







作为程序员,主要的工作任务就是curd,和数据库打交道是无可避免的。掌握一些数据库的优化技巧是非常有必要的
一、减少数据访问
1、使用索引
索引的原理是利用额外的空间建立了一个平衡的搜索树,大大缩短了查询的时间,使得查询的时间复杂度从O(n)降低到O(log(n)),但是在进行插入、修改、删除操作的时候,同时要对搜索树进行相对应的维护,需要带来额外的开销

例如上面的搜索树,需要查询6的时候,步骤如下
(1)6和10比较,10大,那么往左边下去,到4
(2)6和4比较,6大,那么往右边下去,到6
(3)6和6比较,相等,那么6就是想要查询的数据
如果没有索引,那么每个元素都要比较一下才可以查出目标数据,这点可以比喻二分查找元素的案例
上面的搜索树只是一个类比,mysql的索引使用的是b+树,思想和上面的例子是差不多的,只不过b+树是多叉平衡树,并且数据存在叶子节点,这样可以方便查找相邻的元素
使用索引需要注意的是,只有当索引符合一定条件的时候索引才会生效,因为索引并不能解决100%的问题,例如两个字段id、name,id列建立了一个索引,假如判断条件为where id = name,每一行的name是会变化的,那么就无法使用索引,必须每一行都进行判断才可以得到结果,并不是数据库设计者故意不让索引生效的,而是索引本身不能解决这个问题
| 查询条件 | 不能使用索引原因 |
|---|---|
| INDEX_COLUMN <> ? | 不等于操作不能使用索引 |
| INDEX_COLUMN not in (?,?,…,?) | 不等于操作不能使用索引 |
