







Hadoop3.4.0 + Hive3.1.3 分布式安装一体化教程
文章目录
1. Docker安装
- 安装Docker(过程略)
docker --version
- 安装docker-compose(过程略)
docker-compose --version
- Docker镜像问题:由于很多镜像源网站已失效,比如阿里云、腾讯云把自家的镜像加速服务限定在其内部产品了,清华源、网易源皆已无法正常使用。
参考:docker镜像加速源配置,目前可用镜像源列举,在docker的Settings-Docker Engine上的配置文件添加镜像源
修改镜像的说明:win10 Docker Desktop 换国内源 及 修改镜像位置
2. Hadoop安装
Dockerfile使用说明:【docker】使用 Dockerfile 构建镜像
Hadoop安装教程:docker配置全分布式hadoop(5台容器两台主节点,三台从节点)_
Dockerfile(已修正):
# syntax=docker/dockerfile:1
# 参考资料: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
FROM ubuntu:20.04
ARG TARBALL=hadoop-3.4.0.tar.gz
# 提前下载好的java8压缩包, 下载地址: https://www.oracle.com/java/technologies/downloads/
ARG JAVA_TARBALL=./jdk-8u212-linux-x64.tar.gz
ENV HADOOP_HOME=/app/hadoop
ENV JAVA_HOME=/usr/java
WORKDIR $JAVA_HOME
WORKDIR $HADOOP_HOME
# RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
# RUN sed -i s@/archive.ubuntu.com/@/mirrors.163.com/@g /etc/apt/sources.list
# 替换 sources.list 为阿里云镜像源
RUN echo "deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse" > /etc/apt/sources.list && \
echo "deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse" >> /etc/apt/sources.list
RUN apt-get clean && \
apt-get update --allow-insecure-repositories && \
apt-get upgrade -y --allow-unauthenticated
#&& \
RUN apt-get install -y wget && \
apt-get install -y ssh
# 拷贝jdk8安装包
COPY ${JAVA_TARBALL} ${JAVA_HOME}/${JAVA_TARBALL}
RUN tar -zxvf /usr/java/${JAVA_TARBALL} --strip-components 1 -C /usr/java && \
rm /usr/java/${JAVA_TARBALL} && \
# 设置java8环境变量
echo export JAVA_HOME=${JAVA_HOME} >> ~/.bashrc && \
echo export PATH=\$PATH:\$JAVA_HOME/bin >> ~/.bashrc && \
echo export JAVA_HOME=${JAVA_HOME} >> /etc/profile && \
echo export PATH=\$PATH:\$JAVA_HOME/bin >> /etc/profile && \
# 下载hadoop安装包
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/${TARBALL} && \
# 解压hadoop安装包
tar -zxvf ${TARBALL} --strip-components 1 -C $HADOOP_HOME && \
rm ${TARBALL} && \
# 设置从节点
echo "worker1\nworker2\nworker3" > $HADOOP_HOME/etc/hadoop/workers && \
echo export HADOOP_HOME=${HADOOP_HOME} >> ~/.bashrc && \
echo export PATH=\$PATH:\$HADOOP_HOME/bin >> ~/.bashrc && \
echo export PATH=\$PATH:\$HADOOP_HOME/sbin >> ~/.bashrc && \
echo export HADOOP_HOME=${HADOOP_HOME} >> /etc/profile && \
echo export PATH=\$PATH:\$HADOOP_HOME/bin >> /etc/profile && \
echo export PATH=\$PATH:\$HADOOP_HOME/sbin >> /etc/profile && \
mkdir /app/hdfs && \
# java8软连接
ln -s $JAVA_HOME/bin/java /bin/java
# 拷贝hadoop配置文件
COPY ./hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml
COPY ./core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml
COPY ./mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml
COPY ./yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml
# 设置hadoop环境变量
RUN echo export JAVA_HOME=$JAVA_HOME >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
echo export HADOOP_MAPRED_HOME=$HADOOP_HOME >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
echo export HDFS_NAMENODE_USER=root >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
echo export HDFS_DATANODE_USER=root >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
echo export HDFS_SECONDARYNAMENODE_USER=root >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
echo export YARN_RESOURCEMANAGER_USER=root >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
echo export YARN_NODEMANAGER_USER=root >> $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# ssh免登录设置
RUN echo "/etc/init.d/ssh start" >> ~/.bashrc && \
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 0600 ~/.ssh/authorized_keys
# NameNode WEB UI服务端口
EXPOSE 9870
# namenode文件服务端口
EXPOSE 9000
# dfs.namenode.secondary.http-address
EXPOSE 9868
# dfs.datanode.http.address
EXPOSE 9864
# dfs.datanode.address
EXPOSE 9866
# msyql
EXPOSE 3306
# others
EXPOSE 80
EXPOSE 13306
# backup
EXPOSE 8088
1. 根据Dockerfile拉取hadoop镜像
$ docker build -t [docker_name] [Dockerfile_dir]
$ docker build -t hadoop .
