







文章目录
实验描述
数据集介绍
使用 arnles 软件包中的 Groceries 数据集进行算法演示
该数据集是某一食品杂货店一个月的真实交易数据,每一行数据记录一个交易,每个交易中记录了当次交易的商品名称。
重点程序包
Apriori 关联规则算法借助 arules 中的一系列函数实现
arulesViz 包可以实现关联规则的可视化
关联规则分析
关联规则分析主要包括对频繁数据集的探索、关联规则的建立、查看和分析过程
通过 Apriori 关联规则中 apriori 方法和 Eclat 方法实现为例
思维导图

1.下载并加载arules包
install.packages("arules")
#下载安装 arules 包
library(arules)
#加载 arules 软件包
2.查看Groceries数据集的概要信息
data("Groceries")
#获取数据集 Groceries
summary(Groceries)
#获取数据集 Groceries 数据集的概括信息

3.查看Groceries数据集的前十行的详细信息
inspect(Groceries[1:10])
#观测Groceries数据集的前10行数据

4.生成关联规则
rules0=apriori(Groceries,parameter=list(support=0.001,confidence=0.5))
#生成关联规则 rule0
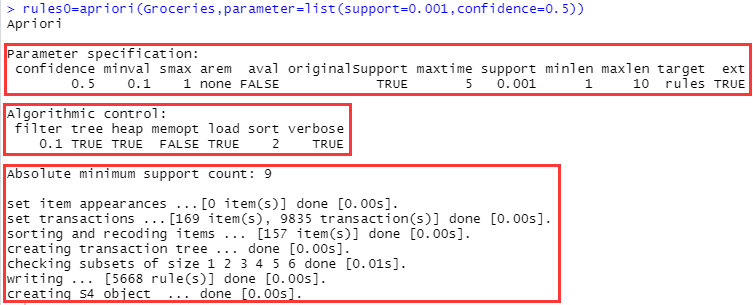
#支持度的最小阈值(minsup)设置为 0.001
#置信度最小阈值(mincon)设为 0.5
#其他参数不进行设定取默认值,并将所得关联规则名记为rules()。
#输出结果中包括指明支持度、置信度最小值的参数详解(parameter specification)部分
#记录算法执行过程中相关参数的算法控制(algorithmic control)部分
#以及 apriori 算法的基本信息和执行细节,如:apriori 函数的版本、各步骤的程序运行时间等
5.查看rules0中生成的关联规则
rules0
#显示rule0中生成关连规则的条数
inspect ( rules0 [ 1:10 ] )
#观测 rule0 中前 10 条规则

#rules()中共包含 5668 条关联规则,若将如此大量的关联规则全部输出是没有意义的。
#并且关联规则的先后顺序 与 可以表明其关联性强度的三个参数值(support、confidence、lift)的取值大小并没有明显关系。
6.对生成规则进行强度控制
6.1 通过支持度、置信度共同控制
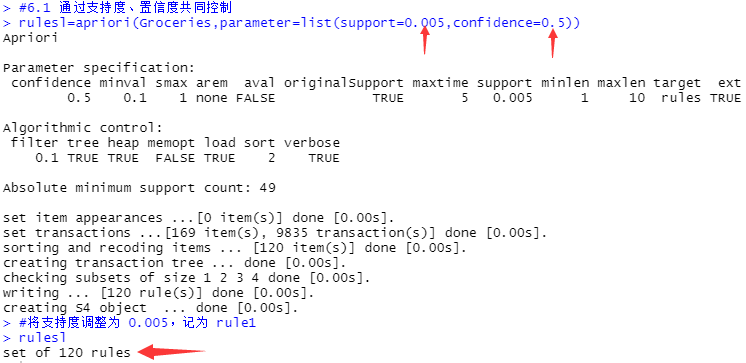
rulesl=apriori(Groceries,parameter=list(support=0.005,confidence=0.5))
#将支持度调整为 0.005,记为 rule1
rulesl
#显示 rule1 生成关连规则的条数
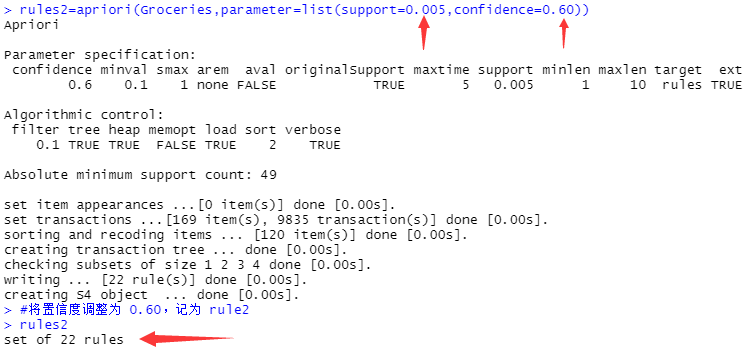
rules2=apriori(Groceries,parameter=list(support=0.005,confidence=0.60))
#将置信度调整为 0.60,记为 rule2
rules2
#显示 rule2 成关连规则的条数
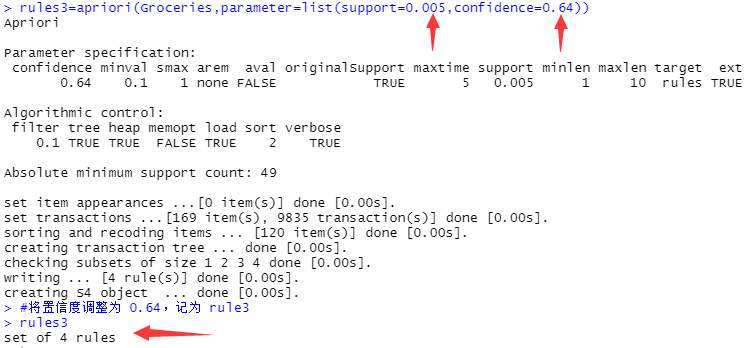
rules3=apriori(Groceries,parameter=list(support=0.005,confidence=0.64))
#将置信度调整为 0.64,记为 rule3
rules3
#显示 rule3 生成关连规则的条数
#6.1节我们可以考虑将支持度与置信度两个指标共同提高来实现:
#将支持度由 0.001 提高至 0.005 时,规则数降为 120 条;
#在此基础调整置信度参数至0.60 后,余下 22 条规则;
#调整置信度参数至0.64 后,仅余下 4 条规则(如下图)
#在两参数共同调整过程中
#如果更注重关联项集在总体中所占的比例,则可以适当地多提高支持度的值
#若是更注重规则本身的可靠性,则可多提高一些置信度值