| function(INDEX_COLUMN) = ? | 经过普通运算或函数运算后的索引字段不能使用索引 |
| INDEX_COLUMN || ‘a’ = ? | 经过普通运算或函数运算后的索引字段不能使用索引 |
| INDEX_COLUMN like ‘%’||? | 含前导模糊查询的Like语法不能使用索引 |
| INDEX_COLUMN like ‘%’||?||‘%’ | 含前导模糊查询的Like语法不能使用索引 |
| INDEX_COLUMN is null | B-TREE索引里不保存字段为NULL值记录,因此IS NULL不能使用索引 |
| CHAR_INDEX_COLUMN=12345 | Oracle在做数值比较时需要将两边的数据转换成同一种数据类型,如果两边数据类型不同时会对字段值隐式转换,相当于加了一层函数处理,所以不能使用索引。 |
| a.INDEX_COLUMN=a.COLUMN_1 | 给索引查询的值应是已知数据,不能是未知字段值。 |
在使用联合索引还有个最左匹配原则,例如有联合索引a、b、c,a没生效,那么b和c就无法生效,反过来,c如果要生效,那么a、b必须生效
2、分库分表
分库分表又有垂直划分和水平划分两种,先看一下定义:
(1)垂直分库
一般是为了解耦,将一个整体划分为多个部分,同时这样做也可以平衡数据库的压力,每个数据库管理一部分数据
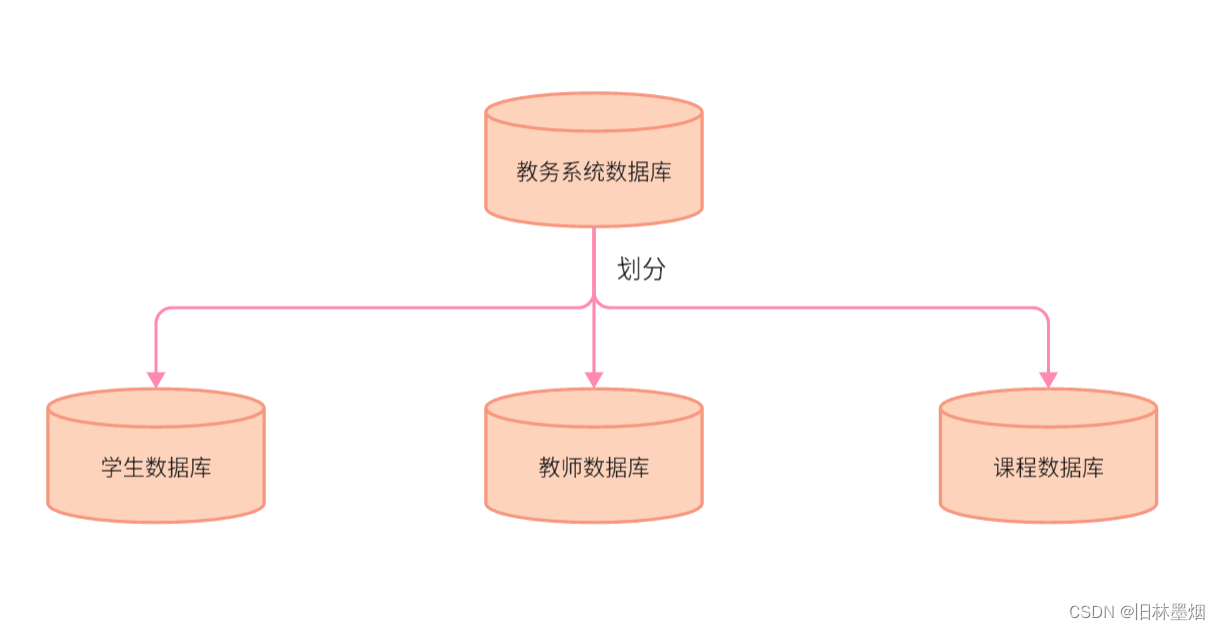
(2)水平分库
一般用于解决单个数据库压力过大的问题,例如一百万个人同时访问学生数据库,会导致数据库瘫痪,那么可以考虑水平分库,下面举一个例子进行理解