2. 通过hadoop镜像生成集群:
# 执行docker-compose启动集群:
$ docker-compose up -d
# 进入主节点容器
$ docker run -d -p 13306:13306 hadoop-master1-1
$ docker exec -it hadoop-master1-1 bash
# 安装sudo
$ apt-get install sudo
# 格式化HDFS
$ ./bin/hdfs namenode -format
3. 集群的启动与关闭
# 启动hadoop集群
$ ./sbin/start-all.sh
# 关闭hadoop集群
$ ./sbin/stop-all.sh
4. Dockerfile配置错误:
# 以下连续五个操作是无法正常运行的,需要拆分为两步或三步
RUN apt-get clean && \
apt-get update --allow-insecure-repositories && \
apt-get upgrade -y --allow-unauthenticated
apt-get install -y wget && \
apt-get install -y ssh
# apt-get install 可能由于未知原因(网络原因)无法正常安装,导致整个镜像生成失败
3. Hive安装
Hive安装参考:https://blog.csdn.net/xiaoxiaowu0419/article/details/124469203
1. Hive本体安装
进入hadoop主节点
$ docker exec -it hadoop-master1-1 bash
# 保持hadoop集群开启
$ ./sbin/start-all.sh
下载hive文件包(清华源和阿里云镜像因为hive升到4,所以没有了,但是我们还有华为云镜像),hive3兼容hadoop3
$ cd /app
$ apt-get install -y curl
$ curl https://mirrors.huaweicloud.com/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz -o ./apache-hive-3.1.3-bin.tar.gz
在当前目录(hive文件)下解包
$ sudo tar -zxvf ./apache-hive-3.1.3-bin.tar.gz -C .
文件重命名
$ sudo mv apache-hive-3.1.3-bin hive
# 如果是非root用户需要改用户权限
$ sudo chown -R [username]:[username] hive
配置环境
# 环境变量
export HIVE_HOME=/app/hive
export PATH=$PATH:$HIVE_HOME/bin
$ apt-get install -y vim
$ vim ~/.bashrc
// 添加上述的环境变量
$ source ~/.bashrc
hive读取配置的顺序依次是,hadoop的配置、hive-default.xml的配置、hive-site.xml的配置。此外,hive-env.sh的配置决定了hive对conf文件的定位,如果hive对配置文件定位失败,则只会使用默认的derby数据库设置。
创建配置文件
$ cd /app/hive/conf
$ cp hive-default.xml.template hive-default.xml
# $ cp hive-env.sh.template hive-env.sh
配置hive与数据库连接
| hive配置的字段 | 详情 |
|---|---|
| javax.jdo.option.ConnectionURL | URL |
| javax.jdo.option.ConnectionDriverName | JDBC,数据库驱动 |
| javax.jdo.option.ConnectionUserName | 用户名 |
| javax.jdo.option.ConnectionPassword | 密码 |
| hive.server2.thrift.port | hiveserver2的开放端口 |
$ vim hive-site.xml
# vim普通模式下,按ggV=G将会格式化整个文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=GMT</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>13306</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NOSASL</value>
</property>
<property>
<name>hive.server2.transport.mode</name>
<value>binary</value>
</property>
</configuration>
$ cp hive-env.sh.template hive-env.sh
$ vim hive-env.sh
# 修改以下参数
export HADOOP_HOME=/app/hadoop
export HIVE_CONF_DIR=/app/hive/conf
export HIVE_AUX_JARS_PATH=/app/hive/lib
2. MySQL安装
安装过程中可能涉及时区设置,选择所在地即可。
$ sudo apt-get install mysql-server -y
下载jdbc安装包及解压至lib下,-L是必需参数否则重定向下载失败
$ curl https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-8.0.21.tar.gz -o ./mysql-connector-java-8.0.21.tar.gz -L
$ sudo tar -zxvf ./mysql-connector-java-8.0.21.tar.gz -C .