6.2 主要通过支持度控制
rules.sorted_sup = sort ( rules0, by="support")
#给定置信度阈值为 0.5,按support降序记为 rules.sorted_sup
inspect(rules.sorted_sup [1:5] )
#输出 rules.sorted_sup 前 5 条强关联规则

#5 条强关联规则按照支持度从高至低的顺序排列出来
#这种控制规则强度的方式可以找出支持度最高的若干条规则。对某一指标要求苛刻时,可以优先考虑该方式,且易于控制输出规则的条数。
6.3 主要通过置信度控制
rules.sorted_con = sort ( rules0, by="confidence")
#给定支持度阈值为 0.001,按confidence降序,记为 rules.sorted_con
inspect ( rules.sorted_con [1:5] )
#输出 rules.sorted_con 前 5 条强关联规则

#按照置信度来选出前 5 条强关联规则,由输出结果得到了 5 条置信度高达 100%的关联规则
#比如第一条规则:购买了米和糖的消费者,都购买了全脂牛奶。
6.4 主要通过提升度控制
rules.sorted_lift=sort(rules0, by="lift")
#给定支持度阈值为 0.001,置信度阈值为 0.5,按提升度排序,记为rules.sorted_lift
inspect ( rules.sorted_lift [1:5] )
#输出 rules.sorted_lift 前 5 条强关联规则

#以上输出结果能够清晰地看到强度最高的关联规则为{即食食品,苏打水}→{汉堡肉},其后为{苏打水,爆米花}→{垃圾食品}
#这是一个符合直观猜想的有趣结果,我们甚至可以想象出,形成如此强关联性的购物行为的消费者是一批辛苦工作一周后去超市大采购,打算周末在家好好放松,吃薯片、泡方便面、喝饮料、看电影的上班族。
7.改变输出形式
itemsets_apr=apriori(Groceries,parameter=list(supp=0.001,target="frequent itemsets")
,control=list(sort=-1))
#将 apriori()中的目标参数取设为频繁项集(frequent itemsets)
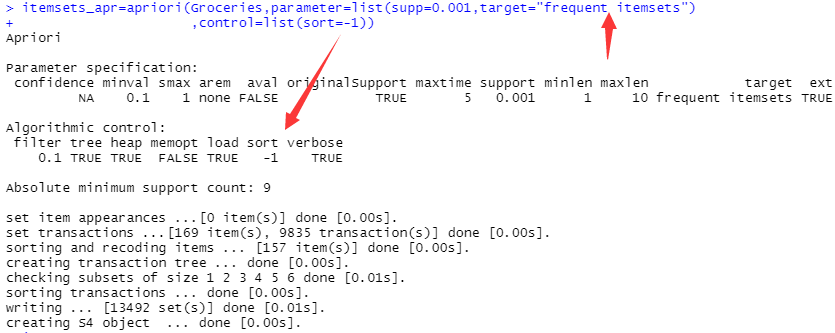
#想知道这个月销量最高的商品、捆绑销售策略在哪些商品簇中作用最显著等,选择输出给定条件下的频繁项集
itemsets_apr
#显示所生成频繁项集的个数
inspect(itemsets_apr[1:5])
#观测前 5 个频繁项集

