





模式版本管理模式
有人说,生活中唯一不变的东西就是变化。这对数据库模式也是如此。我们曾经认为不需要的信息,现在我们想捕捉。或者新的服务变得可用,需要包括在数据库记录中。不管变化背后的原因是什么,一段时间后,我们不可避免地需要对我们应用程序中的底层模式设计进行修改。虽然这经常会带来挑战,也许在传统的表格数据库系统中至少会有一些头疼的问题,但在MongoDB中,我们可以使用模式版本化模式来使变化更容易。
如前所述,在表格数据库中更新数据库模式是一个挑战。通常情况下,应用程序需要被停止,数据库被迁移以支持新的模式,然后重新启动。这种停机时间会导致客户体验不佳。此外,如果迁移没有完全成功会怎么样?回归到之前的状态往往是一个更大的挑战。
Schema Versioning模式利用了MongoDB支持不同形状的文档存在于同一个数据库集合的优势。MongoDB的这种多态性是非常强大的。它允许具有不同字段甚至同一字段的不同字段类型的文档和平地并排存在。
模式版本管理模式
这一模式的实现相对容易。我们的应用程序从一个原始模式开始,最终需要改变。当这种情况发生时,我们可以通过schema_version字段来创建和保存新的模式到数据库中。这个字段将使我们的应用程序知道如何处理这个特定的文件。或者,我们可以让我们的应用程序根据一些给定字段的存在或不存在来推断版本,但前一种方法更受欢迎。我们可以假设没有这个字段的文档是版本1。每一个新的模式版本都会增加schema_version字段的值,并且可以在应用程序中进行相应处理。
当新信息被保存时,我们使用最新的模式版本。我们可以根据应用和使用情况来决定是否需要将所有的文档更新为新的设计,或者在访问记录时进行更新,或者根本就不需要。在应用程序中,我们将为每个模式版本创建处理函数。
使用案例示例
如前所述,几乎所有的数据库都需要在其生命周期的某个时间点上进行修改,所以这种模式在很多情况下都是有用的。让我们来看看一个客户资料的用例。我们在有广泛的联系方法之前就开始保存客户信息。他们只能在家里或在工作中被联系到:
{
"_id": "<ObjectId>",
"name": "Anakin Skywalker",
"home": "503-555-0000",
"work": "503-555-0010"
}
随着时间的推移,越来越多的客户记录被保存,我们注意到手机号码也需要被保存。添加这个字段是直接的。
{
"_id": "<ObjectId>",
"name": "Darth Vader",
"home": "503-555-0100",
"work": "503-555-0110",
"mobile": "503-555-0120"
}
更多的时间过去了,现在我们发现越来越少的人有家庭电话,而其他的联系方法也变得更加重要,需要记录。像Twitter、Skype和Google Hangouts这样的项目正变得越来越流行,也许在我们刚开始保存联系信息时还没有。我们也想尽可能地证明我们的应用程序,在阅读了 "用模式构建 "系列后,我们知道了 “属性模式”,并将其实现为一个contact_method数组的值。在这样做的时候,我们创建了一个新的模式版本。
{
"_id": "<ObjectId>",
"schema_version": "2",
"name": "Anakin Skywalker (Retired)",
"contact_method": [
{ "work": "503-555-0210" },
{ "mobile": "503-555-0220" },
{ "twitter": "@anakinskywalker" },
{ "skype": "AlwaysWithYou" }
]
}
MongoDB文档模型的灵活性使得所有这些都可以在数据库不停机的情况下发生。从应用程序的角度来看,它可以被设计为读取两个版本的模式。在如何处理模式差异方面,这种应用程序的改变也不需要停机,前提是涉及的应用程序服务器不止一台。
总结
当应用程序停机不是一种选择,更新文档可能需要几个小时、几天或几周的时间才能完成,更新文档到新的版本不是一种要求,或者是这些情况的组合时,模式版本化模式非常好。它允许轻松地添加一个新的schema_version字段,并允许应用程序调整到这些变化。此外,它为我们开发人员提供了机会,可以更好地决定数据迁移的时间和方式。所有这些都会减少未来的技术债务,这是这种模式的另一大优势。
