







一、总体执行步骤
1、下载Tesseract引擎安装(路径用于配置环境变量)
2、下载Tessdata语言库,放在引擎安装的tessdata目录下
3、导入maven依赖
4、编写代码
二、步骤细分:
1、官网(可忽略)
官网地址:UB Mannheim: Digitale Bibliothek
项目地址:https://github.com/tesseract-ocr/tesseract/wiki

2、Tesseract引擎安装包下载地址(安装目录用于配置环境变量)
对应版本: https://digi.bib.uni-mannheim.de/tesseract/
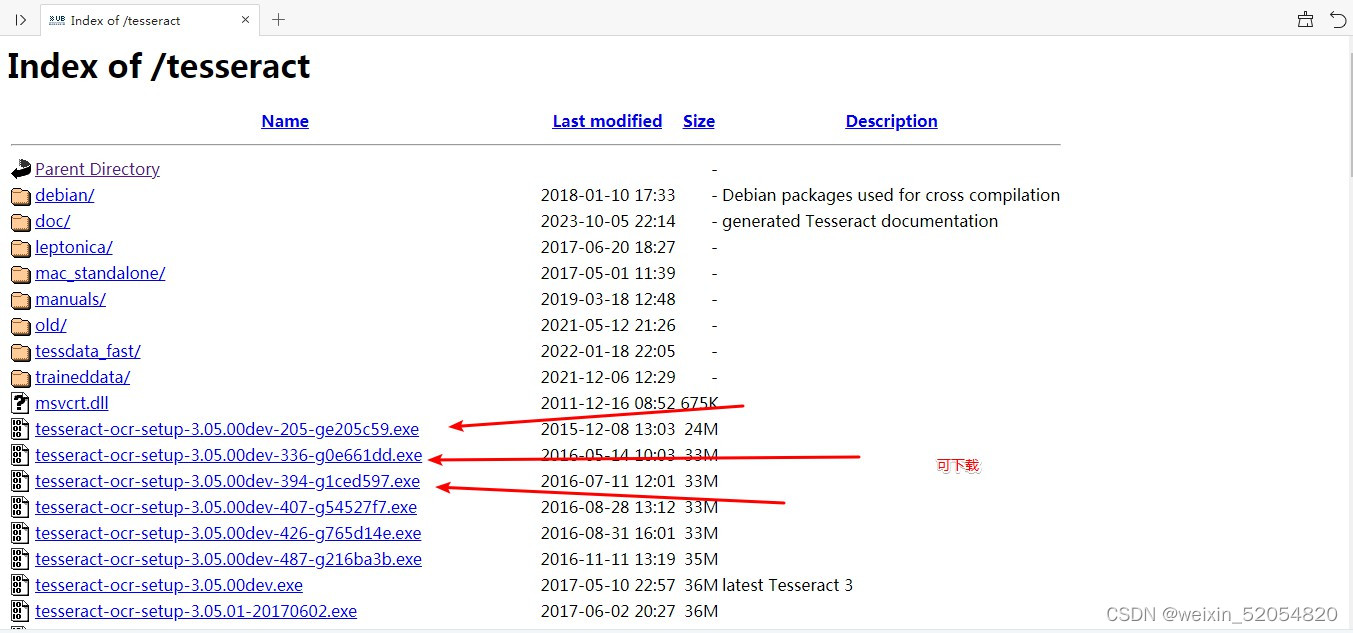
3、配置环境变量
使用Tesseract引擎安装的根目录地址;
打开命令终端,输入:tesseract -v,可以看到版本信息即安装完成;
 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