#生成频繁项集的个数为13492
#以 sort 参数对项集频率进行降序排序后,销量前 5 的商品为全脂牛奶、蔬菜、面包卷、苏打以及酸奶。
8.关联规则的可视化
8.1 加载aruleViz包并生成关联规则
install.packages("arulesViz")
library(arulesViz)
#加载程序包 aruleViz
rules5<-apriori(Groceries,parameter=list(support=0.002,confidence=0.5))
#生成关联规则 rule5
rules5
#显示 rules5 生成关联规则的条数

8.2 初步散点图
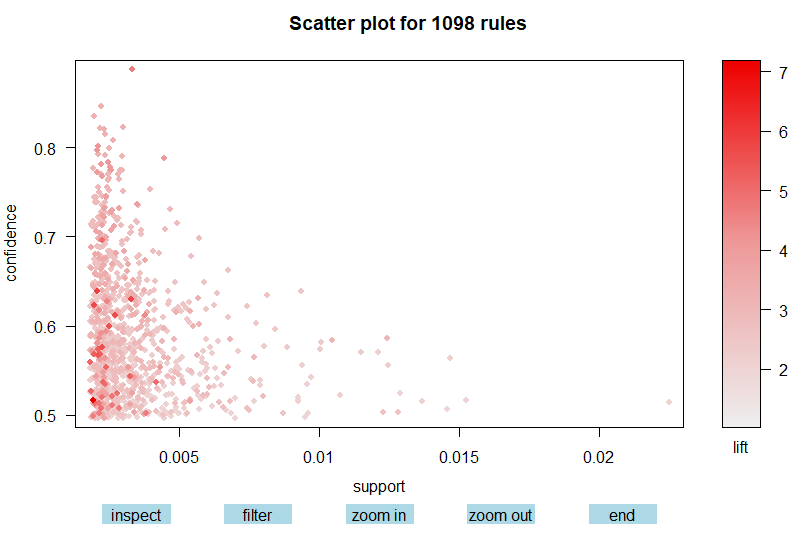
plot(rules5)
#对 rule5 作散点图

#图中每个点对应于相应的支持度和置信度值,且其中关联规则点的颜色深浅由 lift 值的高低决定
#其中一个结论为:提升度较高的关联规则的支持度往往较低,支持度与置信度具有明显反相关性等
#不足在于,并不能具体得知这些规则对应的是哪些商品,及它们的关联强度如何等信息
#而这一缺陷可通过互动参数(interactive)的设置来弥补
8.3 更改互动参数后的散点图
plot(rules5,interactive = TRUE)
#绘制互动散点图
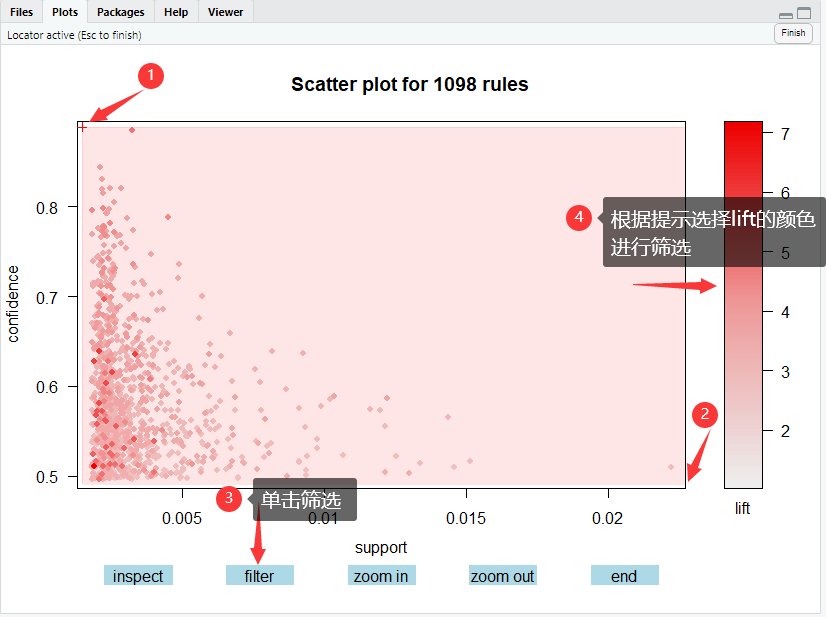
8.4 单击“filter”过滤按钮后的散点图
鼠标变成“+”
→
\rightarrow
→选定数据区域
→
\rightarrow
→单击“filter”进行筛选
→
\rightarrow
→选择需要查看的lift对应的最小颜色
→
\rightarrow
→单击“end”结束互动
即可将小于单击处 lift 值的关联规则点都过滤掉