与本系列中提到的其他模式一样,模式版本化也有一些事情需要考虑。如果你在一个字段上有一个索引,而这个字段在文档中不在同一级别,那么在迁移文档的时候,你可能需要2个索引。
这种模式的主要好处之一是数据模型本身的简单性。所需要的只是添加schema_version字段。然后允许应用程序处理和处理不同的文档版本。
此外,正如在用例中所看到的,我们能够将模式设计模式结合在一起以获得额外的性能。在这种情况下,将模式版本和属性模式结合起来使用。允许在不停机的情况下进行模式升级,使得MongoDB中的模式版本设计特别强大,这很可能成为你在下一个应用中使用MongoDB的文档模型而不是传统的表格数据库的足够理由。
文件版本管理模式
数据库,如MongoDB,非常善于查询大量的数据并经常更新这些数据。然而,在大多数情况下,我们只对数据的最新状态进行查询。那么,我们需要查询数据的先前状态的情况呢?如果我们需要对我们的文件进行一些版本控制的功能呢?这时,我们可以使用文档版本控制模式。
这个模式是关于保持文档的版本历史的可用性和实用性。我们可以构建一个系统,结合MongoDB使用一个专门的版本控制系统。一个系统负责少数会变化的文档,MongoDB负责其他文档。这有可能是很麻烦的。然而,通过使用文档版本控制模式,我们能够避免使用多个系统来管理当前的文档和它们的历史,把它们放在一个数据库中。
文档版本管理模式
这个模式解决了希望在MongoDB中保留一些文档的旧版本而不是引入第二个管理系统的问题。为了达到这个目的,我们给每个文档添加一个字段,允许我们跟踪文档的版本。然后,数据库将有两个集合:一个是最新的(也是最多被查询的数据),另一个是所有数据的修订版。
文档版本管理模式对数据库中的数据和应用程序的数据访问模式做了一些假设。
1.每个文件没有太多的修订。
2.没有太多文件的版本。
3.大多数执行的查询是在文件的最新版本上进行的。
如果你发现这些假设不适合你的用例,这个模式可能不是很适合。你可能必须改变你实现文档版本管理模式的方式,或者你的用例可能只是需要一个不同的解决方案。
使用案例示例
文档版本管理模式在需要一组数据的特定时间点版本的高度管制行业中非常有用。金融和医疗行业是很好的例子。保险和法律行业是其他一些行业。有许多用例都是跟踪数据的某些部分的历史。
想一想保险公司是如何利用这种模式的。每个客户都有一个 "标准 "的保单,第二部分是专门针对该客户的,如果你愿意的话,是一个保单附加条款。这第二部分将包含一个保单附加条款的清单和一个被保险的具体项目的清单。当客户改变被保险的具体项目时,这些信息需要更新,而历史信息也需要提供。这在房主或租户的保险单中相当常见。例如,如果某人有特定的项目,他们希望在所提供的典型保险范围之外得到保险,他们会被单独列出,作为一个附加条款。保险公司的另一个用例可能是保留他们长期以来邮寄给客户的所有版本的 “标准政策”。
如果我们看一下文档版本管理模式的要求,这似乎是一个很好的用例。保险公司可能有几百万客户,对 "附加险 "列表的修订可能不会太频繁,对保单的大部分搜索都是关于最新的版本。
在我们的数据库中,每个客户可能有一个current_policy文档–包含客户的具体信息–在current_policies集合中,在policy_revisions集合中有policy_revision文档。此外,还有一个标准政策集合,对大多数客户来说都是一样的。当客户购买了一个新项目并希望将其添加到他们的保单中时,将使用当前_政策文件创建一个新的政策_修订文件。然后,文件中的一个版本字段被递增,以确定它是最新的修订版,并添加客户的更改。

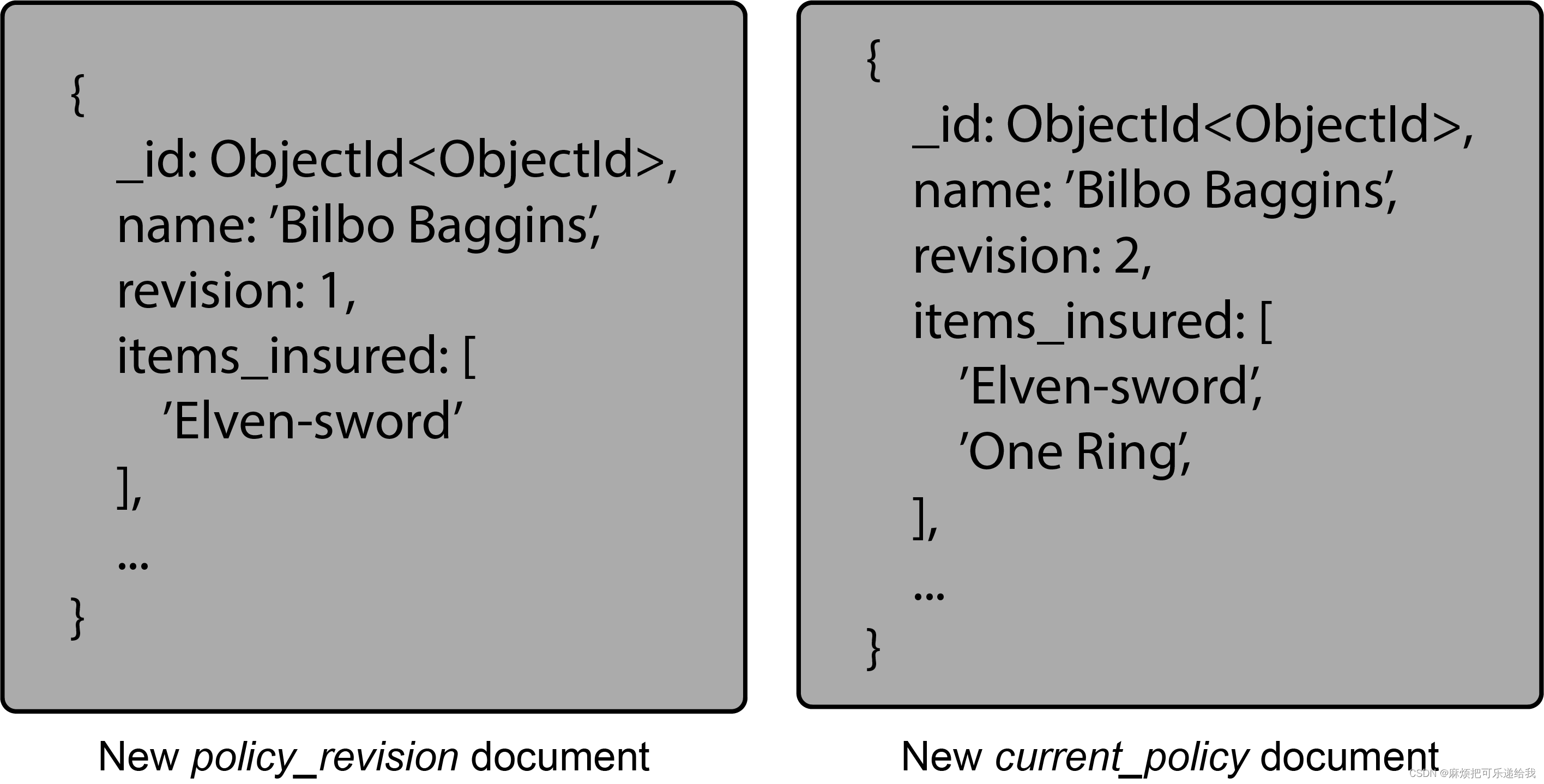
最新的修订版将被保存在current_policies集合中,而旧版本将被写入policy_revisions集合中。通过在current_policy集合中保留最新版本,查询可以保持简单。Policy_revisions集合可能也只保留几个版本,这取决于数据需求和要求。

在这个例子中,Middle-earth保险公司将为其客户制定一个标准保单。夏尔的所有居民都将共享这份特殊的政策文件。比尔博在他的正常保险范围之外,还有一些特殊的东西需要保险。他的精灵剑,以及最终的魔戒,都被加入到他的保单中。这些东西将存放在current_policies集合中,当有变化时,policy_revisions集合将保持变化的历史记录。