例如下面将学生数据库分为了3个,那么可以根据学生的id去分配学生数据,例如常见的mod法,假如id为10,10%3=0,那么这个学生的数据库存在第一个数据库中,反过来看,数据库1存放学生id为0,3、6、9…的学生数据,数据2存放的是1、4、7、10…的学生数据,数据3存放的是2、5、8、11…的学生数据
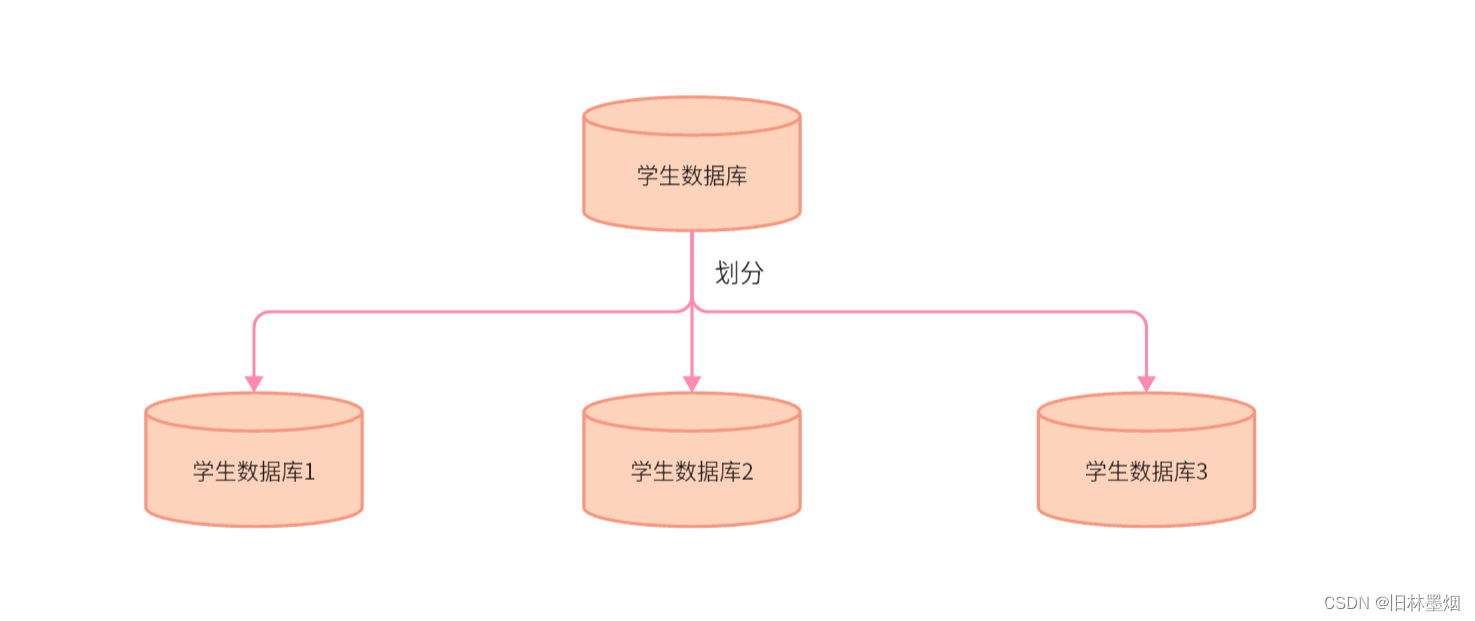
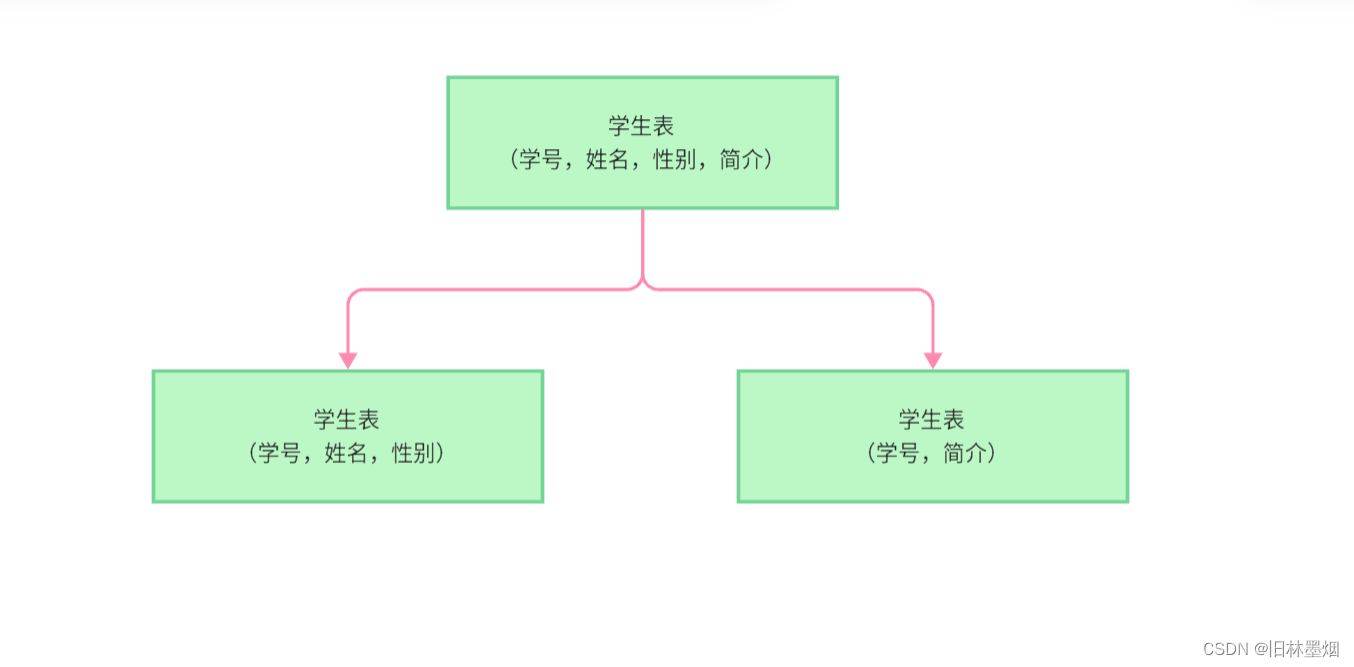
(3)垂直分表
把存储数据多的或者不常用的字段分离出来,可以提高查询的速度,因为在查找的时候不用额外扫描不需要的数据,例如下面,简介可以储存1000个字,那么在查找的时候是相对耗时的,即使我们没有去查该字段的数据,分离之后,查找学生姓名的时候就不需要扫描简介字段了
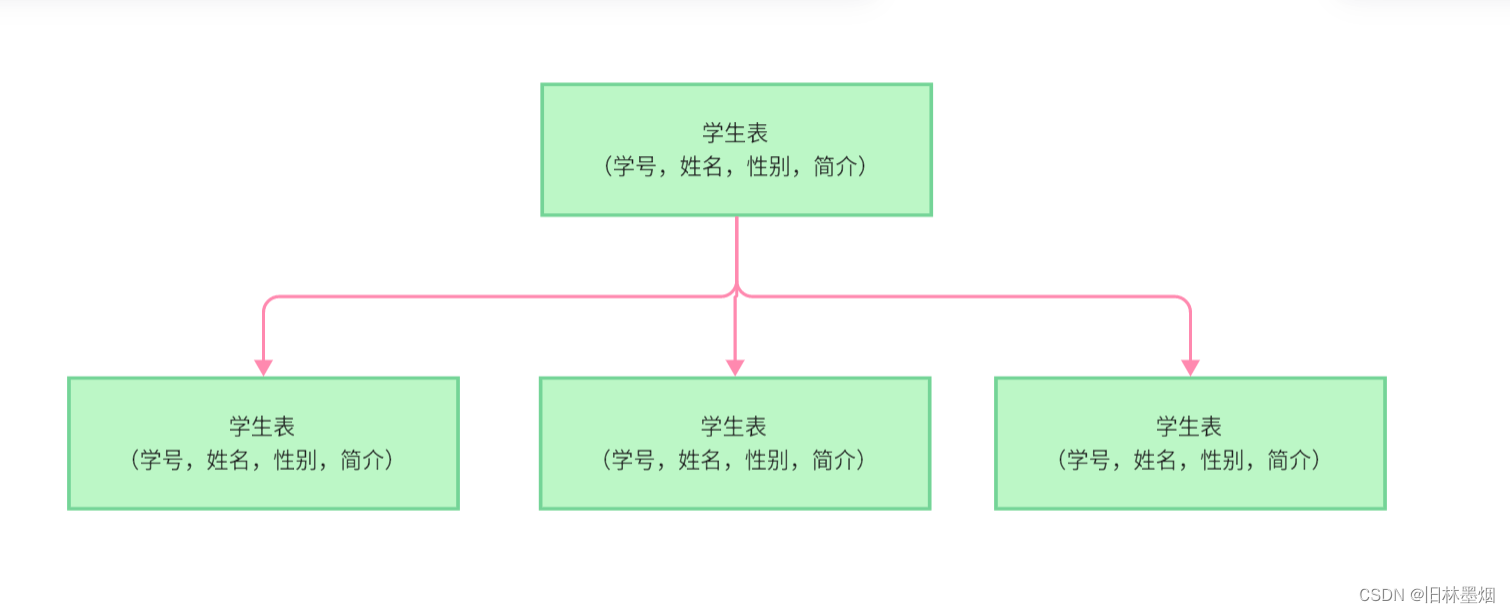
(4)水平分表
水平分表和水平分库是类似的,单个表的数据量过大,那么查询的时间就会长,如果建立了索引,对插入、修改和删除操作就会有严重的影响
水平划分数据可以解决这个问题,可以按一定的逻辑去划分数据,不一定使用mod法,例如下面的例子:
由于业务需求,可能需要对各个年级的学生数据进行维护,例如划分课程等等,就可以按学生年级、专业这些相关字段去划分
(5)总结
水平分库、垂直分表、水平分表都使用了减少数据访问的原理对数据库操作做了优化,而垂直分库可解耦合,使得数据库变得更加灵活易维护
二、返回更少的数据
