







浅试lm()
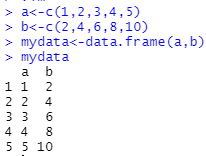
a<-c(1,2,3,4,5)
b<-c(2,4,6,8,10)
mydata<-data.frame(a,b)
myfit<-lm(a~b,mydata)
#myfit<-lm(formula,data)
summary.lm(myfit)

Coefficients部分:
Estimate:估值
Std. Error:标准误差
t value:T值
Pr(>|t|):P值
通过P值与预设的0.05进行比较,来判定对应的解释变量的显著性(检验的原假设是,该系数是否显著为0,P<0.05则拒绝原假设,即对应的变量显著不为0)
截距Intercept=0.144
b<2的负16次方
认为在P为0.05的水平下显著不为0,通过显著性检验
Multiple R-squared:拟合优度
Adjusted R-squared:修正的拟合优度
是指回归方程对样本的拟合程度几何
这里修正的拟合优度=1,拟合程度很好
这个值越高越好,提升拟合优度的方法很多
F-statistic:F统计量,也称为F检验,常常用于判断方程整体的显著性检验
P值=2.2的负16次方<0.05
认为方程在P=0.05的水平上通过显著性检验
总结:
T检验:检验解释变量的显著性
R-squared:查看方程拟合程度
F检验:检验方程整体显著性
警告
In summary.lm(myfit) : essentially perfect fit: summary may be unreliable
msgid “essentially perfect fit: summary may be unreliable”
msgstr “对几乎是完全拟合进行ANOVA F-检验的结果不会可靠”
可能存在的问题数据格式符合但不足以拟合导致结果不够理想
文档示例(暂未精读)
ctl <- c(4.17,5.58,5.18,6.11,4.50,4.61,5.17,4.53,5.33,5.14)
trt <- c(4.81,4.17,4.41,3.59,5.87,3.83,6.03,4.89,4.32,4.69)
group <- gl(2, 10, 20, labels = c("Ctl","Trt"))
weight <- c(ctl, trt)
lm.D9 <- lm(weight ~ group)
lm.D90 <- lm(weight ~ group - 1) # omitting intercept
anova(lm.D9)
summary(lm.D90)
opar <- par(mfrow = c(2,2), oma = c(0, 0, 1.1, 0))
plot(lm.D9, las = 1) # Residuals, Fitted, ...
par(opar)















 3015
3015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









