






 本文介绍了如何使用Selenium和requests库实现爬取Bing搜索结果中的小企鹅图片,包括页面滚动、处理iframe、定位图片并下载的过程。
本文介绍了如何使用Selenium和requests库实现爬取Bing搜索结果中的小企鹅图片,包括页面滚动、处理iframe、定位图片并下载的过程。
前言
本章,响应群友需求,搞一搞小企鹅的图
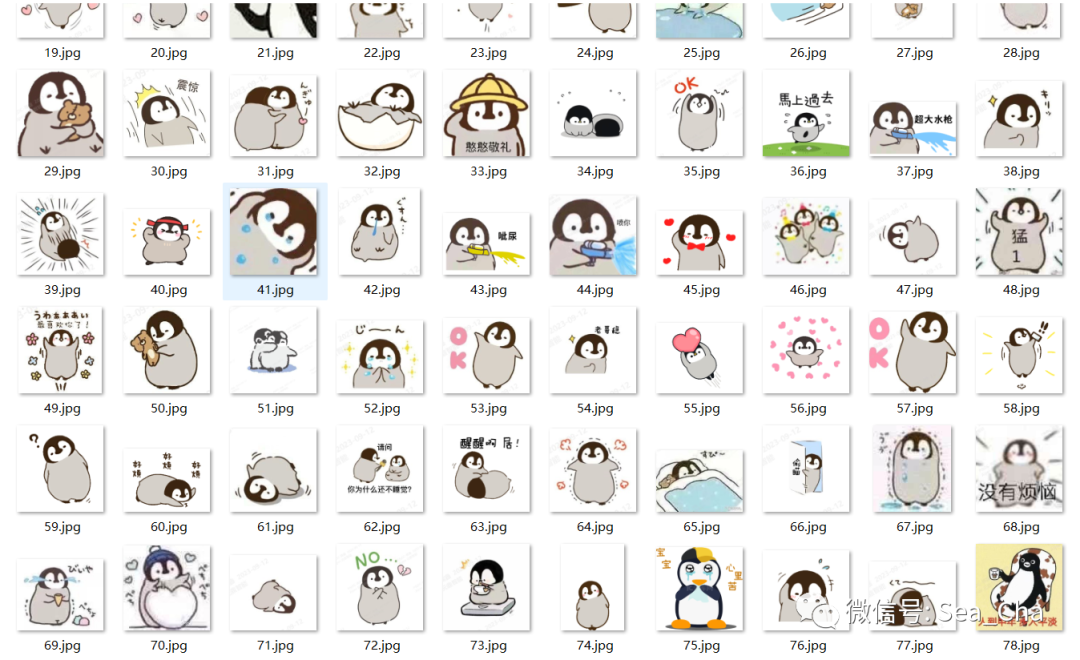
看起来嘎嘎可爱,不小心就爬完了它。一起来看看代码,文末附源码地址。
首先,你需要百度,找到一个有很多小企鹅图的网站.
