl0\d_lblUnitEngineeringName">(.*?)</span>', page_req, re.S)
print(name_list)这里需要注意的是,需要使用session请求,使用requests请求的时候会导致翻页不成功!
需要请求的数据都在二级页面里,再来看看二级页面的参数:
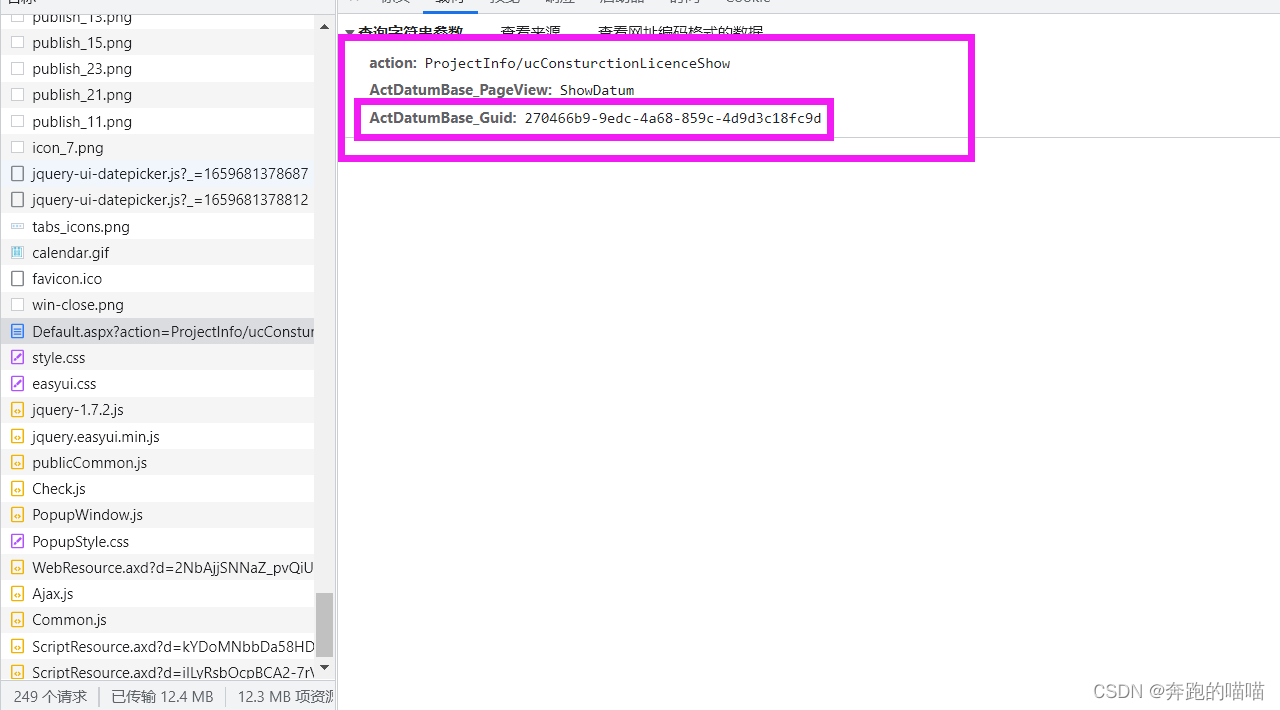
这几个参数里面只有ActDatumBase_Guid是改变的,其他的可以写死不变,guid的提取则是在网页源码里面,通过正则可以轻松提取
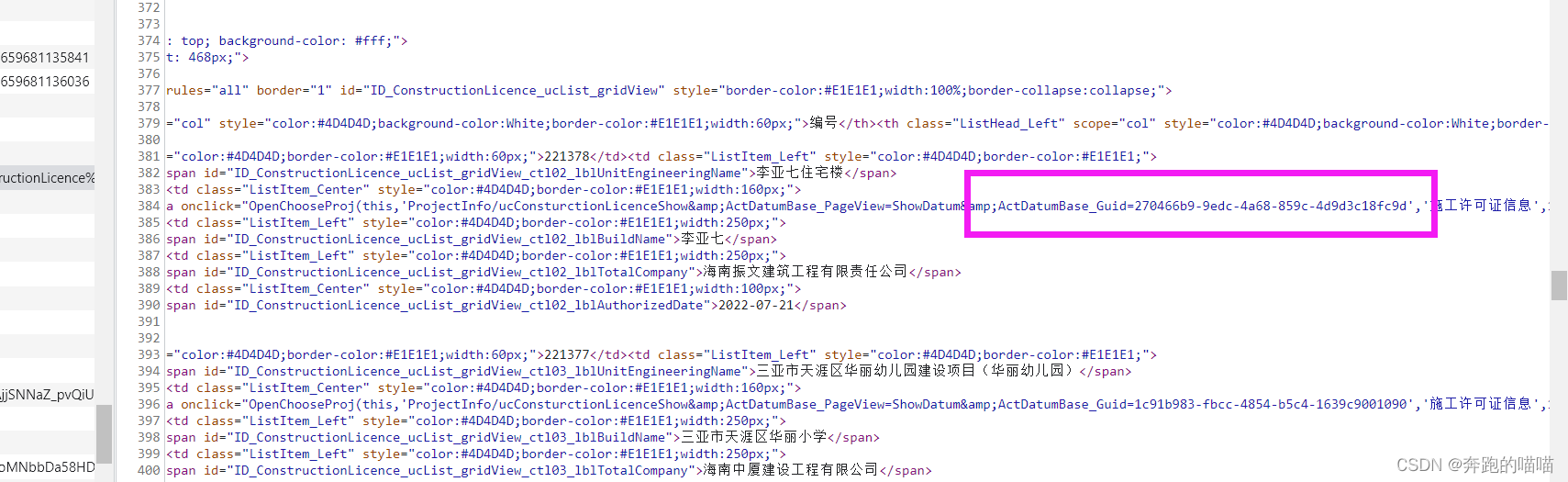
就是提取网页源码里面这部分guid参数请求二级页面就可以了。
下面附上翻页源码,二级页面的请求和解析你们自己写吧,哈哈:
# -*- coding: utf-8 -*-
import requests
import re
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
session = requests.session()
event_data = get_event(headers, session)
get_page(headers, event_data, session)
def get_event(headers, session):
start_url = 'xxxx'
start_1 = session.get(start_url, headers=headers).text
event_data = \
re.findall(r'<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="(.*?)" />', start_1, re.S)[0]
print(event_data)
return event_data
def get_page(headers, event_data, session):
start_url = 'xxxx'
page_1 = 17 # 起始页码
end_page = 50 # 结束页码
for i in range(page_1, end_page+1):
from_data = {
'__VIEWSTATE': event_data,
'__VIEWSTATEGENERATOR': 'F006C583',
'ID_ConstructionLicence_ucList$ddlCity': '全部',
'ID_ConstructionLicence_ucList$ucPager1$txtCurrPage': str(i),
'ID_ConstructionLicence_ucList$ucPager1$btnGo':'确定'
}
print('开始爬取第{}页'.format(i))
# print(from_data['__VIEWSTATE'])
page_req = session.post(start_url, data=from_data, headers=headers).text
event_data = re.findall(r'<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="(.*?)" />', page_req, re.S)[0]
guid_list = re.findall(r'ActDatumBase_Guid=(.*?)\',\'.*?\',\d+,\d+\);', page_req, re.S)
print(guid_list)
name_list = re.findall(r'<span id="ID_ConstructionLicence_ucList_gridView_ctl0\d_lblUnitEngineeringName">(.*?)</span>', page_req, re.S)
print(name_list)
if __name__ == '__main__':
main()















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