文档版本管理模式是比较容易实现的。它可以在现有的系统上实现,而不需要对应用程序或现有的文件做太多的改变。此外,访问最新版本的文档的查询仍然是高性能的。
这种模式的一个缺点是需要访问一个不同的集合来获取历史信息。另一个缺点是,对数据库的写入量会更高。这就是为什么使用这种模式的要求之一是,它发生在变化不太频繁的数据上。
结论
当你需要跟踪文档的变化时,文档版本管理模式是一个很好的选择。它比较容易实现,可以应用于现有的文档集。另一个好处是,对最新版本的数据的查询仍然表现良好。然而,它并不能取代一个专门的版本控制系统。
预分配模式
MongoDB的优点之一是文档数据模型。它不仅在模式设计方面提供了很大的灵活性,而且在开发周期方面也是如此。使用MongoDB文档,不知道以后需要哪些字段是很容易处理的。然而,有些时候,结构是已知的,能够填充或增长结构使设计更加简单。这就是我们可以使用预分配模式的地方。
内存分配通常是以块为单位进行的,以避免性能问题。在MongoDB的早期(MongoDB 3.2版本之前),当它使用MMAPv1存储引擎时,一个常见的优化是提前分配一个不断增长的文档的未来大小所需的内存。在MMAPv1中,随着文档的不断增长,当预分配的空间用完的时候,服务器需要重新找到一块内存空间放置文档,这个成本是相当昂贵的。而由于其无锁和更新时重写的算法,WiredTiger不需要这种同样的处理。
随着MMAPv1在MongoDB 4.0中的废弃,预分配模式似乎失去了一些光辉和必要性。然而,WiredTiger的预分配模式仍有用武之地。就像我们在 "用模式构建 "系列中讨论的其他模式一样,有一些应用方面的因素需要考虑。
预分配模式
这种模式简单地要求创建一个初始的空结构,以后再进行填充。这听起来微不足道,然而,你需要在简化的预期结果与解决方案可能消耗的额外资源之间进行平衡。更大的文件会带来更大的工作集,导致更多的内存来容纳这个工作集。
如果应用程序的代码使用一个不完全填充的结构,那么它的编写和维护就会容易得多,这可能很容易超过RAM的成本。假设需要用一个二维数组来表示一个剧院房间,每个座位都有一个 "行 "和 “号”,例如,座位 “C7”。有些行可能有较少的座位,但是在二维数组中寻找 "B3 "座位要比在只有现有座位单元的一维数组中用复杂的公式寻找座位要更快和更直观。由于可以为这些座位创建一个单独的数组,因此能够识别无障碍座位也更容易。
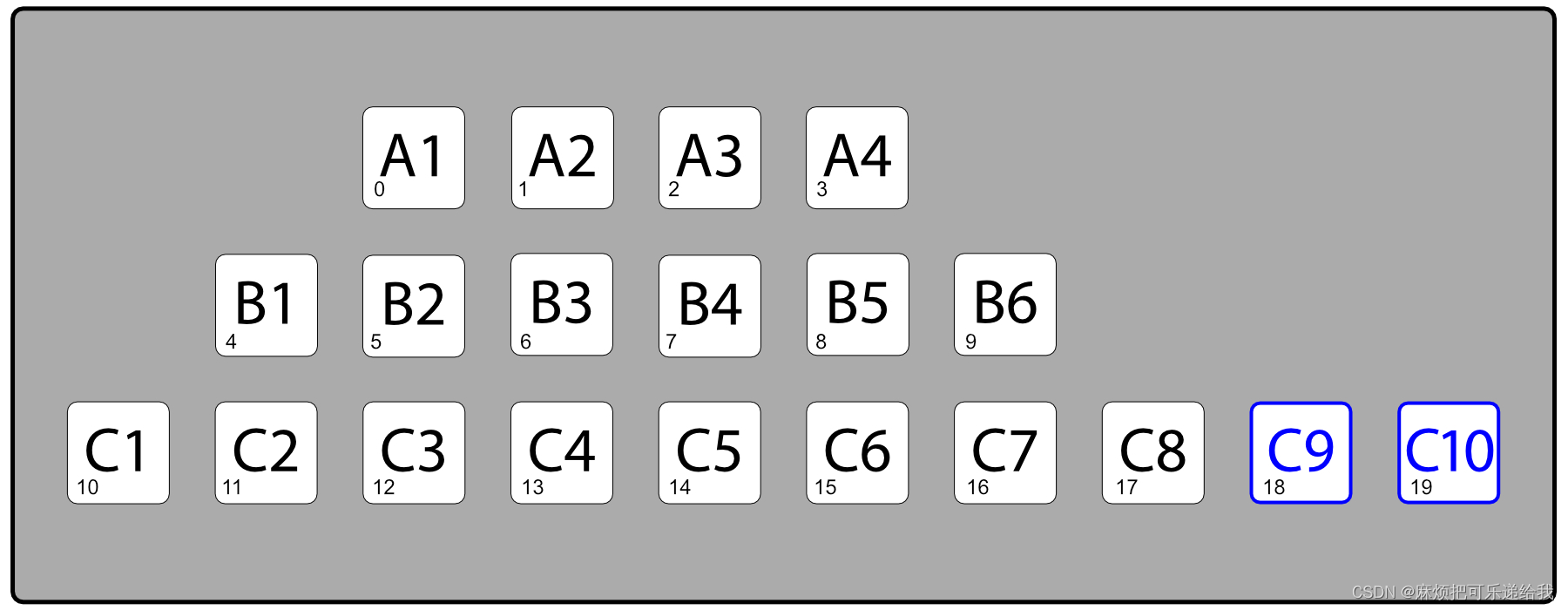

使用案例
正如前面所看到的,代表一个二维结构,如一个场地,是一个很好的用例。另一个例子是一个预订系统,其中资源被封锁或保留,以每天为基础。每一天使用一个单元格可能会使计算和检查比保持一个范围的列表更快。

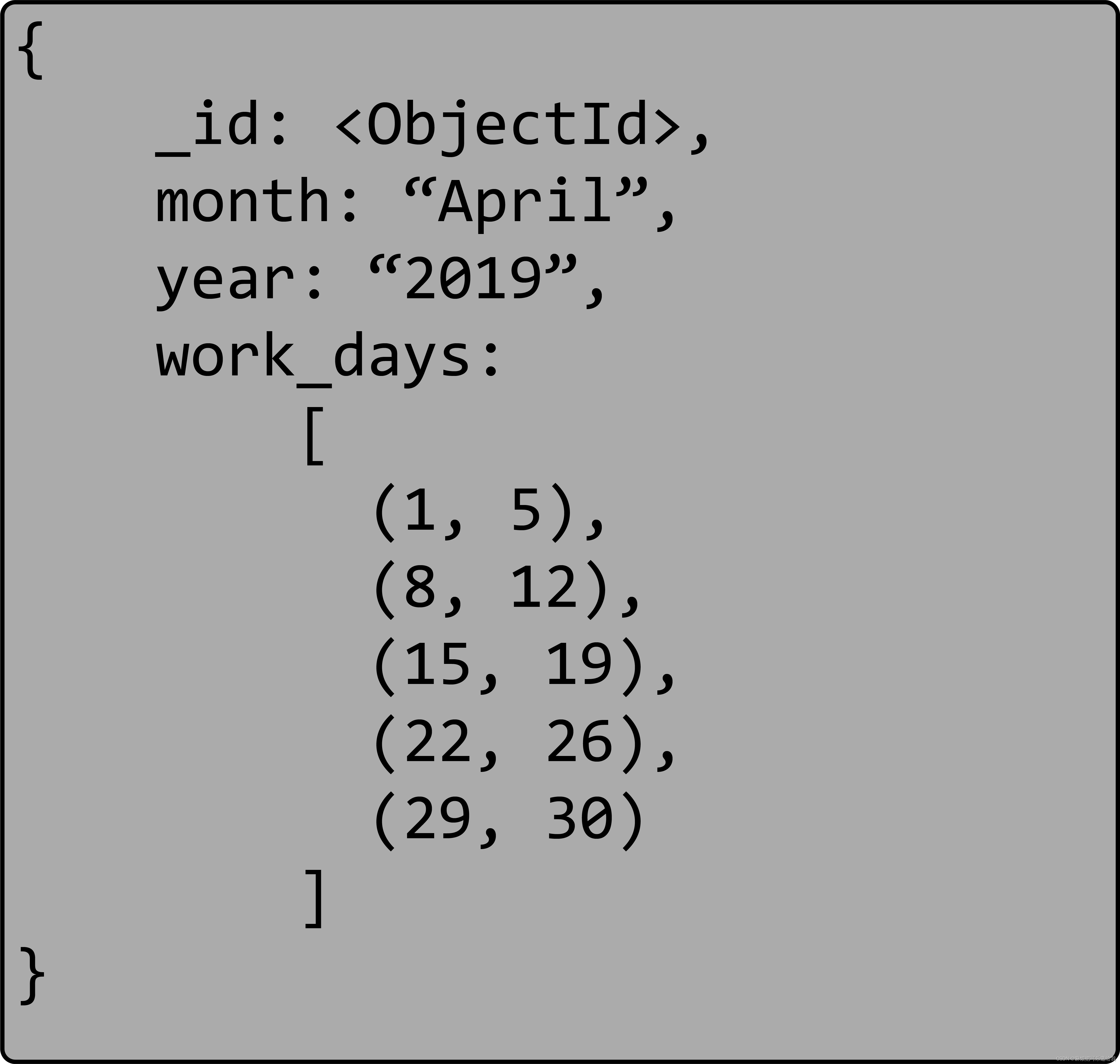
结论
这种模式可能是在MongoDB中使用MMAPv1存储引擎时最常用的一种。然而,由于该存储引擎的废弃,它已经失去了其通用的用例,但在某些情况下,它仍然是有用的。和其他模式一样,你需要在 "简单性 "和 "性能 "之间进行权衡。
树形模式
到目前为止,我们所涉及的许多模式设计模式都强调,节省JOIN操作的时间是一种好处。被一起访问的数据应该被存储在一起,一些数据的重复是可以的。像Extended Reference这样的模式设计模式就是一个很好的例子。然而,如果要连接的数据是分层的呢?例如,你想确定从一个员工到CEO的报告链?MongoDB提供了$graphLookup操作符,可以将数据作为图形进行导航,这可能是一种解决方案。然而,如果你需要对这种分层的数据结构进行大量的查询,你可能想应用同样的规则,把一起访问的数据存储在一起。这就是我们可以使用树型模式的地方。
树型模式
在传统的表格数据库中,有很多方法来表示一棵树。最常见的是让图中的一个节点列出它的父节点和一个节点列出它的子节点。这两种表示方法都可能需要多次访问来建立节点链。
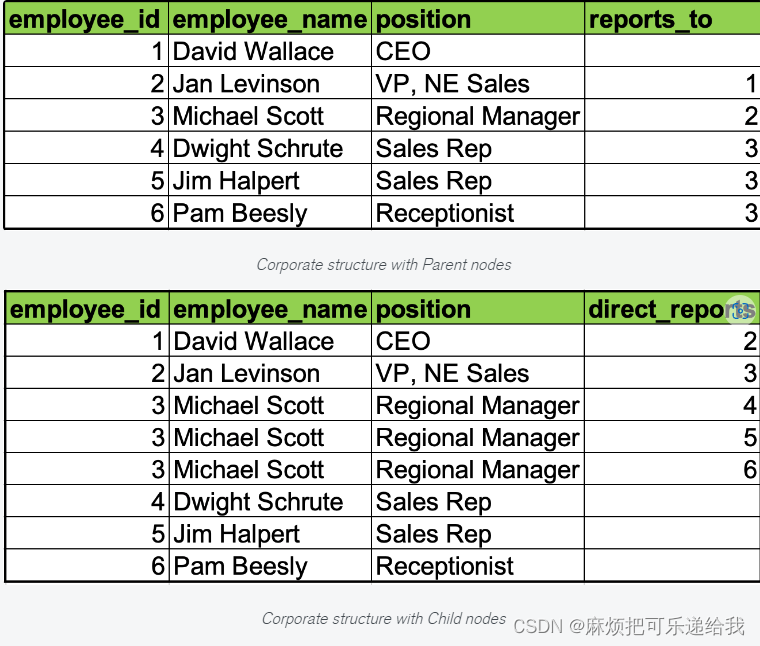
或者,我们可以存储从一个节点到层次结构顶端的完整路径。在这种情况下,我们基本上会存储每个节点的 “父节点”。在一个表格数据库中,这可能是通过对父节点的列表进行编码来完成的。MongoDB的方法是简单地将其表示为一个数组。