数据的传输是需要花费时间的,传输越多的数据,那么花费的时间就越多
(1)分页
一般来说,展示给用户的数据都会有分页的,那么查询的时候可以根据一些推荐算法对数据进行排序,用户需要更多数据的时候再查需要的数据,而不是将查到的数据一下子全部发送到客户端
(2)只返回需要的字段
通过去除不必要的返回字段可以提高性能,例:
调整前:select * from product where company_id=?;
调整后:select id,name from product where company_id=?;
优点:
1、减少数据在网络上传输开销
2、减少服务器数据处理开销
3、减少客户端内存占用
4、字段变更时提前发现问题,减少程序BUG
5、如果访问的所有字段刚好在一个索引里面,则可以使用纯索引访问提高性能。
缺点:增加编码工作量
三、减少交互次数
1、batch DML
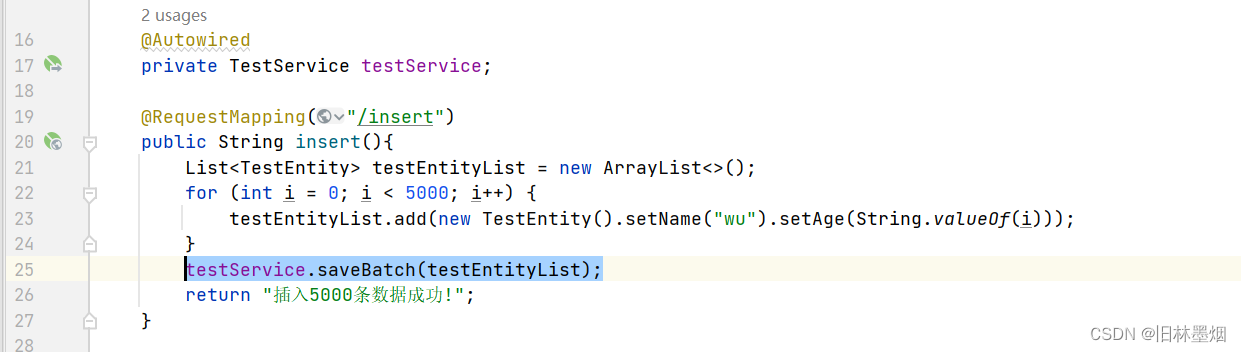
如果插入1000条数据
通过for循环一条一条进行操作,那么需要和数据库建立1000次连
假如每次插入10条数据,那么需要建立100次连接接
假如每次插入100条数据,那么需要建立10次连接
那么是不是每次插入的数据量越多越好呢?不是的,批量插入的时候需要建立临时表,批量插入的数据越多,那么占用的空间越大,有内存溢出的风险
总的来说,适当地调节插入、修改、删除的批量操作的数量,可以降低数据库的连接次数,减少了网络通信使用的时间
mybatis plus也提供了批量操作的接口,默认单次处理的数据为1000条
2、In List
