







一、代码撰写目的
平常闲着没事,在各个国家统计官网浏览时,发现国家市场监督管理总局发布的公开信息具有很高的可挖掘性,这里以新疆省的信息为例,当我们打开这样一个网页https://spaqjg.e-cqs.cn/fplq_ui/#/queryPlatform2?dq=659后在搜索栏输入关键词“公司”后,便会弹出一系列的相关公司信息。这些信息具有很强的结构性,因此一眼看上去就是适合被大家狠狠的爬的奇才。

随意打开其中一个子链接,信息格式如下,
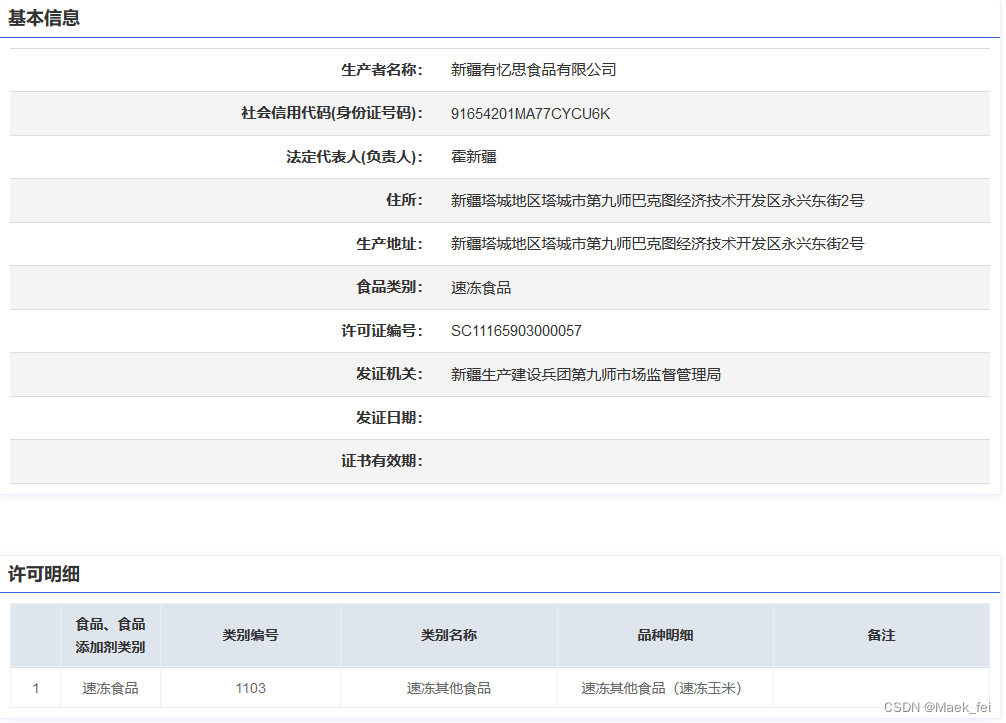
当我们将信息爬取整理之后,便可以轻松的统计新疆省各个地区的公司数量,不同食品类别的公司各有多少等,这些信息对于调研人员是非常重要的数据。
二、代码主体
话不多说,上菜
1、导入需要的库
import time
from bs4 import BeautifulSoup #4.10.0
from selenium import webdriver #3.141.0
from xlrd import open_workbook #1.2.0
from xlutils.copy import copy #2.0.02、selenium
url_search = 'https://spaqjg.e-cqs.cn/fplq_ui/#/queryPlatform2?dq=659'#待爬取网页网址
#调用selenium工具
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(executable_path=r"xxxx", options=options)#这里配置你自己的webdriver路径
driver.get(url_search)3、代码主体
elements = driver.find_elements_by_css_selector("div.button")#定位到每一个子链接元素
for element in elements:
content = []
driver.execute_script("arguments[0].click();", element)#依次点击每一个子链接
time.sleep(3)
driver.switch_to.window(driver.window_handles[-1])#窗口移到新打开的页面
html = driver.page_source
soup = BeautifulSoup(html, "lxml")
for k in soup.select("div.el-card__body div table.card-table tr"):#定位到子页面中的数据元素
content.append(k.text)
print(k.text)#边爬取边打印数据
r_xls = open_workbook("新疆.xlsx") # 读取excel文件
row = r_xls.sheets()[0].nrows # 获取已有的行数
excel = copy(r_xls) # 将xlrd的对象转化为xlwt的对象
worksheet = excel.get_sheet(0) # 获取要操作的sheet
# 对excel表追加一行内容
for i in range(len(content)):
worksheet.write(row, i, content[i]) # 括号内分别为行数、列数、内容
excel.save("新疆.xlsx") # 保存并覆盖文件
driver.close()#关闭当前页面
driver.switch_to.window(driver.window_handles[0])#返回第一个页面三、注意事项(完整的代码和数据在公主号和Github)
大家白嫖代码的时候一定要注意我标明的三方库版本,版本不对很有可能会出错,此外最后保存数据的方法有很多大家可以自行挑选更改。
最重要的一点,如果大家觉得有用跪求大家给我一个关注和点赞,有不懂的问题可以私信或者留言,欢迎大家关注我的公主号,上面有更多更详尽的代码,喜欢白嫖的有福了。

GitHub - Maekfei/Spider-projects: 爬虫实战,集合了数十个爬虫实战代码,全都亲测可用,借鉴麻烦点个star谢谢 同时欢迎访问我的github主页,copy代码的同时别忘了点个star 谢谢!
















 3326
3326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