从这里可以看出,在这种表示法中,有一些数据重复。如果信息是相对静态的,比如在家谱中,你的父母和祖先不会改变,使得这个数组容易管理。然而,在我们的企业结构例子中,当事情发生变化,出现重组时,你将需要根据需要更新层次结构。This is still a small cost compared to the benefits you can gain from not calculating the trees all the time.
使用案例示例
产品目录是使用树型模式的另一个很好的例子。通常情况下,产品属于类别,而这些类别是其他类别的一部分。例如,固态硬盘可能属于硬盘,而硬盘又属于存储,而存储又属于计算机零件。偶尔,类别的组织可能会改变,但不会太频繁。

注意上面的文件中的祖先_类别字段,它记录了整个层次结构的情况。我们也有parent_category字段。在这两个字段中重复直接的父类,是我们在与许多使用树型模式的客户合作后形成的最佳做法。包括 "父类 "字段通常很方便,特别是当你需要保持在你的文件上使用$graphLookup的能力。
将祖先保留在一个数组中使得我们可以在这些值上创建一个多键索引。它允许一个给定类别的所有后裔被轻易地找到。至于直系子代,它们可以通过查看将我们给定的类别作为其直系 "父代 "的文件来获得。我们刚刚告诉你,这个字段会很方便。
结论
就许多模式而言,在使用它们时,往往要在简单性和性能之间进行权衡。在树型模式的情况下,你可以通过避免多重连接来获得更好的性能,然而,你将需要管理对图的更新。
近似模式
想象一下,一个相当有规模的城市,大约有39,000人。确切的数字是相当不稳定的,因为人们搬进和搬出这个城市,婴儿出生,人们死亡。我们可以花上一整天的时间,试图得到每天居民的确切数字。但大多数时候,39,000这个数字已经 “足够好了”。同样地,在我们开发的许多应用中,知道一个 "足够好 "的数字就足够了。如果一个 "足够好 "的数字是足够好的,那么这就是一个将近似模式用于你的模式设计的好机会。
近似模式
当我们需要显示具有挑战性或资源昂贵(时间、内存、CPU周期)的计算时,以及当精度不是最重要的时候,我们可以使用近似模式。再考虑一下人口问题。要得到这个数字的精确计算,需要付出什么代价?自从我开始计算以来,它是否会或可能发生变化?如果它被报告为39,000,而实际上是39,012,对城市的规划战略会有什么影响?
从应用的角度来看,我们可以建立一个近似系数,这样可以减少对数据库的写入,并且仍然提供统计上有效的数字。例如,假设我们的城市规划策略是基于每10,000人需要一辆消防车。100人可能看起来是一个很好的 "更新 "规划期。“我们正在接近下一个门槛,最好开始做预算。”
那么,在一个应用程序中,我们可以建立一个计数器,只按100,1%的时间更新数据库中的人口,而不是在每次变化时更新。在这个例子中,我们的写入量明显减少了99%。另一个选择可能是有一个函数返回一个随机数。例如,如果该函数返回一个从0到100的数字,它将在1%的时间内返回0。当这个条件被满足时,我们就把计数器增加100。
为什么我们要关注这个问题?嗯,当处理大量数据或大量用户时,对写操作的性能影响也会变得很大。你的规模越大,这种影响也就越大,在规模上,这往往是你最重要的考虑。通过减少写操作和减少用于不需要 "完美 "的数据的资源,它可以带来性能上的巨大改善。
使用案例示例
人口模式是近似模式的一个例子。我们可以使用这种模式的另一个用例是网站视图。一般来说,知道是否有700,000人访问了网站,或者699,983人,并不是至关重要的。因此,我们可以在我们的应用程序中建立一个计数器,当我们的阈值达到时,在数据库中更新它。
这可能会对网站的性能产生巨大的影响。将时间和资源花在关键业务的数据上是有意义的。把它们都花在一个页面计数器上似乎并不是一个很好的资源利用。
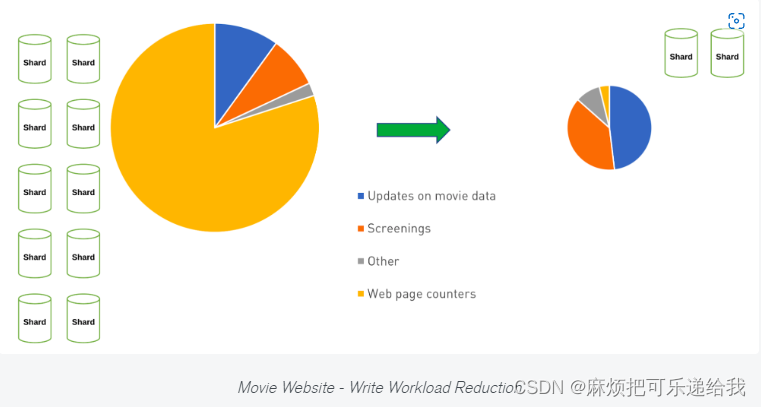
在上面的图片中,我们可以看到我们如何使用近似模式,不仅可以减少反操作的写入量,而且我们还可以看到通过减少这些写入量来降低架构的复杂性和成本。这可能会导致进一步的节约,而不仅仅是写入数据的时间。与我们之前探讨的计算模式类似,它可以通过不需要频繁地运行计算来节省整体的CPU使用。
结论