8.5 Two-key图
plot(rules5,shading = "order",control = list(main="Two-key plot"))
#绘制 Two-key 散点图
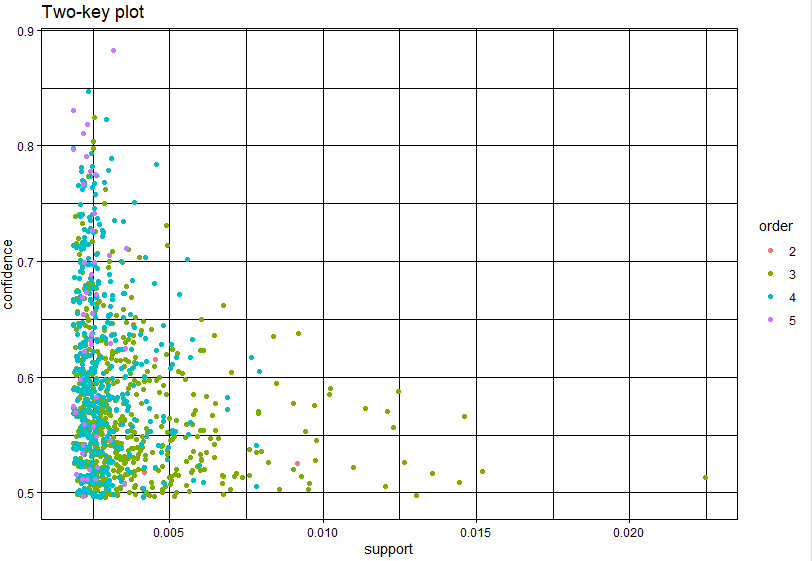
#将shading 参数设置为“order”来绘制出一种特殊的散点图—Two-key图
#横纵轴依然为支持度和置信度,而颜色深浅则表示其所代表的关联规则中含有商品的多少
#商品种类越多,点的颜色越深
8.6 图形类型为“grouped”生成图
plot(rules5,method = "grouped")
#对 rules5 作分组图
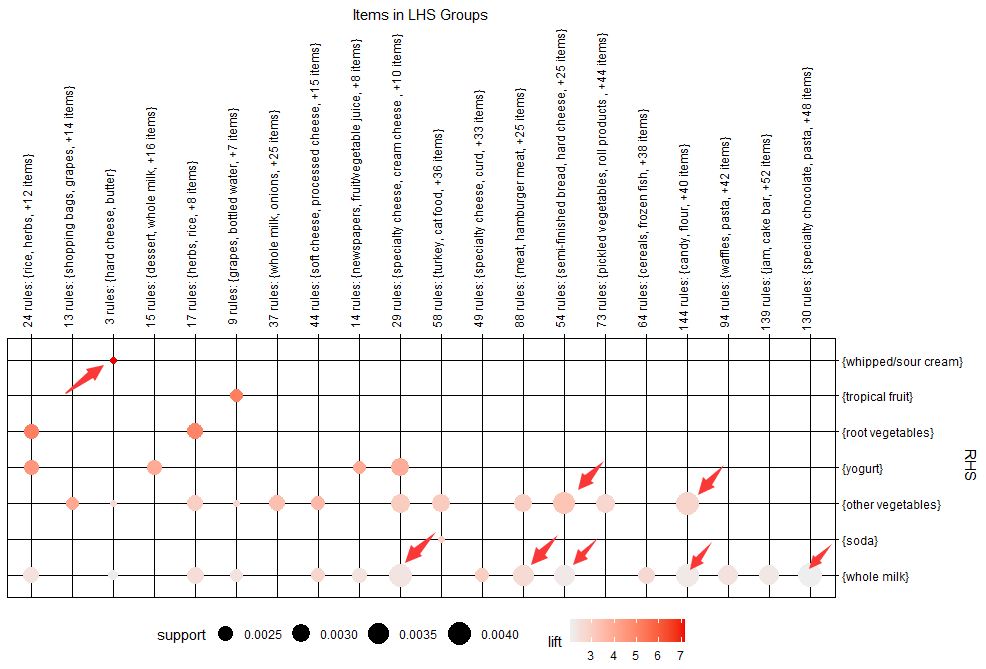
#按照 lift 参数来看,关联性最强(圆点颜色最深)的两种商品为硬奶酪黄油(hard cheese,butter)与生/酸奶油(whipped/sourcream);
#以 support 参数来看(圆点尺寸最大)关联性最强















 6293
6293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