我找了半天,也就找到个这个:
https://cn.bing.com/images/search?q=%E5%B0%8F%E4%BC%81%E9%B9%85%E8%A1%A8%E6%83%85%E5%8C%85&qpvt=%E5%B0%8F%E4%BC%81%E9%B9%85%E8%A1%A8%E6%83%85%E5%8C%85&first=1不过问题不大,不影响我们分析,并且获取它啊。
技术栈
本章使用selenium+requests来获取。为什么使用selenium,因为昨晚上有粉丝问了selenium相关的问题,所以直接上手吧。
第一步-导包并打开网址
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
fox = webdriver.Firefox()
fox.get(
"https://cn.bing.com/images/search?q=%E5%B0%8F%E4%BC%81%E9%B9%85%E8%A1%A8%E6%83%85%E5%8C%85&qpvt=%E5%B0%8F%E4%BC%81%E9%B9%85%E8%A1%A8%E6%83%85%E5%8C%85&first=1")因为我是写完后才写的文章,所以提前知道了需要哪些包,不必在意为什么我一下子知道需要哪些包。
第二步-分析网址情况
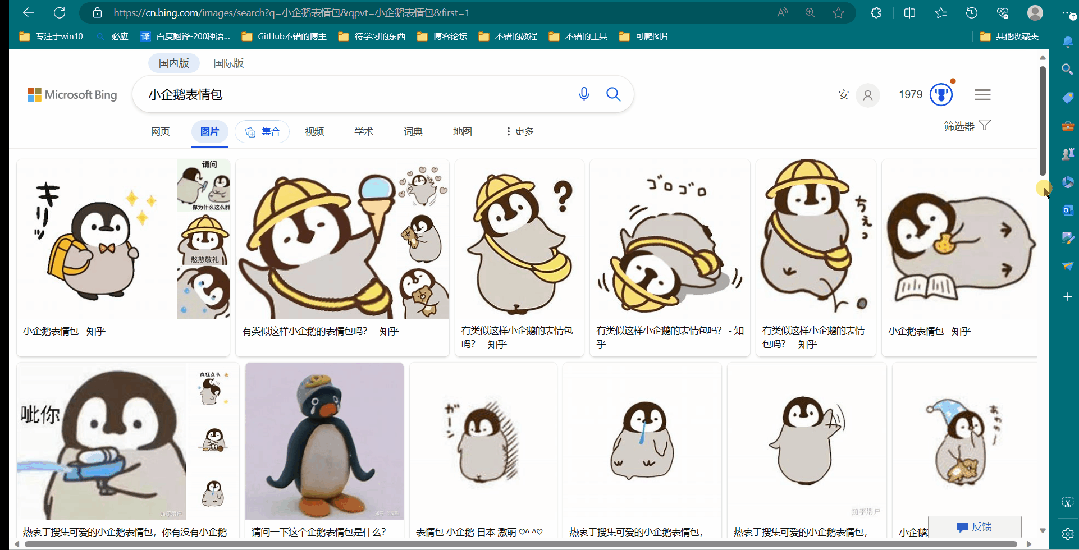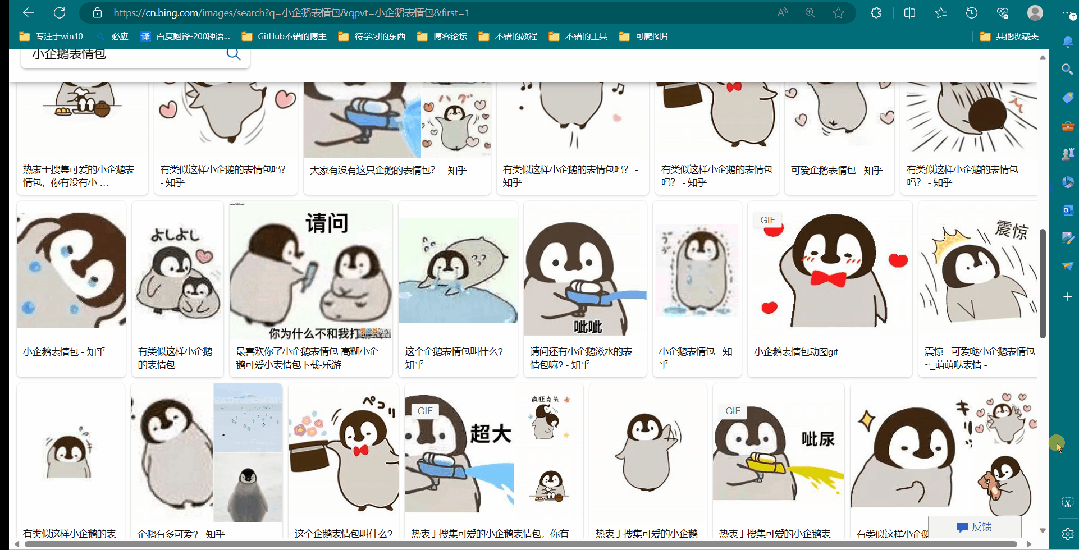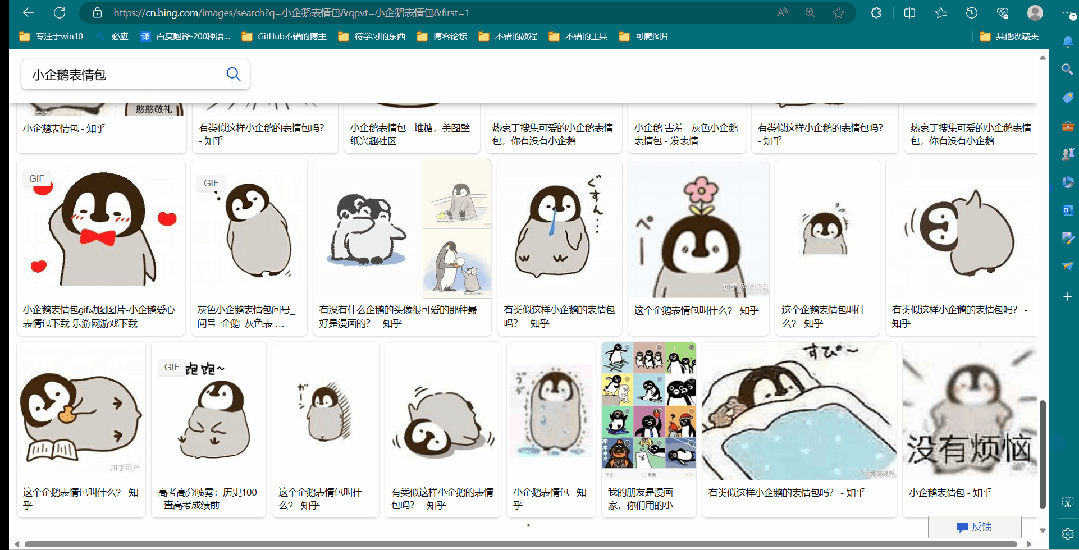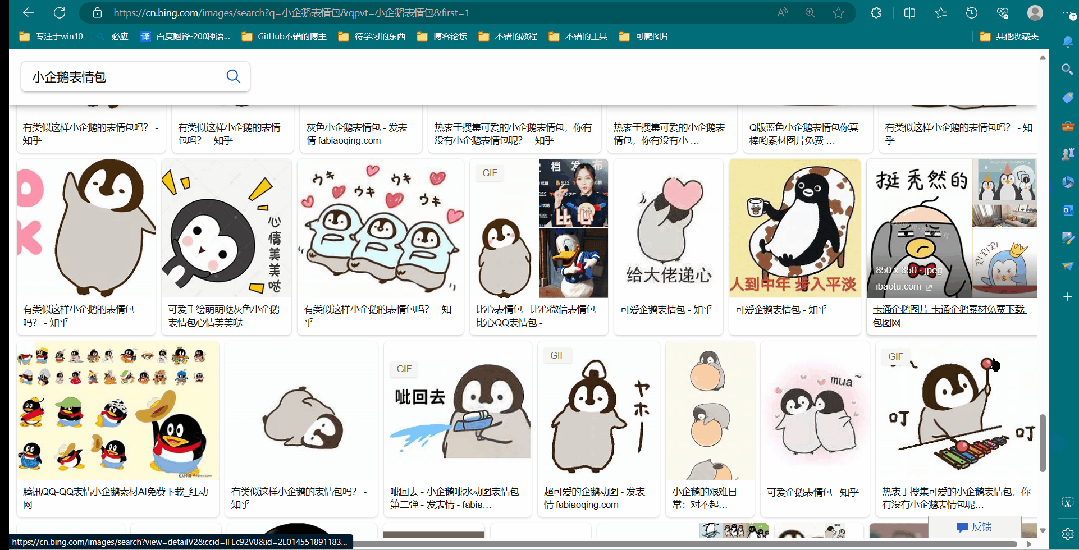