尽量不循环查询数据库,可以使用in条件批量查询,如果需要分离数据,可以使用程序分离,这样不仅减低数据库的连接次数,而且在没有索引的情况下降低了扫描数据库的次数
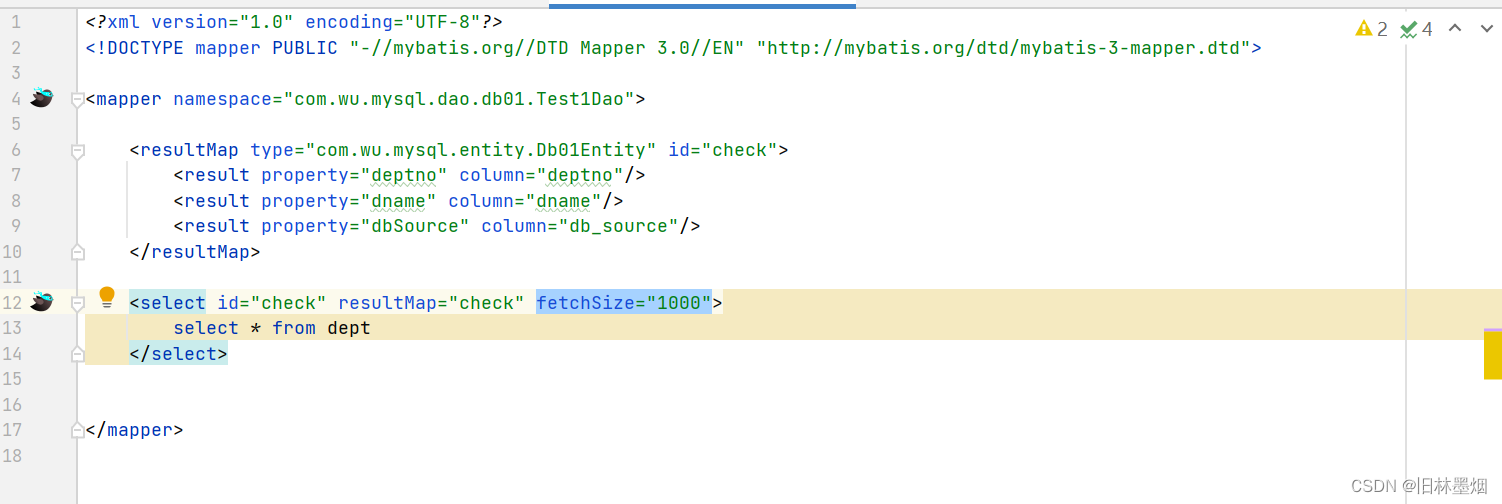
3、设置Fetch Size
数据查询出来需要从数据库传输到实体类中存储起来,这中间传输的时候需要建立连接通道,传输的速率有通道的大小决定,通道的大小可以通过调整Fetch Size调节,如果通道太小,传输数据就会很慢,如果过大,会浪费空间,有内存溢出的风险。所以调整Fetch Size优化性能的时候需要对数据量进行评估
mybatis可以使用fetchSize属性调节大小,网络上大家都说fetchSize设置在40-100比较合适,oracle默认是10,所以取10000条数据的时候就需要花费10秒钟,需要适当提高fetchSize来提高传输速度
4、使用存储过程
使用存储过程可以在一次连接做许多复杂的逻辑操作,查出的数据直接在数据库中处理,由此可以去掉连接和传输的时间花销,例如将一个表的数据处理后存到另一个表,传统的做法是取出数据到客户端,处理后再用insert语句插入到另一个表中,而存储过程却可以一步到位,直接取数据,处理,插入。最大的优点就是减少了数据在网络上传输开销
存储过程的收益并没有很大,又不容易维护,所以在实际的生产中很少使用,定时性的ETL任务或报表统计函数使用得比较多
















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