近似模式对于处理难以计算和/或昂贵的数据的应用来说是一个很好的解决方案,而且这些数字的准确性并不重要。我们可以减少对数据库的写操作,提高性能,并保持统计学上有效的数字。然而,使用这种模式的代价是,精确的数字没有被表示出来,而且必须在应用程序本身进行实现。
扩展引用模式
在这个 "用模式构建 "系列中,我希望你已经发现,你的模式应该是什么样子的一个驱动力,就是数据的访问模式是什么。如果我们有许多类似的字段,属性模式可能是一个不错的选择。适应对一小部分数据的访问是否会极大地改变我们的应用?也许离群模式是可以考虑的。一些模式,如子集模式,引用了额外的集合,并依靠JOIN操作将每一块数据重新组合起来。当需要大量的JOIN操作来汇集频繁访问的数据时,怎么办?这就是我们可以使用扩展引用模式的地方。
扩展引用模式
有的时候,为数据建立独立的集合是有意义的。如果一个实体可以被认为是一个单独的 “东西”,那么拥有一个单独的集合往往是有意义的。例如,在一个电子商务应用程序中,存在一个订单的概念,也存在一个客户和库存。它们是独立的逻辑实体。

然而,从性能的角度来看,这变得很有问题,因为我们需要把一个特定订单的信息碎片放在一起。一个客户可以有N个订单,形成一个1-N的关系。从订单的角度来看,如果我们把它翻过来,他们与一个客户有N-1的关系。嵌入每个订单的所有客户信息,只是为了减少JOIN操作,导致大量的重复信息。此外,一个订单可能不需要所有的客户信息。
扩展引用模式提供了一个处理这些情况的好方法。我们没有复制客户的所有信息,而只是复制我们经常访问的字段。我们不需要嵌入所有的信息,也不需要包括连接信息的引用,而只需要嵌入那些最优先和最经常访问的字段,如姓名和地址。

使用这种模式时需要考虑的是,数据是重复的。因此,如果存储在主文件中的数据是不经常变化的字段,那么它的效果最好。像user_id和一个人的名字是不错的选择。这些很少变化。
另外,只带入和复制需要的数据。想想一张订单的发票。如果我们在发票上引入了客户的名字,那么在那个时候我们需要他们的第二电话号码和非运输地址吗?可能不需要,因此我们可以不把这些数据放在发票集合中,而参考一个客户集合。
当信息被更新时,我们也需要考虑如何处理这个问题。哪些扩展引用发生了变化?那些应该在什么时候被更新?如果信息是一个账单地址,我们是否需要为历史目的保留这个地址,还是可以更新?有时候,数据的重复是更好的,因为你可以保留历史值,这可能更有意义。我们发货时客户居住的地址在订单文件中更有意义,然后通过客户集合获取当前地址。
使用案例示例
一个订单管理应用程序是这种模式的典型用例。当考虑到N-1的关系,订单到客户,我们希望减少信息的连接,以提高性能。通过包括对最经常被连接的数据的简单引用,我们在处理中节省了一个步骤。
如果我们继续以订单管理系统为例,在一张发票上,Acme公司可能被列为一个铁砧的供应商。从发票的角度来看,拥有Acme公司的联系信息可能并不十分重要。例如,这些信息最好存放在一个单独的供应商集合中。在发票集合中,我们会保留所需的供应商信息,作为供应商信息的扩展参考。
结论
当你的应用程序遇到许多重复的JOIN操作时,扩展引用模式是一个很好的解决方案。通过识别查找侧的字段并将这些经常访问的字段带入主文件,性能得到了提高。这是通过更快的读取和减少JOIN的总数量来实现的。然而,请注意,数据重复是这种模式设计模式的一个副作用。
子集模式
几年前,第一台个人电脑有高达256KB的内存和双5.25英寸软盘驱动器。没有硬盘,因为它们在当时是非常昂贵的。这些限制导致在处理大量(在当时)数据时,由于缺乏内存而不得不实际交换软盘。如果当时有一种方法可以只把我经常使用的数据带入内存,就像整体数据的一个子集。
现代的应用程序也不能避免资源耗尽的问题。MongoDB将经常访问的数据(称为工作集)保存在RAM中。当数据和索引的工作集增长超过分配的物理RAM时,性能就会下降,因为磁盘访问开始发生,数据从RAM中滚出。
我们怎样才能解决这个问题呢?首先,我们可以在服务器上增加更多的RAM。但这只能扩展到这么多。我们可以考虑将我们的集合分片,但这伴随着额外的成本和复杂性,我们的应用程序可能还没有准备好。另一个选择是减少我们工作集的大小。这就是我们可以利用子集模式的地方。
子集模式
这个模式解决了工作集超过RAM的问题,导致信息被从内存中删除。这经常是由大型文件引起的,这些文件中有很多数据并没有被应用程序实际使用。我这样说到底是什么意思?