如动图所示,下拉过程中,会不断的刷新界面,所以我们第二步需要做的就是解决掉界面刷新情况,如何下拉,并一直到底部。
怎么做?看代码
while True:
down = "window.scrollTo(0, document.body.scrollHeight)"
fox.execute_script(down)
time.sleep(2.5)
# 使用 JavaScript 判断是否已经滚动到底部
is_bottom = fox.execute_script(
'return (window.innerHeight + window.scrollY) >= document.body.offsetHeight;'
)
if is_bottom:
break先下拉,等待2.5S时间,用于加载DOM,避免误操作。然后判断滚动条高度,直到高度先等,退出循环。
第四步-定位图片
上述步骤DOM已经加载完毕后,定位第一张图,点击打开它。
点击进去后,再看:
可以看到src出来了,那么接下来就是获取这个src了,同样,需要分析一下HTML。最后发现,在这个界面的上层有一个iframe框架。
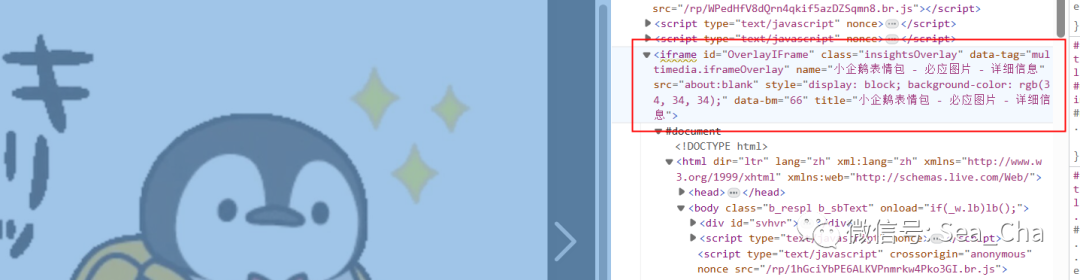
接下来要做的就是定位这个iframe,切换进去,然后定位img,获取属性src,一气呵成
Frame = fox.find_element(By.XPATH, "//*[@id='OverlayIFrame']")
fox.switch_to.frame(Frame)
time.sleep(2)
num = 0
while True:
srcs = fox.find_elements(By.XPATH, "//*[@class='imgContainer']/img")[0]
src_ = srcs.get_attribute("src")用到while是因为有很多这样的src需要获取,所以,知道有很多个src需要获取,那么如何跳转到下一张图片呢?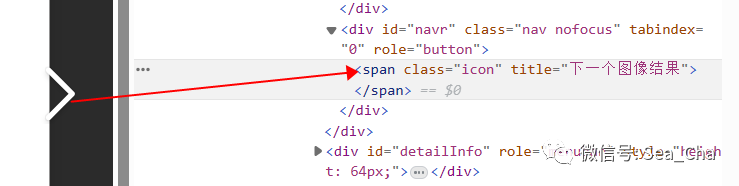 没错,就是它了,定位它,在获取到本章图片的src后,并发起请求,获取图片信息并下载,就可以点击下一张了,并重复这样的操作,直到异常,没有图片了,我们就退出。
没错,就是它了,定位它,在获取到本章图片的src后,并发起请求,获取图片信息并下载,就可以点击下一张了,并重复这样的操作,直到异常,没有图片了,我们就退出。
res = requests.get(src_)
with open(f"{str(num)}.jpg", "wb") as w:
w.write(res.content)
num += 1
try:
fox.find_element(By.XPATH,'//div[@id="navr"]/span').click()
except:
print("结束")
fox.quit()因为没有反爬,所以写的比较简单,图片数量不多,下载速度也还行,没有写入多线程了,
最后:代码地址:文件名:小企鹅.py
斗图 · 清安无别事/爬虫案例 - 码云 - 开源中国 (gitee.com)


















 5005
5005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