$ cp mysql-connector-java-8.0.21/mysql-connector-java-8.0.21.jar /app/hive/lib
启动mysql
$ service mysql start
$ mysql -u root -p
// 输入密码
CREATE DATABASE IF NOT EXISTS hive;
use mysql;
CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive';
# 以下这条语句MySQL8.0以上版本不支持
grant all on *.* to 'hive'@'localhost' IDENTIFIED BY 'hive';
# MySQL8.0,更改密码
ALTER USER 'hive'@'localhost' IDENTIFIED BY 'hive';
# 更改认证插件:从MySQL 5.7开始,默认启用caching_sha2_password,而一些JDBC驱动可能仅支持mysql_native_password.
ALTER USER 'hive'@'localhost' IDENTIFIED WITH mysql_native_password BY 'hive';
# 授予权限
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost';
flush privileges;
# 查询结果
SELECT User, Host FROM mysql.user;
4. Hive初始化
确保hadoop和mysql正在运行
# hadoop
$ /app/hadoop/sbin/start-all.sh
# mysql
$ service mysql start
启动hive
$ cd /app/hive
# 数据库初始化
$ schematool -dbType mysql -initSchema
# 启动hive
$ ./bin/hive
数据初始化成功:
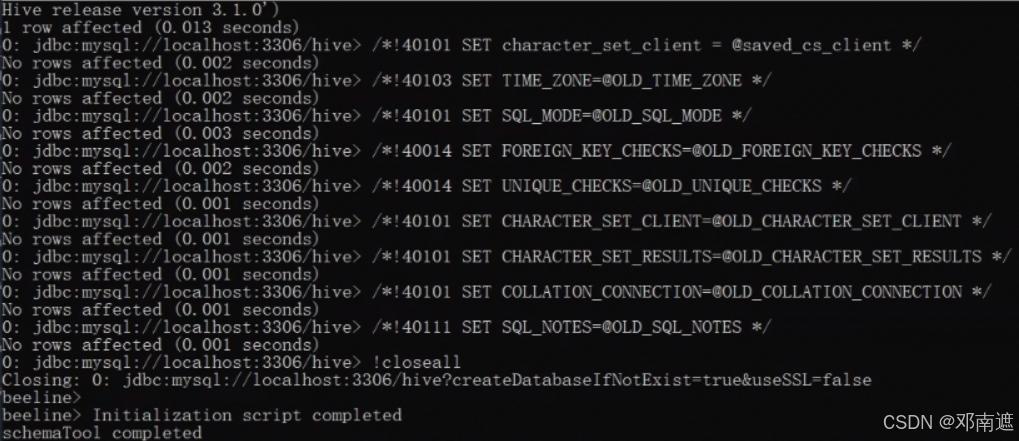
数据库初始化失败的情况:
- hive使用默认derby数据库,而非mysql
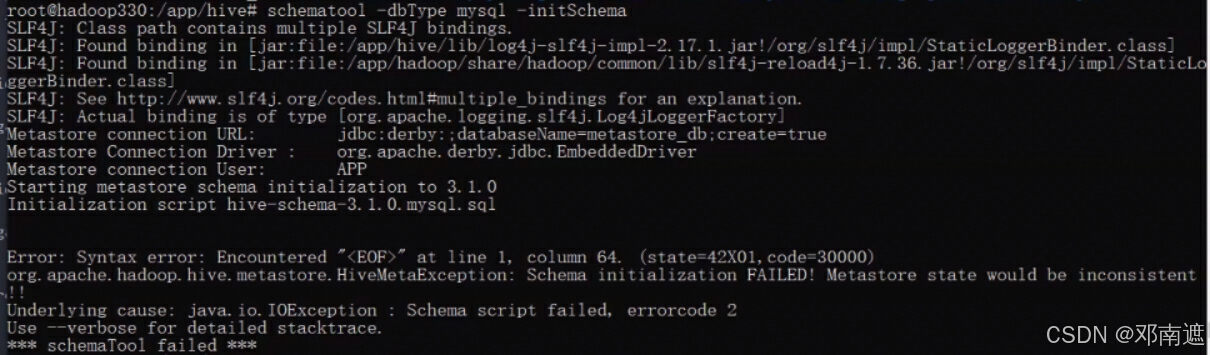
解决方法:回到hive配置,检查hive的环境变量,检测hive-default.xml、hive-site.xml(数据库URl、用户名、密码等)、hive-env.sh
测试hive
show databases;
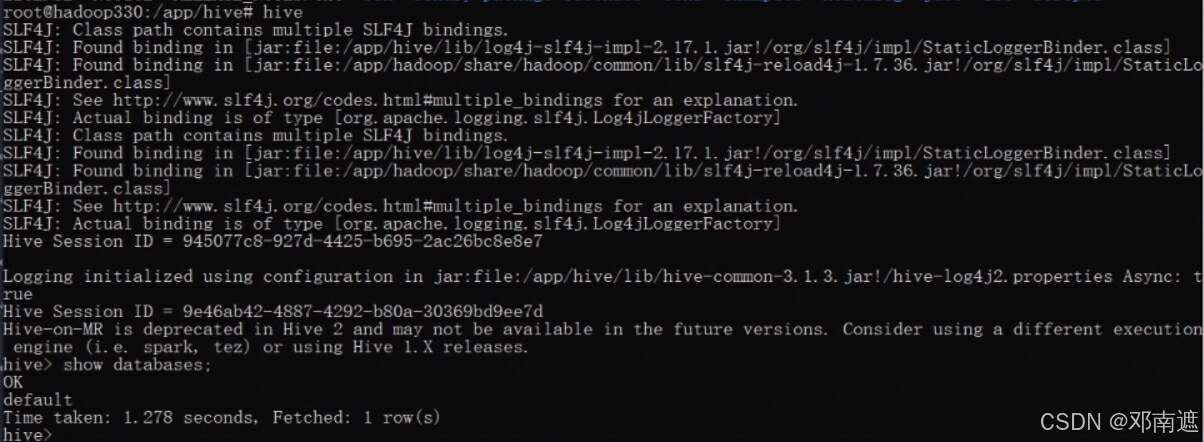
5. Hive远程连接
1. 安装nohup
apt-get install nohup -y
2. 运行嵌入模式HiveServer2
Python 3 使用Hive 总结_python hive
$ nohup hive --service hiveserver2 --hiveconf hive.server2.thrift.bind.host=0.0.0.0 --hiveconf hive.server2.thrift.http.port=13306 &
# 查询nohup进程,可得pid
$ jobs -l
3. python远程连接测试
pip install thrift thrift-sasl PyHive
from pyhive import hive
conn = hive.Connection(
host='localhost',
port=10000,
username='hive',
auth="NOSASL"
)
curs = conn.cursor() # 获取一个游标
sql = 'show databases' # 操作语句
curs.execute(sql) # 执行sql语句
print(curs.fetchall()) # 输出获取结果的所有行
错误1:thrift.transport.TTransport.TTransportException: TSocket read 0 bytes
修改hadoop 配置文件 /app/hive/conf/hive-site.xml,加入如下配置项