想象一下,一个电子商务网站有一个产品的评论列表。当访问该产品的数据时,我们很可能只需要最近的10条左右的评论。拉入所有的产品数据和所有的评论,很容易导致工作集扩大。

与其将所有的评论与产品一起存储,我们可以将这个集合分成两个集合。一个集合将拥有最频繁使用的数据,例如当前的评论,另一个集合将拥有不太频繁使用的数据,例如旧的评论、产品历史等。我们可以复制1-N或N-N关系的一部分,由关系中最常用的一方使用。

在产品集合中,我们将只保留最近的十条评论。这使得工作集可以通过只带入整体数据的一部分或子集来减少。额外的信息,即本例中的评论,被存储在一个单独的评论集合中,如果用户想看额外的评论,可以访问这个集合。当考虑在哪里分割你的数据时,文件中最常用的部分应该进入 "主 "集合,而不太常用的数据则进入另一个集合。对于我们的评论,这种分割可能是产品页面上可见的评论数量。
使用案例示例
当我们在文档中拥有一大部分很少需要的数据时,子集模式就非常有用。产品评论、文章评论、电影中的演员都是这种模式的用例。当文档的大小给工作集的大小带来压力,导致工作集超过计算机的RAM容量时,子集模式是一个可以考虑的选择。
结论
通过使用更小的文件和更频繁的访问数据,我们减少了工作集的总体大小。这可以缩短应用程序所需的最频繁使用的信息的磁盘访问时间。在使用子集模式时,我们必须做出的一个权衡是,我们必须管理子集,而且如果我们需要拉入较早的评论或所有的信息,这将需要额外地去数据库做这些事。
计算模式
在 "用模式构建 "系列中,我们已经研究了各种优化存储数据的方法。现在,我们要看一下模式设计的另一个方面。仅仅存储数据并使其可用,通常并不那么有用。当我们能从数据中计算出数值时,数据的有用性就变得更加明显。最新的亚马逊Alexa的总销售收入是多少?有多少观众观看了最新的电影大片?这些类型的问题可以从存储在数据库中的数据中得到答案,但必须进行计算。
虽然每次被请求时运行这些计算都会成为一个高度资源密集型的过程,特别是在巨大的数据集上。CPU周期、磁盘访问、内存都可能涉及。
想想一个电影信息网络应用。每次我们访问该应用程序查找一部电影时,该页面都会提供关于该电影在多少家影院播放过的信息,观看过该电影的总人数,以及总体收入。如果应用程序必须在每次访问页面时不断地计算这些数值,它可能会在流行的电影上使用大量的处理资源
然而,大多数时候,我们不需要知道这些确切的数字。我们可以在后台进行计算,并在一段时间内更新主要的电影信息文件。然后,这些计算允许我们显示数据的有效表示,而不必在CPU上投入额外的精力。
计算模式
当我们的应用程序中有需要重复计算的数据时,就可以利用计算模式。例如,如果你每小时有1,000,000次读取,但每小时只有1,000次写入,在写入时进行计算将使计算次数减少1000倍。
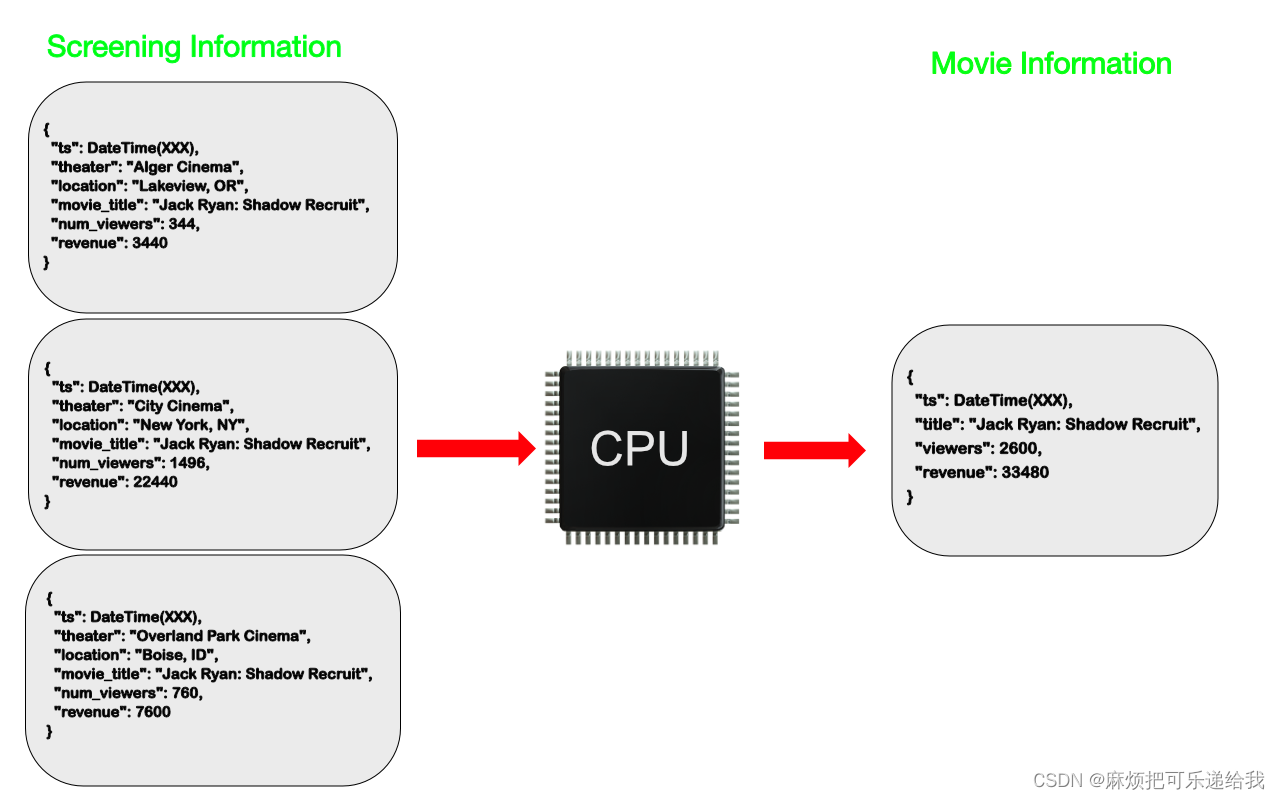
在我们的电影数据库的例子中,我们可以根据我们拥有的关于某部电影的所有放映信息进行计算,计算出结果,并将其与电影本身的信息一起存储。在一个低写环境中,计算可以与源数据的任何更新一起进行。在有更多定期写入的地方,计算可以在规定的时间间隔内完成,例如每小时一次。由于我们没有干扰筛选信息中的源数据,我们可以继续重新运行现有的计算或在任何时间点运行新的计算,并知道我们会得到正确的结果。
其他执行计算的策略可以包括,例如,给文件添加一个时间戳,以表明它最后一次更新的时间。然后,应用程序可以确定何时需要进行计算。另一个选择可能是有一个需要完成的计算队列。选择更新策略最好留给应用程序开发人员。
使用案例示例
计算模式可以用在需要对数据进行计算的地方。需要加总的数据集,如收入或观众,是一个很好的例子,但时间序列数据、产品目录、单视图应用程序和事件来源也是这种模式的主要候选人。
这是一个许多客户已经实施的模式。例如,一个客户对车辆数据做了大量的聚合查询,并将结果存储在服务器上,以显示未来几个小时的信息。
一家出版公司汇编各种数据以创建有序的列表,如 “100个最佳…”。这些名单只需要在一段时间内重新生成,而基础数据可能在其他时间更新。
总结
这种强大的设计模式可以减少CPU的工作负荷,提高应用性能。它可以被用来对集合中的数据进行计算或操作,并将结果存储在一个文件中。这样就可以避免重复进行相同的计算。每当你的系统在重复进行相同的计算,并且你的读写比很高时,就可以考虑计算模式。
异常点模式
想象一下,你正在建立一个卖书的电子商务网站。你可能有兴趣运行的查询之一是 “谁购买了某本书”。这可能对推荐系统很有用,可以向你的客户展示他们感兴趣的类似书籍。你决定在一个数组中为每本书存储客户的user_id。很简单,对吗?