参考pyhive访问hive报错:TSocket read 0 bytes
<property>
<name>hive.server2.thrift.port</name>
<value>13306</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NOSASL</value>
</property>
<property>
<name>hive.server2.transport.mode</name>
<value>binary</value>
</property>
错误2: User: root is not allowed to impersonate hive(root)
修改hadoop 配置文件 /app/hadoop/etc/hadoop/core-site.xml,加入如下配置项
Hadoop.proxyuser.root.hosts配置项名称中root部分为报错User:* 中的用户名部分
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
6. Hive操作
Hive 是基于 Hadoop 的一个数据仓库工具。
Hive 的计算基于 Hadoop 实现的一个特别的计算模型 MapReduce,它可以将计算任务分割成多个处理单元,然后分散到一群普通性能的硬件机器上,降低成本并提高水平扩展性。
Hive 的数据存储在 Hadoop 一个分布式文件系统上,即 HDFS。
Hive 作为数仓应用工具,对比 RDBMS(关系型数据库) 有3个“不能”:
- 不能像 RDBMS 一般实时响应,Hive 查询延时大;
- 不能像 RDBMS 做事务型查询,Hive 没有事务机制;
- 难以像 RDBMS 做行级别的变更操作(更新与删除)。
1. 数据库操作
# 创建数据库
create database if not exists myhive;
# 查看数据库基本信息
desc database myhive;
# 修改数据库的部分信息
alter database myhive set dbproperties('createtime'='20210329');
# 强制删除数据库,包含所有库表
drop database myhive cascade;
2. 数据表操作
use myhive;
# 创建表
create table stu(id int,name string);
# 修改表名称
alter table old_table_name rename to new_table_name;
# 增加/修改列信息
# 添加列
alter table stu add columns (uid string, phone string);
# 更新列
alter table stu change column uid phone int;
# 查询表字段及属性
desc stu;
# 删除表至回收站
drop table stu;
3. 表记录操作
use myhive;
# 插入表记录
insert into stu values (1,"zhangsan"),(2,"lisi");
# 查询表记录
select * from stu;
# 查询最新的记录
SELECT * FROM employees WHERE created_at = (SELECT MAX(created_at) FROM employees);
4. 桶表操作
分桶表在查询时可以显著提高性能,特别是对于 JOIN、GROUP BY 和 SORT 操作。Hive 会自动利用分桶信息来优化查询计划。
use myhive;
# 开启hive的桶表功能
set hive.enforce.bucketing=true;
# 设置reduce个数
set mapreduce.job.reduces=3;
# 创建桶表
create table course (c_id string,c_name string) clustered by(c_id) into 3 buckets;

















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