好吧,这可能确实对99.99%的情况有效,但当J.K.罗琳发布了一本新的《哈利-波特》,销量激增到数百万时,会发生什么?16MB的BSON文件大小限制很容易就会达到。为这种离群的情况重新设计我们的整个应用程序可能会导致典型书籍的性能下降,但我们确实需要考虑到这一点。
异常点模式
通过异常点模式,我们正在努力防止少数查询或文件将我们的解决方案推向一个对我们大多数用例来说不是最佳的方案。不是每一本售出的书都能卖出数百万册。
一个典型的存储用户ID信息的图书文档可能看起来像这样:
{
"_id": ObjectID("507f1f77bcf86cd799439011")
"title": "A Genealogical Record of a Line of Alger",
"author": "Ken W. Alger",
…,
"customers_purchased": ["user00", "user01", "user02"]
}
这对大多数不可能进入 "畅销书 "名单的书籍来说是很有效的。虽然对异常值的核算导致customers_purchased数组的扩展超过了我们设定的1000项限制,我们将添加一个新的字段来 "标记 "该书为异常值。
{
"_id": ObjectID("507f191e810c19729de860ea"),
"title": "Harry Potter, the Next Chapter",
"author": "J.K. Rowling",
…,
"customers_purchased": ["user00", "user01", "user02", …, "user999"],
"has_extras": "true"
}
然后,我们将把溢出的信息移到一个与书的id相联系的单独文件中。在应用程序中,我们将能够确定一个文件是否有一个值为 "true "的has_extras字段。如果是这样的话,应用程序将检索到额外的信息。这可以被处理成对大多数的应用程序代码来说是相当透明的。
许多设计决定将基于应用程序的工作量,所以这个解决方案旨在展示Outlier模式的一个例子。这里需要掌握的重要概念是,离群点的数据有足够大的差异,如果它们被认为是 "正常 "的,为它们改变应用设计会降低更典型的查询和文档的性能。
使用案例示例
异常点模式是一个高级模式,但它可以带来很大的性能改进。它经常被用在受欢迎程度是一个因素的情况下,例如在社交网络关系、书籍销售、电影评论等。互联网已经把我们的世界变成了一个更小的地方,当某些东西变得流行时,它改变了我们需要围绕该项目进行数据建模的方式。
一个例子是一个拥有视频会议产品的客户。在大多数视频会议中,授权与会者的名单可以与会议保持在同一个文件中。然而,有一些活动,比如一个公司的全员会议,有成千上万的预期与会者。对于这些例外的会议,客户实施了 "溢出 "文件来记录那些长长的与会者名单。
结论
异常点模式解决的问题是防止用一些文件或查询来决定一个应用程序的解决方案。特别是当这个解决方案对于大多数用例来说都不是最佳的时候。我们可以利用MongoDB灵活的数据模型,在文档中添加一个字段,将其 "标记 "为异常值。然后,在应用程序内部,我们以稍微不同的方式处理异常值。通过为典型的文档或查询定制模式,应用程序的性能将为这些正常的用例进行优化,而异常值仍将被解决。
这种模式需要考虑的一点是,它通常是为特定的查询和情况而定制的。因此,临时查询可能会导致性能不够理想。此外,由于大部分工作是在应用程序代码本身中完成的,随着时间的推移可能需要额外的代码维护。
桶模式
这种模式在处理物联网(IoT)、实时分析或一般的时间序列数据时特别有效。通过将数据放在一起,我们可以更容易地组织特定的数据组,提高发现历史趋势或提供未来预测的能力,并优化我们对存储的使用。
桶模式
随着数据在一段时间内以流的形式出现(时间序列数据),我们可能倾向于将每个测量值存储在自己的文档中。然而,这种倾向是一种处理数据的关系型方法。如果我们有一个传感器,每分钟测量温度并将其保存到数据库中,我们的数据流可能看起来像:
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}
当我们的应用程序在数据和索引大小方面进行扩展时,这可能会带来一些问题。例如,我们可能最终不得不为每一个测量值建立索引sensor_id和时间戳,以便在牺牲RAM的情况下实现快速访问。不过,通过利用文档数据模型,我们可以按时间将这些数据 "打包 "到文档中,以保存特定时间跨度的测量结果。我们还可以以编程方式向这些 "桶 "中的每一个添加附加信息。
通过将 "桶 "模式应用到我们的数据模型中,我们可以得到一些好处,如节省索引大小,简化潜在的查询,以及在我们的文档中使用预先汇总的数据的能力。以上面的数据流为例,将Bucket Pattern应用到其中,我们会得到:
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
…
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}
通过使用 "桶 "模式,我们已经将我们的数据 “桶化”,在这种情况下,一个小时的桶。这个特定的数据流仍在增长,因为它目前只有42个测量值;仍有更多该小时的测量值被添加到 "桶 "中。当它们被添加到测量数组中时,transaction_count将被递增,sum_temperature也将被更新。
有了预先汇总的sum_temperature值,就可以很容易地拉出一个特定的桶并确定该桶的平均温度(sum_temperature / transaction_count)。在处理时间序列数据时,知道2018年7月13日下午2:00到3:00在加州康宁市的平均温度,往往比知道下午2:03的温度更有趣,更重要。通过分桶和做预聚合,我们更能够轻松地提供这些信息。
此外,随着我们收集的信息越来越多,我们可能会确定将所有的源数据保存在一个档案中是更有效的。例如,我们需要多频繁地访问1948年的康宁公司的温度?能够将这些数据桶转移到数据档案中是一个很大的好处。
使用案例示例
使时间序列数据在现实世界中有价值的一个例子来自博世的物联网实施。他们在一个汽车现场数据应用中使用MongoDB和时间序列数据。该应用从整个车辆的各种传感器中捕捉数据,允许改进车辆本身的诊断和组件性能。
其他例子包括各大银行在金融应用中采用这种模式,将交易分组。
总结
在处理时间序列数据时,在MongoDB中使用Bucket模式是一个不错的选择。它减少了集合中文件的总体数量,提高了索引性能,并且通过利用预聚合,它可以简化数据访问。
属性模式
属性模式特别适合于以下情况。
我们有很多类似字段的大文件,但有一个字段子集有共同的特征,我们想对这个字段子集进行排序或查询,或
我们需要排序的字段只出现在一小部分文档中,或
上述两个条件都在文档中得到满足。
出于性能方面的考虑,为了优化我们的搜索,我们可能需要许多索引来说明所有的子集。创建所有这些索引会降低性能。属性模式为这些情况提供了一个很好的解决方案。
属性模式
让我们想想一个电影的集合。这些文件很可能在所有的文件中都有类似的字段:标题、导演、制片人、演员,等等。比方说,我们想搜索发行日期。在这样做的时候,我们面临的一个挑战是哪个发布日期?电影在不同的国家往往是在不同的日期上映的。
{
title: "Star Wars",
director: "George Lucas",
...
release_US: ISODate("1977-05-20T01:00:00+01:00"),
release_France: ISODate("1977-10-19T01:00:00+01:00"),
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
release_UK: ISODate("1977-12-27T01:00:00+01:00"),
...
}
搜索一个发行日期需要同时在许多领域进行搜索。为了快速搜索发布日期,我们需要在我们的电影集上建立几个索引。
{release_US: 1}
{release_France: 1}
{release_Italy: 1}
通过使用属性模式,我们可以将这个信息子集移到一个数组中,并减少索引的需要。我们把这些信息变成一个键值对的数组。
{
title: "Star Wars",
director: "George Lucas",
…
releases: [
{
location: "USA",
date: ISODate("1977-05-20T01:00:00+01:00")
},
{
location: "France",
date: ISODate("1977-10-19T01:00:00+01:00")
},
{
location: "Italy",
date: ISODate("1977-10-20T01:00:00+01:00")
},
{
location: "UK",
date: ISODate("1977-12-27T01:00:00+01:00")
},
…
],
…
}
通过在数组中的元素上创建一个索引,索引变得更容易管理。
{ "releases.location": 1, "releases.date": 1}
通过使用属性模式,我们可以为我们的文件添加组织的共同特征,并说明罕见/不可预测的领域。例如,一部电影在一个新的或小的节日里发行。此外,转移到一个键/值公约允许使用非确定的命名和容易添加限定词。例如,如果我们的数据收集是关于水瓶的,我们的属性可能看起来像:
"specs": [
{ k: "volume", v: "500", u: "ml" },
{ k: "volume", v: "12", u: "ounces" }
]
在这里,我们把信息分成键和值,"k "和 “v”,并加入第三个字段,“u”,允许测量单位被单独存储。
{"specks.k": 1, "specs.v": 1, "specs.u": 1}
使用案例示例
属性模式非常适用于那些有相同值类型的字段集的模式,如日期列表。在处理产品的特性时,它也很有效。一些产品,如服装,可能有以小号、中号或大号表示的尺寸。同一个系列中的其他产品可能用体积来表示。还有一些产品可能用物理尺寸或重量来表示。
资产管理领域的一个客户最近使用属性模式部署了他们的解决方案。该客户使用该模式来存储一个特定资产的所有特征。这些特征在资产中很少是共同的,或者在设计时很难预测。关系模型通常使用复杂的设计过程,以用户定义字段的形式表达相同的想法。
虽然产品目录中的许多字段是相似的,如名称、供应商、制造商、原产国等,但物品的规格,或属性,可能有所不同。如果你的应用程序和数据访问模式依赖于一次搜索许多这些不同的字段,那么属性模式为数据提供了一个很好的结构。
结论
属性模式提供了更容易的文档索引,针对每个文档的许多类似字段。通过将这个数据子集转移到一个键值子文档中,我们可以使用非确定的字段名,为信息添加额外的限定词,并更清楚地说明原始字段和值的关系。当我们使用属性模式时,我们需要更少的索引,我们的查询变得更简单,我们的查询变得更快。
多态模式
当我们有相似性多于差异性的文件时,就可以使用这种模式。当我们想把文件放在一个单一的集合中时,它也很适合。
职业运动员的记录有一些相似之处,但也有一些差异。通过多态模式,我们可以很容易地适应这些差异。如果我们不使用多态模式,我们可能有一个保龄球运动员的集合和一个网球运动员的集合。当我们想查询所有的运动员时,我们需要做一个耗时且可能很复杂的连接。相反,由于我们使用的是多态模式,我们所有的数据都存储在一个运动员集合中,对所有运动员的查询可以通过一个简单的查询来完成。
这种设计模式也可以流向嵌入式子文件。在上面的例子中,Martina Navratilova不仅仅是作为一个单一的运动员参加比赛,所以我们可能想把她的记录结构化,如下所示:
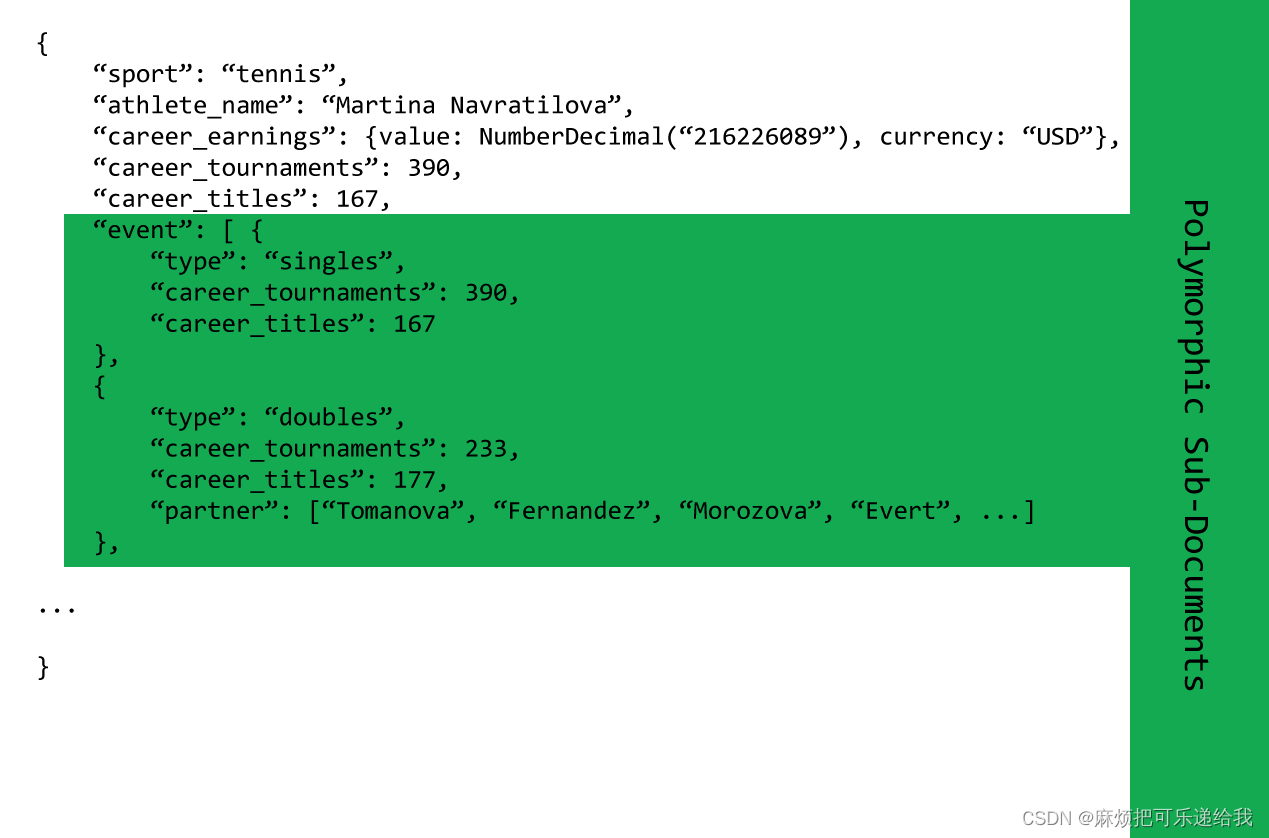
从应用程序开发的角度来看,当使用多态模式时,我们要查看文件或子文件中的特定字段,以便能够跟踪差异。例如,我们会知道,一个网球运动员的运动员可能参与不同的活动,而不同的体育运动员可能不参与。这通常会要求根据给定文件中的信息在应用程序代码中采用不同的代码路径。或者,也许要编写不同的类或子类来处理网球、保龄球、足球和橄榄球运动员之间的差异。
使用案例示例
多态模式的一个用例是
单一视图应用程序
想象一下,在一家公司工作,随着时间的推移,收购了其他公司的技术和数据模式。例如,每个公司都有许多数据库,每个数据库都以不同的方式来模拟 “与客户的保险”。然后你收购了这些公司,并希望将所有这些系统整合成一个。将这些不同的系统合并到一个统一的SQL模式中,成本很高,也很费时。
大都会人寿能够利用MongoDB和多态模式,在几个月内建立他们的单视图应用程序。他们的单视图应用程序将来自多个来源的数据汇总到一个中央存储库中,使客户服务、保险代理、计费和其他部门能够获得客户的360度图片。这使他们能够在降低公司成本的情况下提供更好的客户服务。此外,使用MongoDB灵活的数据模型和多态模式,开发团队能够快速创新,使他们的产品上线。
单一视图应用程序是多态模式的一个使用案例。它也可以很好地用于产品目录,如自行车和鱼竿有不同的属性。我们的运动员例子可以很容易地扩展到一个更成熟的内容管理系统,并在那里利用多态模式。
结论
多态模式是在文档的相似性大于差异性的情况下使用的。这种模式设计的典型用例是。
- 单一视图应用程序
- 内容管理
- 移动应用
- 产品目录
多态模式提供了一种易于实现的设计,允许在单个集合中进行查询。
本文翻译自 https://www.mongodb.com/blog/search/Daniel%20Coupal/2














 3357
3357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









